SESSION #1, Breakout #1
Session Title: Wallet + Credential Interoperability
Session Convener: Stefan Liström (SUNET)
Session Notes Taker(s): Zacharias + Gyöngyi
Time keeper: Nicole
Tags / links to resources / technology discussed, related to this session:
- wwwallet.org
- MIT Digital Credentials Consortium (MIT) blog post from Rob Schwartz about selecting OpenID Federation for their trust framework
- Interop challenges example: Pull request commentary around DIDs/OIDF in client ID prefixes/schemes in OID4VP
- SURF has the NPulse project looking at this.
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
“Interoperability is going to be the biggest challenge with/between digital identity wallets and our use cases.”
What are the important aspects for our community for interoperability?
We’re talking about digital identity wallets, but its not the only wallet use case, but that’s what we are talking about today (Note: see background section a the end for an indicative overview of non-identity credentials). Not only the EU wallet.
Framing:
Either to take the wallet perspective:
- – digital identity wallet
- – EUDI wallet
To simplify the ecosystem the three components are:
- Issuer / Provider (something to tell someone about something or someone / Natural person / Legal Person)
- Wallet can be a mobile app or application and receives a credential. The user wants to share a credential to a Verifier (Relying Party)
- Credentials
The three components are
- – Issuer (aka provider)
- Something that says something about someone to a wallet.
- Could be a mobile app or something else.
- The user then shares the issued thing to a service.
- – Verifier (aka Relying Party)
- From the EUDI wallet standards are difficult to agree / apply.
- – Issuer (aka provider)
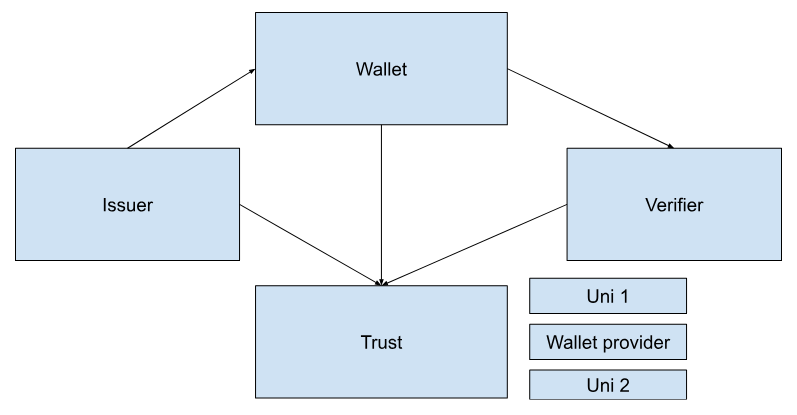
- From the EUDI wallet standards are difficult to agree / apply.

Interoperability (Two ways looking at it) | |||
| Organisational | Users & Services | ||
| Legal | Organisational & Processes | ||
| Semantic | Application & Information | ||
| Technical | Standards & Technology | ||
| Governance & Legislation | |||
From the perspective to looking at interoperability is “Student mobility”.
Concern about the larger standards community closing the door. There are some purists for OIDF and IETF not happy with the thought using (DID, DID credentials), they want to use OIDF as the trust bone for that. It is about not allowing changes need to be made for OID specification.
What about adapting the solution to make the landscape first?
In the US a lot of funding went into use of DIDCOMM. They don’t necessarily use DIDs for trust and instead they want to use OIDF. They (Digital Credentials Consortium at MIT) currently have DID issuers that they want to add to OIDF.
OpenID4VCI and OpenID4VP. Concern to have standardised credentials between Europe and the US: using DID and entity IDs in the credential specifications instead of URLs.
What about the Research and Education community already adapting OID.
W3C (Taiwan) presented their wallet system.
Concern because of the geopolitical developments to have not “open” systems for the wallet developments.
The EUDI wallet (national wallets issued by governments for their citizens) will rely on…
Other trust infrastructures could be set up for OIDF for global higher education and research. There can be different type of trust infrastructures for different sectors.
The wallet cannot participate in the trust infrastructure only the wallet providers (credentials) can. The issuers can. The wallet could act as “proxy infrastructure”.
The issuers could be part of different trust infrastructures (see REFEDS PORE Working group (link 1) slide from Davide (link needed)).
How can the EUDI wallet benefit our community?
Super impose educational & research credentials.
Follow the market for the technological development for education & research.
Identity linked to the educational credential.
Interoperability
- • Organisational
- • Legal
- Legal is important because we are doing things between organisations.
- • Legal
- • Semantic
- How can we understand each other? They are putting something in the wallet, how do I understand the information in a machine readable way.
- • Semantic
- • Technical
- Which kind of draft or standards are you using
- In the EUDI wallet a lot of different standards are being proposed (in many cases standards that are not complete, still being developed)
- • Technical
How a flow or a whole process might go through an organisation:
- • Users & services
- Student information system, for example
- • Users & services
- • Organisation & processes
- In an organisation you might have different processes and the information might go through different parts of the organisation by different people
- Who’s actually doing what?
- • Organisation & processes
- • Application & Information
- Attribute aspects, what kind of information are we actually using in the credential
- • Application & Information
- • Standards & Technology
- What kind of standards are we using, how are they implemented, how can we explain to others so they understand what we are doing
- • Standards & Technology
- • Governance & Legislation
- What are the laws
- What are the differences between laws in different countries that we have to abide by
- • Governance & Legislation
Student mobility is a good use case to think about, that this could help.
Discussion:
– There is a worry about interoperability
– DID’s are being used in the U.S. and there is a gravitational pull in the U.S. about, a lot of money has been invested
– What would it take for R&E to adapt to the DID
– The interoperability between for example U.S. and E.U.
– The contention point is between DID’s and URL’s
– Taiwan wanted to have interoperability, and that’s an example of something wanting to cooprorate, but others are wanting to have closed borders
– Let’s add the Trust box in the echo system – from a credential pooint of view the trust is expressed in DIDcom or OpenID4VC/VP – the trust in the European Commission they are introducing “trusted lists”
– DIDcom has no trust, and they want to add the trust backbone of OpenID fed
– DID issuers
– “There is something about the boundries” but we also saw this with EOSC “for now its only for european users” – you can invite someone else but effectively the system is built for European Citizens
– The wallet is a great thing for push eID (reincarnation of eIDAS to bring up the adoption), but what happens for the wallet for education, who will be able to issue credentials? Anybody, federations?
– The closedness (can be solved) eIDAS regulation says every nation will have to go through a certification process to have a EUDI wallet for their country – that’s gonna close out stuff, and make certain things non-interoperable – there are other trust infrastructures than just the EU, we could set up an openid federation that could be for higher education and research that is separate from the EU or US or Swiss or NZ/Australia or something else
– This person is who they say they are, and they have a diploma that someone else can read even if they’re not part of the EU trusted list
– You could have two wallets (nation wallet and an educational wallet) or one wallet that could trust both trust ecosystems
– EUDI is called an identity wallet but its also being called upon to be used for business and education and travel, most international agreements are much broader, in many cases include Switzerland Norway and the U.K., if I issue a diploma I issue it to you – I shouldn’t care of what ecosystem it could be used, the user has to carry it, maybe to China, there needs to be a trust ecosystem, that can survive
– European Commission want a lot of things in the wallet but they are being very limiting of how the wallet can be used and where
– What I hope we can ensure – we will be able to introduce the “slack” needed to make this actually work
– If the trust list contains the EU government and America government and Asia government is that enough? – No, its not enough to just have the trust lists, the semantics.
– I don’t understand the difference between the wallet and the trust infrastructure, what would it mean for a wallet to be able to work in two trust infrastructures? – The credential is the thing that needs to be interoperable
– One of the ideas is that the “wallet” doesn’t exists within the trust infrastructure, the wallet provider does, a diploma is issued by university 1, Apple is the wallet provider, the student is bringing the diploma to university 2 that then checks with the wallet and issuer to see if they trust the diploma
– For us as a sector we should not focus on the EUDI wallet, there will be more than one “trust boxes” , hopefully as few as possible, but to cover a broad use case pickup
– We may not colude with national identity schemes and driver licenses they will have special schemes for registering the id, they need to do that, but it shouldn’t limit us from reusing the infrastructure to superimpose other purposes
– Educational credential part only need to have a verification part from the government wallet – there is a way to decouple our use case from the government wallet, our eco system could remain more open – I don’t think I know right now a way to have a way to have trust between different -> issuing from one wallet to another -> it becomes more complex because it goes into the idea of self sovereign identity
– How is identity linking couple with wallets, how is the diploma connected to the identity, your diploma provider will probably have a different identity about the student than the government -> identity is linked to your diploma but the diploma is not linked to you
– The way seems to be done now is that you as end user when you inititate the wallet at least int eh eudi you need to show that you have control of this walet you will send your pid to the issuer and they will somehow take something publica key to the issuer and the issuer can add that public key to the credential and sign it and sendit to the wallet – when the verifier asks for your pid and your diploma they can actually cryptographically ensure that the pid and the diploma is coming from the same wallet and that the it is actually issued to you
[Regarding current legislation discussions around eIDAS2: see e.g. the input from a German civilian digital rights organisation eIDAS: Amendments to the Implementing Acts (batch 2, rev6) – epicenter.works]
[Some afterthoughts (Peter Leijnse, SURF): actually not the standards or technical components of the credential architecture determine the interoperability primarily, but the underlying/underpinning trust ecosystems that determine the rules for being part of their ecosystem. Only if we recognize that there are different parallel ecosystems – e.g. the entirely open ecosystem of internet, the vendor ecosystem around a specific wallet/technology solution, or a government ecosystem (even of a regime that we do not particularly like) – we can build a superimposed ecosystem for education and research on top of them.]
Background information:
(just for reference: there is much more than ‘identity’ credentials: a far from complete indicative overview)
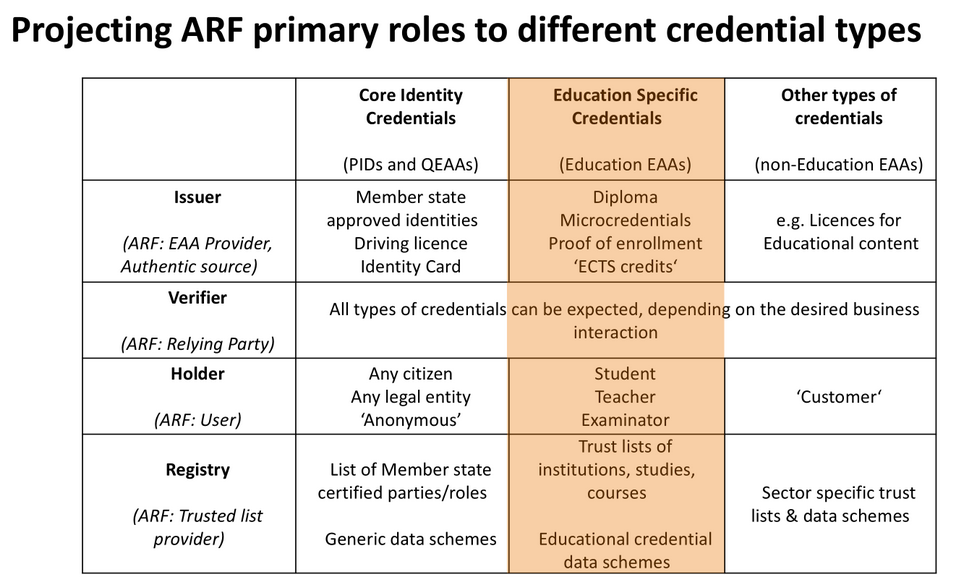
SESSION #1, Breakout #2
Session Title: Problems with Database Handling of OAuth tokens
Session Convener: Hannah Short
Session Notes Taker(s): Liam Atherton
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Start by airing woes:
- Infra in AWS, one prod MYSQL Aurora for everything – OAUTH2 database/grouper
- Consistently see scaling issues especially since DUNE has come online.
- Vault was seen as a more user friendly way of sharing user tokens, MYSQL database wasn’t designed for this scale
- (DUNE is a neutrino experiment at fermilab)
INDIGO IAM/CERN don’t need access tokens to live in the database because they can be offline validated. This is still done for now. Users want very long life access tokens, solution for this is to have very fine grained access tokens making the database become huge.
Report from Hannah seems to reveal the same problems are being seen everywhere no matter the stack being used.
Legacy tools can’t really be replaced, what can be done is to change what we have to make it faster. Offloading the revocation check may be the way to do this (something about hashing here – I didn’t understand it – ask leif/something to do with CDNs)
Problem was found during the ATLAS data challenge, millions of the same token were found. Could be solved at the application. Same sub just offset by time. CDNs/anycast may be solutions.
These are problems that are only seen at large scale services, is it possible to use a different database structure.
The chain of tokens make it into a merkle tree ID token linked to access token linked to refresh token.
So is it possible to flatten this structure by tying tokens to the original access token
One merkle tree for things you have created and one for things you have deleted. The deleted one will be very small
Mitigations: started by using dynamo db, to relieve pressure on the MYSQL database started putting as much as possible into dynamo (starting with php sessions -> co-manage) this is a low cost solution.
GEANT – Elastisearch solution follows the same idea as dynamo db and allows for a transformation path
MyaccessID doesnt have clients registered directly, clients interact with the local environment
Rate limits create political problems – eventually leading to experiments to create their own
Increasing refresh token lifetimes could lead to hitting a performance issue with SHA256 processing slowly.
Building a tool to do proxy token introspection, maybe an incubator to look into this. The python code is not enough.
Rust may be the language to do this (experience with rust/python interfaces at NORDUnet) concurrency model of the language is important. Go/rust/golan.
SESSION #1, Breakout #3
Session Title: Can we connect vanilla OIDC RPs in OpenID Federation?
Session Convener: Davide Vaghetti
Session Notes Taker(s): Alex Stuart
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Davide Vaghetti (DV): We start with the preference that we want to connect a vanilla OIDC RP client into OpenID Federation (OIDF). We don’t want to modify the code of the client. And we don’t want to use a proxy.
Albert Wu (AW): So we don’t want to install something like Cirrus Bridge?
DV: No, we don’t want to run the transaction through a proxy.
There was some discussion about “Discovery” as an overloaded term:
- – Finding metadata for an OIDC entity (this is the one we use here)
- – OP discovery by someone at login time
DV: The RP libraries I know seem to have 2 scenarios:
- – A number of libraries (like node.js) which can be configured through a JSON config file
- – Those which look at an OP’s .well-known
Pieter van der Muelen (PvdM): If RP can only connect to 1 OP, we have to exclude it. It has to be able handle more than 1 OP.
We started discussing the functions that the federation must have:
- – Update metadata
- – Resolves trust chains
- – What do attributes mean
Someone: So this is like a site-local proxy which does the federation operations
Björn Mattson (BM): We start with OPs that can do OIDF, and add RP which have this local script installed.
Albert Wu (AW): How does the RP do mapping of claims? Or knows what it in each of the claims?
Wolfgang Pempe (WP): that’s federation policies
Niels van Dijk (NvD): but OIDC doesn’t have federation concept!
DV: and OIDF doesn’t talk about claims!
AW: but in real-world federations, we will have to consider this
DV: Yes, but this happens in a different part of the stack
AW: That’s no different from SAML
PvdM: Do we need to drop the requirement “no changes to RP” and make some obligations? That policy-based stuff … what are the requirements for an RP?
DV: The first requirement is that the RP must be able to deal with more than one OP. It has to understand how to deal with one or more OPs and have some interface to choose. An “OP chooser” let’s not use discovery. And if it’s a fixed list of OPs, it’s not dynamic and not really discovery.
DV: An OIDF OP, receives a vanilla request from vanilla client, what would it do?
AW: Assumes all trust mark verifications done?
PvdM: Yes
DV: what would OP do when it receives a request?
Gabriel Zachmann (GZ): It would try to use (client_id, secret) even if dynamic registration. PKCE is based on top of (client_id, secret)
Phil Smart (PS): At this part of the flow the OP wouldn’t have the (client_id, secret). Is there an assumption that the RP is already registered?
Holger Wurbs (HW): if fixed set of OPs, could pre-register the RP
PS; If it’s not pre-registered, then the RP would probably need to send trust chain
GZ: then not vanilla!
Jens Jensen notes that you may have different client_id, secret for each OP.
GZ: If the OP can’t do client_id, secret because it doesn’t have the RP registered, how about public key? That would be an additional requirement.
Pål Axelsson (PA): In the current setup, SPs such as Canvas, have to configure each IdP separately. Will we have to do that in the new world? It’s another constraint on use.
If we need to manually register OPs with the RP (and vice versa) then it’s not OIDF. Which leads to another requirement: it can’t be a manual process or UI to register OPs with the RP. Needs a helper script to do the explicit registration of OPs in the RP.
Diana Gudu (DG): RP needs to be registered in the federation
NvD: we assume the helper application has done this.
.well_known entity statement can have different FQDN for redirect URI?
No concept of entityID in OIDC, that comes in from OIDF. OIDC has client_id, secret, redirect_uri…
NvD: so what does OP check?
OIDF is what defines the technical metadata
GZ notes that a vanilla RP has no .well-known endpoint!
PS: We have to be careful because RP could get OP metadata from two sources. If the RP looks at OP’s .well-known, it will get the plain OP configuration which doesn’t have federation policies applied. It needs to get OP’s metadata through OIDF route
DV: Explicit registration is run by the script, so it should point to the OPs
NvD: so the helper needs to republish OP metadata?
GZ: helper tool writes config, the RP reads statically not .well-known
PA: That’s why I said we need explicit registration yesterday
NvD: don’t like it but might need it
DG: Notes that explicit registration expires
Requirements for RP (see photo):
- – Must be able to interact with > 1 OP simultaneously
- – Must be able to read config from a local source
- – Installed next to a helper script, which can tell the RP to reload config through a HUP signal or similar
Helper script
- – Resolves trust
- – Downloads and verifies the OP’s metadata and does explicit registration of RP with it
- – Writes static config for RP
- – Has to do this regularly
AW: This sounds like ADFS toolkit, where helper script needs to have access to filesystem / OS.
There was general agreement about that observation.
The session concluded with a short, inconclusive discussion about whether this could be integrated in mod_auth_oidc because we ran out of time.

SESSION #1, Breakout #4
Session Title: SCIM
Session Convener: Marcus
Session Notes Taker(s): Floris
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Marcus shows a SCIM schema for eduPerson and for voPerson on screen.
Goal for Marcus for this session: is this an acceptable pull request for eduPerson and voPerson?
(This is not used (in production) yet.)
Just in time provisioning versus just in case provisioning (like with SCIM). The good thing is that then you can deprovision.
AARC community schema: binding in SAML, OIDC claims, SCIM and LDAP in voPerson and eduPerson and some standard attributes.
Most of the information in the pull request is not needed for the application in advance.
Peter Havekes: you could only provision essential attributes: user ID and groups (and the rest follows on login).
Affiliation and entitlement, for example, are not expressed in SCIM user or group objects.
Another benefit is keeping user attributes up to date between logins.
German Opendesk initiative: nextcloud, openproject and Matrix, uses a central identity system that uses SCIM to provision, helping us with software vendors already implementing SCIM.
Bas: to provision AWS, for example, you don’t want this extended schema, but for education and research use cases this makes sense.
What about data protection: you should provision a minimal set of information, in case a service is breached.
Peter Gietz: 5 years ago at TIIME, SCIM was discussed . One more use case then was in relation to eduID: the idea was that Campus IdPs would provision to the eduID proxy
THis work will also be valuable for current work on Higher Ed schema in Verifiable Credentials, an activity led by Niels
Deprovisioning is a strong use case for SCIM, ,since it is hard/impossible to poll the IdP. Attribute queries also don’t scale (to a large university, for example) and are hard for IdP operators to implement properly.
Back to the goal of the sessions.
SURF will review this, and we will also ask Leiff.
The REFEDS schema board has been dormant, they manage SCHAC, voPerson, eduPerson and more.
Several members of the board are present at this TIIME meeting.
To do:
- Community review
- Message on the schema discussion mailing list that we want to do this
- Discussion on the list until we converge
- Then the technical bit of assigning the URN (urn:mace) is under control of Internet2 REFEDS.
The SAML representation exists for voPerson, but only the simple one.
Also, we should think about a maintainer or steward of this extension of the schema, for example, when an attribute is added.
Schema Editorial Board information, including link to public schema-discuss list
There is similar work going on for verifiable credentials for voPerson, in JSON.
Also add the group schema for eduPersonEntitlement as an optional group attribute. Does this also happen for other schemas? It makes sense. But will applications be able to handle this?
This model could also be extended to LDAP, instead of the group in memberOf, you would add the entitlements.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
SESSION #2, Breakout #1
Session Title: The next phase for eduID’s
Session Convener: Marlies Rikken, Christoph Graf, Zacharias Törnblom
Session Notes Taker(s): Peter Havekes,
Session time keeper: Stefan Liström
Tags / links to resources / technology discussed, related to this session:
Slides shown by Christoph Graf
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Switch edu-ID has existed for 10 years now. Some changes are needed to make it another 10 year.
1,2M Users, but leaving red marks in the Switch-books
The Switch edu-ID consists of a self asserted identity, that is being enriched with validated data and affiliations at universities.
With an eID, the self-provided data could be validated by data from the eID. The wallet is not usable for login, because of UX.
EU values influence the universities: Universitie Aliances, erasmus+, european degrees, eIDASv2, EUID-wallet.
Big-tech (Entra ID) is competing with the SWITCH edu-ID functions.
Issues:
- – Value vs costs
- – E-ID taking over functions
- – Entra ID is taking over functions
So, changes are needed
Solution options:
- – Use eID for onboarding
- – Stop edu-ID authentication for university users
- – Delegate authentication to agov, Government based authentication based upon the EID system
- – Drop edu-ID
- – Use EntraID to (re)build a federation
In Sweden eduID tries to move complexity away from the universities to eduID, eg offloading MFA to eduID.
A problem is the disconnect between the universities’ IT department and education+research.
Discussion on publishing eduID IdP’s in edugain.
SESSION #2, Breakout #2
Session Title: OAuth tokens and token exchange
Session Convener: Jens Jensen (UKRI), Pieter van der Meulen (SURF)
Session Notes Taker(s): Bas Zoetekouw (SURF)
Tags / links to resources / technology discussed, related to this session:
- – OAuth 2.0 Token Introspection: https://datatracker.ietf.org/doc/html/rfc7662
- – OAuth 2.0 Proxied Token Introspection: https://docs.google.com/document/d/1wDBYgtVwQSIr-mpqhDMywweTeZyjGNfscFIW5lzRiwE/edit (DRAFT)
- – OAuth 2.0 Token Exchange: https://datatracker.ietf.org/doc/html/rfc8693
- – Keycloak Token Exchange: https://www.keycloak.org/securing-apps/token-exchange (introduces request params like requested_issuer)
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
How to handle token tokens in a proxy-based infrastructure? No problem if there is only a single proxy, but in case there are multiple OPs, things get complicated.
[INSERT JENS DIAGRAMS: proxies, and sequence diagram]
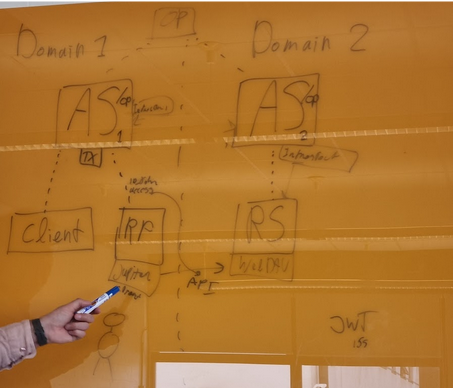
Usecase: user is running a workflow on a specific service to which they connect to using OP A, but this workflow requires access to a RS at a different OP/AS.
Two solutions:
- client knows about this problem and explicitly asks for a token that can be delegated
- Two subitems
- RS knows about the problem and asks their AS to verify the token from the other domain
- Alternatively, use a “magic” token exchange service that can exchange token between different domain, if the AS doen’t support this natively
The Magic Token Exchange Proxy would need to be able to “simulate” token exchange for AS’s that do not support it natively. That is probably hard, because this needs to be done without user interaction.
Why doesn’t the client trust all of the AS’s? Because of scalability; there are probably a lot of RPs and RSs that need to be supported.
How to handle consent for token exchange? This happens in the backend so there is no user interface? This is handled when the original token is given out. But how to make clear to the user that this token might be used for token exchange with other domains?
What type of tokens are we talking about? This is both about OIDC Authentication ID tokens and OAuth tokens, so that complicates the story.
A trust relation between the OP/AS’s at the different domains is required. Also the user needs to exist at both domains.
Keycloak has implemented the token exchange, but adds a number of non-standard properties to the token (see Keycloak docs).
The token is assumed to be unencrypted JWT, so the AS knows the issuer and can verify the signature. So routing is not a problem in principle.
How to handle security and access control for resources in token exchange? The ASs are not only translating authentication and id tokens, but also authorization contexts. So the different AS/OPs need to be part of a common authorization/trust model with common roles/entitlements/etc.
Next steps:
- – Hacking the ASs to support this type of token exchange
- – Documenting use cases (AARC?)
SESSION #2, Breakout #3
Session Title: UX for digital identities
Session Convener: Francisca, Esther (absent due to personal circumstance), Floris
Session Notes Taker(s): Jon A (not just me!)
Tags / links to resources / technology discussed, related to this session:
Presentation: REFEDS UX Working Group
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
- – Recommendation for Refeds UX working group
- – Brief summary of charter could be UI standards for academic wallet, for useful and understandable academic identity and learning creds
- – Focus on wallets
- – How do you represent credentials for wallets?
- – Wallets will not just be for academia
- – Someone using Microsoft authenticator in a enterprise env or learning env, don’t have control
- – Might have control over how UX present
- – Can’t override what OS – mobile OSs all have their human interface guideline (requirements)
- – If R&E community build own thing you can control UX?
- – DIscovery flow, for example, was a massive undertaking. You need experienced UX designers to figure out UX.
- – Wallets and integration will take a long time (maybe longer than our lives).
- – General wallets, registration of ID could be part of the UX?
- – Visual examples using adopts to physical wallet, and what the human associates with, trying to split the split of asking for information is counterproductive. Technically take the multiple steps, or wallet/cards, different information. Asking the person to select, is going to be challenging.
- – Walk up to a bar, don’t care what information they are looking at on ID.
- – If you scan the card on the vending machine, you might think differently, login with facebook to get beer! 😱
- – You tap and don’t ask for additional things.
- – Ask the user what they are using it for.
- – Present phone to scanner default card. Verify face iD, but not in transit mode. Different to single sign on which card I’m using. Transit mode, which is the preferred card. Same information gets.
- – Give credit card information to bill later.
- – May need to re-think how sequence of events happens?
- – More than just technical, authn, attribute release flow.
- – Paradigm user can understand.
- – Paradigm shaped by government?
- – Looking at UX issue, not by default presenting users with screens. Legal option to selective disclose in UDI()? Wallet, statement saying what are thing it can ask for. Merged into UX.
- – European work permit, PDA contains a ton of information, once is release everything, or provide you have one. No way you can ever drive a UX off the attributes in a credential, that’s out. Possibly drive a UX on what they are allowed to ask for… profiles.. abstraction or different personas (anonymised, pseudo and others), lock into settings and move on?
- – Parallel to that is the 3 access categories in REFEDS. Could use that to mould the UX?
- – SSO think of these, want to walk into a control access library, tap in mut
- – Access gateway should know what to ask for?
- – Access to physical resource, analogy. Library vs nuclear “clean room” examples cards in that.
- – One detail requirements for UDI spec, pass key provider.
- – UDI wallet app.
- – Login to wallet without presenting anything, as a pass key proxy transit?
- – Tesco example…as a user I know I need to present something on my phone, pull up the barcode for loyalty “clubcard”, but actually tap the NFC reader and go straight to payment. Users are dumb and present the wrong credentials…
- – DAKL queries, pair with signed ACL queries and limit what wallet is meant to do. Third party will say what you asked for. Payment context, age verification context.
- – London card is transit card. Default payment card…
- – Broken UX on the apple pay, UX of reading, just keeps failing
- – Australia supermarket giant, is using NFC on their cards. Physical card or QR code in app, in wallet.
- – Responses from the same wallet. Family sharing plan and apps and things. Also include limit to ability to wield cards, same person.
- – This is how, you spousal abuse and stalking and organised crime, force people into.
- – UK is policy hesitant about passkeys?
- – Linking, give me an ORCID(?) and eduPerson from the same university is difficult to verify.
- – REFEDS focus group should do how do you represent credentials within a wallet, visual representation of employee, learning, micro credential, diploma etc… Easy to pick
- – Reality of how you present information is different to SSO.
- – Most likely mobile device, accessibility provided by device, follow their guidelines. No obvious gotchas, 5 things from university, but also hiding each other.
- – For visually impaired, so large they can’t see everything. Make sure it scales on a limited screen.
- – Attribute check boxes might not work on screen / mobile.
- – Two layers?
- make sure you have the expertise in the group, topic and push some boundaries
- 2.5yr, non successful and how to represent MDUI logos in metadata. Width DPI and background colours. Seamless access can’t deal with this and don’t display logos. WIll care about logos here..
- Carve out and institutions can and should control: this component here, and here etc.. Instantly recognise choice of colours.
- You want branding common.
- Universally recognised logo, and RFID capable, those symbols.
- Logo parents can tell what it means. Passport RFID logo
- Three triangles for Radiation
- Have rules about what logos etc.. are displayed, and what the specs are be open.
- All passports must meet. What kind of information we might
- Some JSON structure, when you do presentation with wallet, couple with graphical, SVG overlay, other elements with fill with data computer readable, to form human readable, to display in wallet. The overlay for a specific credential. Bunch of JSON stuff in wallet.
- Display overload in the browser
- When users use SAML log into an SP, consent screen, could we apply this concept there. THese are the whole list, accept the button. Apply the same tools.
- Suck in the SAML metadata as a discovery tool, and present one time and transition through discovery flow, greyed out user credential in your wallet, and populate that into real credentials. Initing an issuance flow. Consent release.
- How do we package in a meaningful bundle, and what the relying, rather than selecting individual data elements. Group those things, in meaningful and simplify things, and edge case, and having some say in presenting it as a person
- That is why UDI is going to design and policy decision and control about how you use credential.
- External resourcing, without UX designers. Take more than a single working group, don’t try to bite off more than you can chew.
- If you are designing something and incorporate from the start the accessibility.
- Tell people don’t be idiots, and they do it anyway.
- Less about what information, more creating a standard visual for the card, the positioning things same place everywhere, same as drive license, passports. Sets the tone for what we want to do together.
- Learning credential, diploma, professional qualification, some sort of VO/community, microcredential, half a dozen need to be recognisable instantly.
- Submit plans to go on REFEDS working plans, identify plans and individuals you need. Just happened for 2025, might be able to make an approach now?
SESSION #2, Breakout #4
Session Title: Accounting
Session Convener: Peter Gietz
Session Notes Taker(s): Marcus Hardt
- • Federations are more used also in sharing costy resources
- • Thus there needs to be an integration of accounting and billing with AAIs
- • How to do it?
- • Who decides whom to allow access?
- – If the user organisation pays for it:
- ▪ The user organisation (campus IdP attribute)
- – If not:
- ▪ The service provider (VO managed attribute)
- – If the user organisation pays for it:
Initial Questions (with answers) see below
Tags / links to resources / technology discussed, related to this session:
The below wiki link contains documentation for how budgeting and accounting is handled in SURF Research Cloud (which is connected to SURF Research Access Management, a community AAI based on AARC BPA)
https://servicedesk.surf.nl/wiki/spaces/WIKI/pages/17825937/Budgeting+and+accounting
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Accounting: Could / Should we (AAI) use edupersonAnalyticsTag?
Bo Bai: Puhuri experience says that we should have accounting as a separate service
Peter: a similar Tool exists in Germany called JARDS
How does the service charge users?
vs
Is the VO/Community/Group be charged
Is the AAI in charge to
In the traditional grid this problem was essentially solved: One VO per user, that’s the one to be charged
With token based infrastructures, users can have multiple groups, entitlements, etc…
=> Will a new attribute be sufficient to transform this information
In Puhuri the accounting would be charged to a grant (which involves limited resources)
The interface between the services and the accounting service should include
- • Accounting statement (group, VO, budget-code, grant)
- • User Details (some kind of unique identifier)
- • Resource Usage Information
Service knows which accounting service to report to, because this is included in setting up support a specific grant
Discussion about:
- Is accounting based on an existing grant (preallocation of resources that are then used up)
- billing based: as long as we can charge someone, users can use resources
Use cases for both exist
PUHURI, FURMS and JARDS are systems that organise allocations for user groups
Could the endpoint for accounting be part of the user attribute set?
A PID could make sense for the accounting tag, because the PID comes with a set of metadata, describing itself. This could help the Service to understand where to send the accounting data; and whether or not to trust sending accounting data to the service.
The (smart (i.e. self describing)) PID idea is generally acceptable, but people fear that this makes the whole system more complex and turn it into a fully fledged billing system.
Is there an accounting markup language? Usage Information Record is a small core schema, which allows a lot of extensions.
Accounting in a federated context is more complex, we need a common interface.
How to handle cases in which a user has multiple entitlements? On which one would the accounting be booked?
SURF research cloud has a system that has an elaborated way to address this
Reservations about global billing: Computer centres don’t want to compete with one another.
Final questions
- • Can FIM make accounting easier? => YES
- • Should FIM take this up?
- – e.g. define an attribute, or define how existing attributes are used, should we give a hint?
- – Everybody: YES, if all we do is providing a hint on which attribute the accounting is used for
- • Should we say “do your accounting somewhere else”? => YesBut, but FIM provides hints
- • What other open questions are to be asked? => Where are interoperable approaches
- • Does eduPerson (analytics tag) already have a solution? => Probably not so much. We probably need separate discussion, Also following the GUT profile discussion (-> Mischa)
SESSION #3, Breakout #1
Session Title: User difficulties in proxy workflows
Session Convener: Mischa, Jens, Hannah
Session Notes Taker(s): Hannah Short
Jon Agland (trying to add some!)
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Mischa’s case
- • If i have multiple home institutes I will fairly quickly forget which one i used
- • Linking them together would be good but linking is a pain
- • Orcid, Edu-ID, MYAccessId all can help
Jens’ case
- • What if my user does the whole login flow through multiple proxies but ends up without enough LoA?
- • Can the SPs hint what LoA is allowed?
- • Can proxies inject LoA half way through and force a re-authentication?
- • This can get really messy (easier for users to always provide MFA for example)
- • Wouldn’t it be easier to ask for MFA and high LoA all the time? May not work in practice if people have different “hats”
Discussing MFA and https://refeds.org/profile/mfa and new working group, reviewing the MFA and SFA profiles.
Assuming you have IdPs and SPs, but concern about works via profile. Proxy fallback, and Proxy doing MFA. Require MFA, vs can we do MFA?
General agreement that requiring MFA through proxies is complex. Not much practical experience yet.
Hannah talking about the discovery problem in EOSC AAI.
Example:
- Log in to community Omega AAI in the morning to do a community based service
- Then log into a separate service behind MyAccessID with CERN
- Then log in to a service behind MyAccessID that needs the community attributes
- IdP hinting won’t get you to the community AAI as you’re logged in with CERN
- You can’t get the community attributes without logging out and starting again
pick the “wrong” organisation even though it’s your organisation, but because you haven’t gone via “community AAI”, you don’t have .
IdP hinting and not logged in, will I be logged out or will I be logged in. Infra proxy. Collected to community AAI, infra AAI, too many ways.
Interface might discovery issues you already lost your user.
Mixing authentication and authorization and account linking… IdP hint already logged in ignored? Forced
Generic problem vs SAML specific problems?
User not distracted by having home user.
Authorization is coming via login flow.
Attributes need to be sent, the problem is the user identity at connected to MyAccessID, should be connected for authorization, was always enriched by.
Role selection/picker, to enrich
Which community AAI to do you select?
Risk them not being valid, live provisioning/update during.
Cannot do 1:1 so MyAccessID is required. If MyAccessID was not in the middle would we have the same UX / Community AAI selection issues? Probably, yes
FInal comment, any attack service in which one then it’s MyAccessID?
(shouldn’t be collecting stuff?)
Different points to login is causing a problem, but need to make a single choice. Could be worse in an OIDF world.
Belief that having community based authorisation as part of the authentication flow will be increasingly problematic.
SESSION #3, Breakout #2
Session Title: SIROS Foundation WUWT?
Session Convener: Leif Johansson
Session Notes Taker(s): Nicole Roy
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
“Leif, Ruth, Nat and Stina Save The Universe”
https://wwwallet.org – speculative wallet PoC done in the DC4EU EIDW. John Bradley and Leif wanted to write a wallet entirely in frontend code and use fido tokens as the keystore. PRF extension to browser APIs that support fido could be used to do stuff.
Stina helped Leif find developers – many from Yubico, some from Greece, built the wallet. Worked really well.
Stina put a chunk of money into a foundation to fund the Siros effort. Siros foundation, in Sweden. Play on words on Sirius, the dog star. Pay for developer work to do open-source identity stuff.
Advisory group has Niels Van Dijk, Mike Jones, John Bradley and Stefan Listrom in it.
Hired UX people, appdevs, a senior UX developer, maybe from the RA21 project. Mike Jones doing standards work.
Do you have any questions?
Is there anything we should be doing?
Open ecosystem around a wallet that is built for the open internet.
They have a partnership with the ISRG to do a research project to bridge OpenID Federation with PKI. Giuseppe Di Marco has a proposal to do letsencrypt cert issuance using OIDF.
Do our own browser that we control?
Build a set of libraries and/or API specs that support doing our own wallets?
Wallet/Browser basically the same thing.
SESSION #3, Breakout #3
Session Title: MFA – how to prove it in a delegation scenario
Session Convener: Marcus Hardt
Session Notes Taker(s): Andreas Klotz
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
RPs are handing tokens over to each other via OIDC SSH, but one of them requires MFA.
The ID token would have the claim which signals MFA available (“acr” -> https://refeds.org/profile/mfa), but we are only sending the access-Token
Nobody has any experience with this issue so far.
We realised that the MFA claim can be pulled from the Proxy with access-token, so there is no problem.
Mention of https://refeds.org/profile/mfa and authncontextclassref, that’s what’s being doing on the outside of the proxy with IdP.
SSH usage, life of access token should be considered?
The second RP can currently request new access tokens from the first RP via a backchannel mechanism in the tunnel which has established.
Specifically Unity-IdM does not provide the acr so far, the implementation needs to be looked at.
SESSION #3, Breakout #4
Session Title: OpenID Federation Topologies
Session Convener: Davide Vaghetti
Session Notes Taker(s): Phil Smart
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Davide:
- • Based on sessions about federation topologies from TIIME 2024
- • Still areas to discuss based on trust chains
- • Two options discussed in TIIME 2024 (talking about trust infrastructure which includes wallets, or other entity types)
- ▪ (PS) not sure, it’s discussed below
- • Image of trust anchor with two IAs and Leaf entities.
- • What if one of the leaf entities has joined one IA (maybe national federation) to build a trust path to an entity in another IA (national federation) via the eduGAIN trust anchor
- ▪ One leaf wants to stop at the national level
Pal:
- • From a tech perspective this is possible
Phil
- • What happens if a Leaf B from one federation wants to trust a Leaf A from another federation, but leaf A should only be accessible from leafs inside its own federation. Is that possible
Davide:
- • We can do that in SAML now, because you can choose to export and input into eduGAIN, and everything is taken from your national federation
(Name incoming)
- • What is the use case and what do we want to prevent
Davide:
- • This is the use case of something that does not want to be exposed to eduGain, but this is harder without the correct topology in OpenID Fed.
- • RPs registered locally can be invisible to eduGAIN, which is a feature in the current SAML system
Albert:
- • Diagramming issues, the IA is a TA in this diagram
- • Conceptual question: given an IA can be a TA and can trust arbitrary other TAs. If the root does not enforce any other metadata policy, could the lower level IA/TAs just mesh with each other, not go through the common route
Pal:
- • You might get islands or end up excluding areas
Martin
- • There is no problem in solving this with OpenID Fed, but it is a discovery problem.
Davide:
- • Maybe it is more complex
(Name incoming)
- • We are talking about two different use cases.
Albert:
- • Confusion might be the diagraming things.
- • Leaf node on the bottom has to decide which to trust
Martin
- • Leaf 1’s trust anchor will be the IA, it will never form a trust chain to the root TA
Pal
- • Common case you need to trust both TAs. So if the IA is a TA, that is one trust anchor, and if there is a higher root TA, you can also configure it to trust that.
… (did not catch)
Drew
- • Problem is that an RP only wants to participate in the national federation and not globally, mechanically, but why would they do that
Albert:• Universities only have services that are exposed to the university
(Red jumper, name in comming)
- • That situation is solved by configuring that OP/RP to only trust the IA
Albert:
- • California only wants to trust OPs in California, but some want to connect outside that.
Martin
- • Can solve some of the problems with trust_marks
Holgar:
- • Agrees with trust_marks
Albert:
- • California RP wants to talk to OP in Surf. For you to login you need trusted policy
Davide:
- • If the trust chains for the leaf stop at the IA (national federation), that solves trust but we still have the discovery problem.
- • Although this is limited in two ways
- ▪ The federation needs a list to prevent displaying that OP/RP you want to hide for disco.
- ▪ Which is a bit like the filtering we do in eduGAIN now
Albert:
- • To use trust_marks, do we need trust chain to prove the mark was issued to you
Gabriel:
- • Trust mark issuer responds with who is allowed to issue trust marks
Davide:
- • Could use a trust_mark for filtering rather than allow/deny lists.
Josh:
- • Observation from a SAML fed perspective and Kerberos. Kerberos has a similar hierarchical model where you can chain together KDCs. Kerberos solves this by having policy at the KDC. But Kerberos walks the tree, openID fed is different.
(Name incoming)
- • Kerberos is an interesting analogue, you can do the same thing in either.
Albert:
- • Similarity to web PKI for trust_chains
(black shirt, name)
- • Kerberos requires symmetric keys, openID fed uses asymmetric keys, which does change the process.
Davide:
- • Use trust_marks to filter out entities from List endpoint
Albert:
- • National federations could run two different TAs, one for internal and one for external.
Davide:
- • Draws new topology with two IA/TAs for a federation, one internal and one rooted at eduGAIN
Martin:
- • Limits who can speak to who and you might not want to do that
(lots of contribution)
- • You could have an IA/TA trust another IA/TA for cross trust
- • Who do you trust and why
Pal, Albert (others):
- • We need a white paper on how to setup these topologies
Davide
- • Mulitple paths can end up at the same leaf, and the policies might conflict.
Gabriel:
- • (With the complexity of many IA/TAs, levels) Does this scale?
Davide:
- • We have something like this today with MDQ (PS, did not catch)
Albert:
- • Agree, we want to keep this simple, but oversimplified you run into constraints for real world needs. Virtual Organisation complexities.
- • Loads of RPs out in the VOs
Scott:
- • Provocative question: allow large VOs to be a IA/TA that has eduGAIN as a trust route?
Davide:
- • Is possible, but if you do not want to be a federation and sign the declaration, then no
- • Maybe something in between running infrastructure withing a federation and creating your own and joining eduGAIN. Right now we do not have this choice, but in OpenID Federation, we could have flexibility around these use cases.
Scott:
- • Shared governance in eduGAIN in the future.
Davide
- • 2 out of the 6 seats are reserved for non-federation operators.
SESSION #4, Breakout #1
Session Title: OpenID Federation business drivers and trust architecture; InCommon Federation Proxies Report – what’s next; Selling Federated concepts
Session Convener: Nicole Roy
Session Notes Taker(s): Jon Agland (helpers welcome!)
Tags / links to resources / technology discussed, related to this session:
- • Peter’s personal takeaways from this morning’s first round session about credentials and wallets (regarding topic Selling Federated concepts to the EU):
- ○ multiple trust ecosystems exist, they overlap, they may use different technologies (PKI, ledgers, DID) but they still need to be interoperable.
- ○ Different trust ecosystems have different scope and different ‘social’ trust mechanisms
- ○ Design goal should not be to build a single unified ecosystem but respect ecosystems boundaries and make them interoperable
- ○ A trust system for R&E should be ‘superimposable’ on multiple identity ecosystems
- • Peter’s personal takeaways from this morning’s first round session about credentials and wallets (regarding topic Selling Federated concepts to the EU):
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Help Nicole Convince her boss that we should do an open ID federation pilot (please?)
Think we need to do this in the US
- Interop with rest of the world
- SAML won’t be viable in 10 years for cryptographic reasons
Not concrete enough, need business drivers, not just making money, but that participants that will do badly, or that we can do a pilot.
Past success, federate funding money NSS and NIH, went from 10% adoption of refeds mfa to about 75%. That sort of driver, does that exist to make it exist.
Pieter? – SAML slowly dieing, any money putting SAML services is wasted, and very expensive and case to move away from SAML. 2nd stamp in the argument only one replacement technology that’s viable OIDC (not OIDF yet), dutch fed can have one OP to serve education and research. In the US don’t think you reasons of scale and trust and that’s viable? We will have multiple OPs how we are going to manage the trust between them like gap measures stop gaps, that allow you to do that.
Expert OIDF is going to be it, good reason to be pilot, yes
Complication factor, new things need to by OIDC so that we don’t invest. Sunk cost failcily, thousand and thousands of SAML SPs
Don’t have to move, and then announce a change,
Much easier to move to OIDC/OIDF later on?
Push function, wants something that has gravitational pull e.g. federated APIs for research data, no no one wants XML.
Mobile is much easier with OIDC, because of the interaction or the JSON, or the way it works. Flows are harder to implement well in SAML.
R&E use cases for OpenID connect was mobile. 10 years ago. No community examples of cross institutional access.
Federates have to OpenID federation.
Do I need OpenID connect?
Boss believes we can get W3C to fix XMLDSIG? We can also use carrier pigeons?
COnversations, Microsoft has initiated the process to make it historic.
Believe sufficiently dead.
“Desktop publishing” application for OIDC fed.
InCommon federation proxies report, not about advancement, but to help exist folks and understand where they are and that they are necessary, and that current SAML federation model does not at all, service these large VO proxies, they are invisible to the federation.
Important thing about OIDC federation, is to truly show the depth and width of the community (i.e. including research/vo proxies etc..)
Add post quantum to XML
People who care about SAML and care about Encryption are diverse and small, venn diagram would prolly not overlap.
Mindshare refeds, and wallet and oidc/oid fed mentioned. Mention SAML no one turns up.
Relate it to the idea that they care about. No one cares about SAML other than us old people?
If you say we are big enough to go this, half a moonshot(!)
We’ve been doing our own full stack SAML and it’s COSTING US MONEY
Push hard against the notion it’s not end to end, introducing, functional redirected state, browsers will make it harder.
Your business will die?
Business will be found in the intersection of regulated industries, interface with health, another regulator class of federations much easier if we can move to a more flexible technical substrate.
Drug development, academia, bio medical
SeamlessAccess, pharma
Why do you need to do a pilot in OIDF, will need to develop the federation operator tooling. Make sure standards we are relying on are taken care of.
Things we need for our communities, different use cases to government
Infra that needs a trust infra, infra is a repository for data that needs protection, and controller who is someone else, and they will be a function of the dataset, retain control of the data.
Health data access body?
Are you trying to solve that problem?
Cross organization and federation boundaries
API
Might be a trust mark thing? Assignment of trust marks.
Pull rather than push. SAML locks the capability we need, but OIDF the only protocol that has this syntax, is to solve business problems, catch-up with SAML or use OIDC federation.
Strikes that we are introducing this dependency with let’s replace the current federation and then we’ll do those other things, and then do the other problems, and already learned a bunch, and move the other stuff into that, and some already go, and challenge that.
Only works if you commit, all three sides, to move.
Must have enough OPs to make it RPs to make it worthwhile and quickie adopt, you can’t run small pilot only small for technical.
For managing trust in OIDC, eduID, gained from OIDC connect, very generic and powerful way and communicating trust in anything or for anything.
Cottage industry of thinkers and these network effects, if you want to start something big, you have to scale down to sub network and go to adjacent ones. Pharma and saturate it and schools that connect to Pharma will do that.
Saturate the OP, and we have partners, and we convince higher ed, or knitch of higher education. Learner niche, idea talked about, idea we know enough identity providers/OPs and speak in OIDC fed for any RP, how many and they all need to talk this, get that layer of that OPs quickly and then the RPs can move.
When I want to have that trust infra now, combine that with existing identities from the existing federation, and quickly get the identity providers speak OIDC federation, so that the resources are OIDC based.
Piloting the OIDC federation for IdPs, and then start looking at SP side.
Think IPv4 and IPv6 and where we do NAT in IPv4 as the transition.
Combine these might make things move faster, existing solutions, More about what’s needed. Likely done elsewhere are proxies. Simplest can we can find repositories in ESOC and fair data, lots of controllers of that data.
Very common problem. AARC Licia and Pieter
Combine access to the data, certification (I’m a doctor etc..), you are having a registration system, that’s the hard bit, reason data, and affiliation and an identity and some certification, and consented access, and build something for that.
IdP operator role, assertions you are looking for. I’m a doctor, a university would feel comfortable asserting that. Attribute provider, and the questions identity of the doctor. Process thank links it. Whatever authentication. Identity given by the state. Identity from the state. Regulatory environment all links back to swedish person id. Denmark, might be still good for this, but unclear.
(Sorry reminded of this!)

Selling Federated concepts to the EU
In the current approach, european identity wallet likely to take a choose a technology for relying parties, central go to government and get registration for EU wallet, very difficult discussion, sufficient and safe wallet, on the other hand ,project all kinds of use cases for education, put your diplomas and social security details in there… assume that trust policy and network issuing diplomas as same as EU regulatory boundaries, and trying to build a case in policy terms and why is this a bad idea. Scope ecosystem for all these use cases if you want education creds in the wallet, or research creds or doctor registrations, and are already dealing with that. Trust’s that make this new technical tool and adopt process and organisation trust and directed to a per county registration.
Not openID better than trust lists? Trust lists, and why is that bad idea?
Issues/verifier/and wallet provider and wallet instances.
Reason for national IDs closed system viability, danger expanding it to entire system that might benefit, any entity that wants to use and register at their local/national government, means same things as being part.
Does EU commission, as global interop as an anti-pattern? Don’t know or care, and throwing things at wall, see what sticks. Anything we tell them cannot be something they don’t care about.
Red herring, known to the ecosystem, and some government oversight. Make sure to be certs from this trust list, that’s the registration. Controlled attributes e.g. social sec numbers, subject to registration/treat data responsibility, oversight issue stating, what we do in federations.
Club and member, technical standards concepts and not complying to, having other federation. EU is a federation (federation of federations), member states manage their own registries, aggregated upwards, what eIDAs registration says. What’s the technical implementation of this. BIg fight over OIDF? Front runner is basically have an RP registration, qualified certificate from the European trust list, number two essentially a JOT/verifiable credential that limits the scope of the attributes it is allow to ask. Trust mark and ???. are they reinventing OIDF?
OIDF is a technology, it doesn’t matter can be a gateway to another. German proposal QTSPs, gateway based on ACME (Certificate issuance protocol). Specification, ACME protocol allocates you short lived cert.
Not just a profile, but also a protocol conflict. The way they want to communicate is via PKI, aspect of that design that cannot make sense.
Fix it with ACME server, LetsEncrypt.
Mostly be, problem with trust lists, tried to cross signing, PKI bridge, because of trust requirements.
DACL? Issuer, trust mark aspects, QTSP trust chian is straight up PKI
Investment in this and parallel infra, and turn off stupid stuff.
Most people don’t want to mix up private. Problem of how do you connect the patented it, PIM card? Elliptic curve? WOn’t get implemented
HTTP and TLS.
SOmething that does not work, will not survive?
Governments have money to keep things that are broken alive for a long time.
5 more minutes…
Waste of energy and time to do not do this like this and personal thought. Business case for eduwallets, and very negative, cost of building infra is huge.
Promote the FIDO ecosystem, co-exist with goals of others?
SESSION #4, Breakout #2
Session Title: ROR
Session Convener: Peter Gietz, DAASI
Session Notes Taker(s): Tibor Kalman, GWDG
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Introduction:
- • The Research Organization Registry (ROR) includes IDs and metadata for more than 110,000 organizations and counting.
- • Just as researchers want to have their ORCID stored, it might make sence in federations to store a ROR with the identities
- • People are starting to ask for this
- • What schema to use here?
Pete Birkinshaw has a related proposal in the REFEDS 2025 Workplan
Slide: What schema to use to “store” ORG identifiers? Solutions:
- O-Attr
- No new attribute would be defined/needed
- eduPerson
- SCHAC
- VOPerson
- National federation schema, e.g. dfnEduPerson
- Own attributes
ROR vs scoped attr
ROR vs Institution
ROR IDs vs “virtual organizations”
First “A”: real org from campus IdP
Second “A”: more interests in virtual org
Multiple values might be helpful.
VOPerson: is implemented in local IdPs?
Implementing as o;ror-id or equivalent is likely to be confusing to applications which already read “o” and don’t understand attribute options
ROR vs trustwothiness/assessment?
- • Self-assessed?
- • No Governance for curation?
- • Anybody can create a ROR for any Institution
SCHAC
- • SCHAC Home Organization: not really useful since it demands the domain name
Other possible options (just for completeness):
- • OIDC Claim
- • We don’t need such thing
- • eduMember
- • eduOrg Object Class
Including SAML EntityID as ROR “Other Identifier”
- • existing Github PR for this?
ROR vs Governance vs Curation
ROR vs OID registry / IANA
eduMember
Entitlements?
Result:
The general consensus in the room was to specify a new general attribute with complex syntax to : support more ID types, e.g., EnterpriseOID
Such an attribute could be named MachineReadableOrgID or similar, which should be included either in eduPerson, voPerson or SCHACperson (in order of preferences)
Follow-up activities:
- • Propose new attribute (either for eduPerson or voPerson) as a topic to schema-discuss list (see Schema Board for info), get feedback, consider minting new attribute
- • Vote +1 in REFEDS 2025 Workplan
SESSION #4, Breakout #3
Session Title: OpenID Fed and Discovery
Session Convener: Niels, Gabriel
Session Notes Taker(s): Diana
Session time keeper: Zacharias
Tags / links to resources / technology discussed, related to this session:
– https://docs.google.com/presentation/d/11N79uKrT-evFQ-tgAAoRNNHi6-gYj8u0DC2k-AXjXcc/edit?usp=sharing
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
- • the spec does not include anything on doing discovery of leaf entities
- • we want to submit a spec as an extension to the oid-fed spec
- • “discovery” has a different meaning in OIDC world, a different term needed
- • why do we want to list all OPs in a federation? -> RPs need to display the list to the end user
- • we need more than a list, additional info to properly present to the end user
- • how do we know the OPs will be able to communicate with the RP? -> we shouldn’t care, most OPS won’t work for most users
- ○ can we guarantee it working? -no
- ○ can we decrease the chance of failure -> yes, filter
- • Proposed solution from slides is discussed
- • Seamless access does not want to download an entire list every time the user visits
- ○ A caching solution needed, like MDQ
- • Difference to SAML – you need to traverse the tree to build the list, SAML has static metadata
- • Live filtering while writing the op name – you need to have a cached list to be able to do this
- • Idea: Propose a new federation endpoint to submit a discovery request and get a list of entities
- • Why does the endpoint have to be at the trust anchor?
- ○ TA might have additional info, e.g. trust marks and not need to traverse tree
- • The “client” of the endpoint is the discovery service, what will the discovery service provide to the RP?
- • SAML discovery service is a frontend thing, here we are discussing the back-end -> API
- • Can we make it such that it doesn’t matter if i choose to use seamless access or as an RP choose to do all the heavy lifting myself?
- • the proposed endpoint for the standard needs to be generalised
- • Resembles resolver functionality, doing something on behalf of the client
- • How will the endpoint look like exactly? -> slides discussed
- • “Collection endpoint” proposed as term instead of discovery
- • Does it scale?
- ○ That’s exactly why we need the endpoint
- ○ If implemented in same place as resolver, common caching system can be used
- • We need at least three implementations for the spec to be approved
- • Why do we need an additional endpoint? We could extend the existing “extended listing endpoint” with params, e.g. chain length
- ○ The response is a flat list, might not be enough
- • Problem: There is no way the TA can guarantee the metadata needed for discovery is provided by the entity, e.g. display name
- ○ Display name is already a challenge
- ○ Can we offload that to the OPs? Might be too complex to expect
- ○ A display name needs to be in the entity configuration, but organization_name is not the same
- ○ Even in SAML it is not properly done everywhere
SESSION #4, Breakout #4
Session Title: Deprovisioning from IdP, community proxy and services
Session Convener: Andreas Klotz
Session Notes Taker(s): Floris
Tags / links to resources / technology discussed, related to this session:
- • OpenID Provider Commands 1.0 – relevant for deprovisioning?: https://github.com/openid/openid-provider-commands
- • https://openid.net/specs/openid-provider-commands-1_0.html
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Service: a federated way to log in to a service, and then the service provides the option to create a local account. Deprovisioning will not work.
The SSH scenario is different:
Storage has a different deprovisioning issue: once a user stops logging in, what to do with the storage?
That is more a Research Data Management issue, then a deprovisioning issue.
- • Data protection, right of being forgotten
- • Data preservation
There might be ways of accessing data without logging in (visibly for the IdP and proxy).
There might be communication from the IdP to the proxy, or from the proxy to the users about inactivity or expiring identities or permissions.
The hard part about account linking is account unlinking, which is similar to deprovisioning. For example, a user used their university ID to log in and create an SSH key. After the user is no longer with the university, the SSH key persists.
Don’t expect (home) IdPs to play any active role in deprovisioning.
So we need to look to the proxy for solutions.
A problem with a proxy telling the service when a user was last active, is that proxies implement this in different ways.
So we might make an AARC standard of deprovisioning: possibly OP commands, or SCIM.
OP commands is focussed on getting account status. SCIM is also about keeping information in sync.
In the OP commands draft spec, the OP sends info to the RP, so the RP needs to implement an endpoint. SCIM can be both pull or push.
Indigo IAM, Unity IDM, and Keycloak have SCIM interfaces (Keycloak through an extension).
So, we need some architecture discussion about a new guideline about deprovisioning? Well, there might be nothing to do?
We are going to use SCIM or OP commands, but we might want to define a SCIM schema for deprovisioning and/or a last active timestamp for the user.
SESSION #5, Breakout #1
Session Title: Minimal attribute release
Session Convener: Marcus Hardt / Jens
Session Notes Taker(s): Andreas Klotz
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Especially in entitlements we currently have both issues with bloated tokens due to too many values and insufficient data minimization in a data protection sense.
The OIDC spec does not have a mechanism to request specific values in a claim.
Example of how it should work:
Available Claim:
{
“x”: [
“something”,
“anything”
]
}
Approaches:
Scope request:
“x:something”
Colons might be problematic as delimiters here, as they could be interpreted as URN
RPs should be able to request specific attribute values (scopes for those attribute values) for a given claim.
Sometimes you may not know what specific value to ask for, so you have to look at the whole claim as provided by the OP first and then ask for the desired value as discovered in the provided claim on following interactions.
Implementing this may be tricky.
Apparently Andrea Ceccanti has already implemented this before
Actually, Marcus wants to have an AARC specification on how to do this (is it already fine as is?)
WLCG has relatively general entitlements like “You are allowed to read everything below /Atlas/”.
We want to have the option to dynamically request a more specific file path entitlement from the OP in order to have a less powerful token.
So we want to ask for entitlements which would not actually be part of the original claim values.
{
“x”: [
“read:/Atlas/”,
“do whatever”
]
}
Approaches:
Scope request:
“x:read:/Atlas/run1/calib/*”
There are cases where the requests could get rather long.
Regex may help abbreviate this (include the “how” in the scope request):
Scope request:
“x:regex:something”
We also had a slightly derailing discussion on WLCG not guaranteeing group membership in parent groups when you are a member of a child group.
Next step: We will produce a whitepaper. Please inform us if you want to aarc-architecture@lists.geant.org (approved, it’s the right address)
SESSION #5, Breakout #2
Session Title: Rethinking eduGAIN Trust
Session Convener: Maarten Kremers, Pål Axelsson & Davide Vaghetti
Session Notes Taker(s):Peter Havekes
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
eduGAIN is built on inclusiveness, rather than trust. There is personal trust between the active federations, but What about federations that we do not see in real life meetings?
A (higher) baseline-trust is needed, without losing inclusiveness. This needs to be done in a federated manner, there should be no central certifying party. . Even the refeds specifications are hard to follow for less funded NREN’s
The bar could be raised in sections, to do more and faster.
A risk is that a direct connection (for commercial services) might become simpler than a edugain connection.
Marking some entities as ‘more trustable’ does not solve the trust issues in eduGAIN.
Federation operators can only articulate the requirements.
For service operators, the trust is simple, are the attributes correct, but the home organizations don’t want (or aren’t allowed) to send the users’ data to “untrusted” SP’s.Within a federation, there will be contracts and agreements. Inter-federation is harder.A institution has no way of trusting a sp in a different federation.
Can we think of a process to prove that all parties follow the guidelines and specifications, that works across all borders? Including some form of auditing process?
A balance between educating entities and full-blown audits is needed. Could this be a peer-review?
Two roles for the federation op: technical infrastructure and ‘policy checker’
Some federation op’s do training for IdP’s and services, but these aren’t mandatory. And not all federations have the time and budget to do this. We can’t assume all the world has the same standards.
The Metadata registration document could be a way to administer the trust-standards the federation operator uses, but a periodical check and training is needed.
This session was good input for future discussions and plans within the eduGAIN committee.
SESSION #5, Breakout #3
Session Title: OIDFed and Research Requirements
Session Convener: Niels van Dijk
Session Notes Taker(s): Hannah, Phil, Gyongyi
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Q from Scott: what progress is there in development to support OIDFed?
Neils:
- • Two OP products that are getting support for OID Fed: Shibboleth OP and Simplsamlphp.
- ○ Work is progressing; interop event in Finland.
- ○ For certain federations, promote OpenID Fed by upgrading their software to support it
- ○ Other federations, hub and spoke, use a proxy
- ○ For mesh like federations, provide a proxy or hub to support OPs that are not Fed-aware. Need RPs
- • RP OpenID Fed is looking bleak.
- ○ Maybe we need to create an adaptor that adds some OpenID Fed support to existing RPs
- ○ (Lots of people, including Henri) Author of mod_auth apache module openID (mod_auth_openidc) is adamant that doesn’t want to implement it at the moment. Not a cash issue, just doing too well.
- ○ Davide had the idea not to fork something like mod_auth_openidc but to add an adapter to it to support the federation functions needed.
- ○ Satosa has good support for OpenID Federation. Is what Roland used with his Python software stack to test OpenID Federation.
- • Two OP products that are getting support for OID Fed: Shibboleth OP and Simplsamlphp.
Christos: the research aspects.
- • Very clear that we will all be going towards OIDFed
- • Also clear that it won’t be available very soon (e.g. this year)
- • Expectation that the proxies will implement OIDFed but not the RPs
- • Eventual aim is that we can remove the proxy all together but eventually they may be removed when wallets are up and running and containing community attributes
- • Implementation within eduGAIN ongoing
- • EOSC Federation does not fully refer to authentication, it is also e.g. storage. However there is an urgent need for some identity federation with OIDC now. There will be multiple federations in the future.
- • The way forward in an ideal way forward would have one trust fabric layer.
Leif: can’t we use an existing infrastructure such as eduGAIN and use Key exchange in eduGAIN to bootstrap this?
Nieils: first place we want to do this is in the identity layer?
Christos:
- • We are creating a fractal (PS?). Multiple things can be abstracted so the identity layer can be common to implementations.
- • The other nodes are national infras or thematic infras. Requirement is that they have AArC BPA implementations. Common identity layer brings together all the IdPs and communities
Leif: the EOSC impelmentation so far seems much more low-budget. NextCloud or OwnCloud (it looks like)
Leif: Infrastructure proxy to connect single services. Mostly they are OwnCloud or one of the Dutch cloud service.
Christos: in April each node candidate has to provide an infra proxy that will connect.
Leif: but everyone just seems to want to offer Openstack (ie..a single SP behind their proxy)
Christos: Dutch connecting a few services for SSO, other countries are doing more complex things (PS, not exact).
Leif: No evidence to support a notion of connecting many services. More likely to see AAI work inside the next cloud instance.
Hannah: Each node is doing different things. Political push to integrate.
Leif: What is the actual usage / use cases: data sharing and sharing resources across borders. It effects: difference between building a thing 30 instances in a file sync share service and between different things.
Christos: Sees and shares Leif’s concern, but right now the requirements are to connect hundreds of services, and they need infrastructure to do that. Finalised on Friday and published this week. 30 nodes, connected via the hub and spoke model, our role is to provide openID federation to remove the hub and gain full trust between the nodes. OpenID Fed spec is not enough to support that, they also need token introspection, so we know what the token can do in their environment. Needs to split tokens across nodes, how do we do that (requirement comes from the research space).
Niels: Where do those requirements come from (to Christos)
Use case: research comes from a Spanish Node and want to access Jupyter service. Via the spanish node and fetch the date from the Dutch node. The Jupyter notebook already received an access token from the Spanish node and share it with the DUtch node. The Dutch node should be able to go back to the Spanish node to have the issued token validated. Token introspection is required. OpenID Fed is only the trust part.
Neils: Is aware of this user case. OpenID Fed is not just about OpenID Connect. You need an authorization federation
Neils: OpenID Federation can be used to establish trust between authorization servers.
Proxied token introspection and OPenID Fed are both required long term. Eventually we may be able to remove the proxies.
Mads: what is required by researchers: not only the access to the infrastructure but to get access to the data. To be able to have access to data controllers… Is it inside the scope that we are asking in this session?
Leif: data will not move, the workload will move. Than it is in scope in WIMSIE standard.
Licia: the EC asked all the different country nodes (30) for requirements they are filtering down.
Christos: reporting on what we’ve been asked to report.
Neils: are you saying the EU are giving you detailed requirements on token introspection?
Christos: EuroHPC case they move data. EuroHPC platform: the researchers should be able to go to the portal and select resources.
Mads: The real problem is that almost all HPC site has no preparation for data protection. The problem is how to get access to the data? And the trust relationship between the HPC infrastructures which still needs to be built.
Leif: Is this being done today, is that CILogon.
Scott: OSG and Pelican and some others are doing this today. Use case is getting data to the GPUs and they use a lot of tokens to do it. (Maybe this is solved by some)
Mads: moving the data not important, how we move the data and how we track that is important. Moving data is the HPC problem, so here we need to decide on access granting and trust relationships.
Neils: there is a more generic scenario about how you manage authorization
Christos: practical side, in the next few years what can we implement.
GO69 (group syntax) will be used for EOSC cases.
Can I publish my URLs so that other people can trust it?
Leif: what about REIF?
Neils: you need a trustworthy way to publish that (PS, the namespace identifier?). You want to stick that identifier on institutions to help make authorization decisions (bit like trust_marks).
Christos: yes that is interesting, but right now: you want to create a project, text box to add URN namespaces.
Neils: thinking about something similar in eduGAIN PoC. Have trust mark issuer (TMI), trust anchor will trust the TMI, but it is up to the TMI to issue whatever they want (trust anchor, eduGAIN for instance, just trusts them to do that correctly). Trust the onboarding process by these federations is of sufficient quality, then you can use this…for trust (PS, did not catch that specific example University Alliances, ELIXIR, Erasmus+ entities).
Christos: if we have the trust fabric we can label them that I want this.
Niels: the mechanism would remain the same.
Hannah: two other research user cases which are easier: each middleware has a list of trusted issuers (static list) and OpenID Federation can help with that (we missed EU Grid PMA serving a list of trusted issuers – need to add this back in), each middleware has done that themselves). OpenID Fed will help, do not see blockers.
People are really hesitant that AAI is a blocker because of the proxies..Having a redundant set of tokens maybe a way forward
Christos: local authorisation scalability problem. ATLAS project will have 10 authorization servers set around the world, it is within the ATLAS domain. If between trust domains then it is OIDF makes sense as it is between trust domains. Then you need a trust fabric where OIDF can help.
Neils: Then your black to your problem, a number of sites are making statements and you need to know who to trust in those cases (not all in the same domain). OpenID Fed can help with this trust, bit you will need a profile to make that happen.
Christos: But you can use a local fed to manage trust, and then have redundancy by using more than one issuer (or auth server etc).
Leif: if you have 10 issuers, treat them as an internal federation.
Neils: Christos use case, and mine in the eduGAIN space have some overlap, but trying to understand what overlap. Christos is building an authorization federation eduGAIN is building an identity federation. Some things are the same, using trust_marks to identify OPS and RPs (in different ways). Your authorization use case needs to be encoded in the spec in some way.
Christos: building a trust federation and on top of that build an authorization federation.
Niels: we need a trust fabric which is the ecosystem where both trust federation and authorization federation are.
Organization onboarding – they need a technical… couldn’t catch more.
Leif: gets a 6th sense that there is a 2 part validation here. Key validation, only care about a bag of keys. Then validation of the token contents itself – which is so application specific. Maybe we should solve the roots of trust issue. We tend to end up needing a list of trusted roots.
(PS, brain exploded). Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
SESSION #6, Breakout #1
Session Title: Supporting EU University Alliances / Student Mobility
Session Convener: Peter Havekes
Session Notes Taker(s): Gyongyi + Maarten
11:35 – 12:25
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Peter:
There are around 60 University Alliances (UA): orientation, enrollment and taking courses at different universities. SURF supported two dutch national alliances and based on that got the request for the european alliances. SURF has supported so far 2 Alliances (EuroTeq, Aurora). Using standardised APIs and OAutH.
Project it to the European scale.
There are 7 universities working on automated enrollment.
[Add the link to slides here.] Peter Havekes
Components:
OEAPI (Open education API)
SURFeduhub
eduXchange (fetch information from SURFeduhub and send information to edubroker – OAUth token exchange.)
eduID
Subscription and result broker
SURFconext
Missing components on European scale:
eduID
SURFconext
Christoses solution: MyAcademicID / eduGAIN…
Pal: is the ESI used?
Peter: no there is no needed.
Authenticate in the Home institution.
Pal: it would be a good idea to use ESI.
Peter: would prefer to avoid an extra identifier.
What is the difference between ESI and the current way of authentication used by eduXchange?
eduGAIN one of the entity categories you can subscribe for is the ESI.
Maarten: netherlands have national and european alliances of universities. By using standardised APIs can simplify the processes.
OEAPI and EWP could converge… as the processes are similar.
We should have a role in this.
Pal: it is not only the question of trust but also convening the data.
Sweden: one university is handing the technical aspects for federated login to identity the user. That UA have one system (enrollment, course catalogue…etc). From the student perspective it is very comprehensive. Local universities has to get the data synchronized with the local SIS.
Legal challenges: home universities are the one who finally issue the diplomas.
Pal: the framework is different between Erasmus+ and the UAs.
Francesca: who is giving the degree the home institution or the UA?
Peter: host institution is giving the final degree and the UA giving a certificate.
In the case of joint programmes there are the involved universities giving out individual academic degrees.
Technical challenge is to connect the different systems between the alliances / universities.
Gyongyi the potential way forward it to mapping the different systems and requirements for the users.
SESSION #6, Breakout #2
Session Title: Token exchange vs Proxied introspection
Session Convener: Christos, Pieter
Session Notes Taker(s): Hannah, Marcus
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Use case:
Service A is a jupyter notebook that wants access to Service B which is a storage element. They are behind different Authorisation Servers.
Leif: There are two specs in this field:
- • WIMSY (?not sure if spelled correctl)
- • GNAP (Grant Negotiation and Authorization Protocol, “oauth3”)
Why can’t we use standard OAuth2?
- • S A is not trusted by AS B -> token exchange is only supported between services behind the same AS
- • Why can’t the user get a token for both S A and S B?
- ⚬ User is not known by AS B
- ⚬ SA is not known by AS B (is not a client)
- • One solution could be a dynamic registration of SA to AS B
Leif: maybe we can just have a bag of signing keys that are trusted. Everyone trusts these.
How would you manage access control?
There would have to be an agreement on the format
A compromised client could have a LOT of power in this scenario
Way ONE of solving this: we put an STS (secure token service) in the middle?
This is similar to the approach in EOSC. There is a connector above both AS that trusts them both.
Could the STS serve a trusted list of keys or endpoints (a la PKI)
STS could be implemented on AS B directly.
Whether or not putting STS in the middle or on a specific AS is another discussion
Could the middle be replaced by a trust list and an API
Why can’t SA and SB just be behind the same AS?
This isn’t always practical
People are resurrecting XACML in the AuthZen group
We have two ways of doing this::
- One AS talks to the other (STS)
- WIMSI Proposal? AARC work?
An immediate use case where we need a solution is EOSC.
EOSC Infra 1 call already includes all the people who are involved in the work, plus some others.
Leif: not sure that this has anything to do with OIDFed. There are no trust mark requirements
If we only need a flat PKI perhaps OIDFed is too much.
Way TWO of doing this is the proxied token introspection.
- AT A is sent to SB
- SB sends to AS B introspection
- AS B thinks “this isn’t from me” and looks for where it was issued.
- AS B sends AT A to AS A and returns it to SB (potentially modifying it somehow)
AS B must be a client of AS A
A disadvantage is that this may cause an error to be known about later. In the initial case (where both tokens requested at the beginning of a user flow) the user will be more aware of whether things will fail.
For Token Exchange will it all fail if AS B does not know about the user? Probably yes. Same argument for groups and roles etc.
Good argument for using something like SciTokens where the profile of the tokens is very well defined. Being discussed in the GUT working group
(brain meltdown… )
Lengthy (and wild) discussion about the details of different approaches (proxied token exchange vs proxied token introspection.
Quote of the day “PLEASE STOP!!”
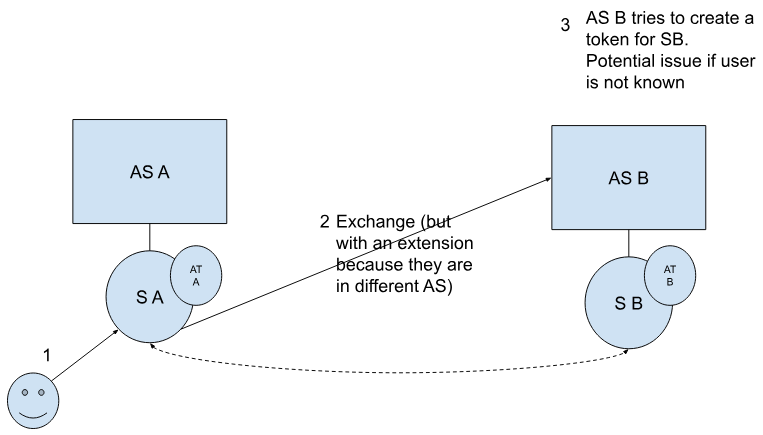
Look up the GNAP protocol…
STS needs to trust the signature of the token issuers.
STS needs to be a client and an AS of all the other AS for this to scale.
The token endpoint of an AS is highly complex. Difficult to modify. 2 years ago it seemed to complex to change the token endpoint rather than the exchange endpoint.
In Keycloak the exchange endpoint asks for the issuer, this might help but potentially S A does not know.
Keycloak Exchange extension (loose interpretation of the protocol): In the initial OIDC flow the client says I need a token that will be used for S B behind AS B. It assumes that AS A is a client of AS B.
Standard exchange assumes that the clients are connected to the same AS.
SESSION #6, Breakout #4
Session Title: VCs + eduID, wallets what’s the point
Session Convener: Niels van Dijk
Session Notes Taker(s): Marlies Rikken
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
VC – what is it.
A statement about a subject where the statement can be verified because it has a statement and ‘some signatures’ about the statement itself.
Subject = humans.
SAML the signatures comes from IdP, eduID, ‘issuers’
VC is NOT attributes. We have many attributes. Some derived from LDAP schema’s.
Attribute bundles, entity categories, are subsets of existing REFEDS attributes/objects.
Making an eduPerson VC with ‘everything’ in it is not what we want to do. Most eduperson attributes not used.
Combining more specific attributes makes more sense to combine into a statement
Why is bundling attributes in a VC better than asking for separate attributes?
Same entity makes the entire bundle, make it into one.
Potentially more familiar to the user where the VC bundle comes from? But also possible for separate attributes.
Set of standardised claims/bundles. More like real world ‘cards’ (example, info that is on passport)
Same data structure, same credential type. The verifier will ask for specific bundles.
Should keep the amount of bundles limited. Standardise them in our field.
Should be semantically understandable what is in the VC.
Example: an open badge.
Work is to identify use cases and which VC sets (attribute bundles) are good.
Need to agree on names that are globally unique and contain the same claims.
Context problems: when the information is available from multiple issuers and the user has to choose.
REFEDS white paper is being worked on for this topic. Mapping of names between schema & claims is similar to work we need to do for SCIM.
What is the point with wallets & eduID?
What is a wallet
A place that holds
eduID.se does not hold data other than the identity – possibly
eduID NL does hold affiliation, no openbadges – focus on being a login method
Subject ID create an issuer credential
Re-use the identity from the authentic source
Include ‘something else’ as identity
eIDAS and PID – each member country should have something unique.
Hard problem:
Loggin in with IdP into badges gives a pseudonym. Hard to give out badge to people.
Potential solution: have the person with the eduID sign up to the course with eduID – not ONLY at the point of handing out the badge to match the person to the badge.
Badge bound to wallet – but what to use to claim the badge?
Claim binding strategies that are possible: get your stuff from the same wallet. Needs to issue the badge from the same wallet
Identity from govt wallet, but badge in another wallet.
Identification (often??) necessary when sharing VC bundles, at least in the example of a badge.
Proof of age credential
Show that the badge is not fraudulent. And show that it belongs to you.
Theory is to have a standardised method for exchanging credentials.
Currently you do a log in – with a basic set of credential. Backchannel for additional information. Potential to give other information via the wallet.
More information about the wallet spec and which option for linking identity it will have is still being defined.
SESSION #7, Breakout #1
Session Title: Passkeys
Session Convener: Phil Smart
Session Notes Taker(s): mifr@sunet.se
Tags / links to resources / technology discussed, related to this session:
Interesting EAP-FIDO implementation to enroll your iPhone’s FaceID as your authenticator, e.g. for eduroam… https://glauca.space/@q/114171393361161218
(and see https://github.molgen.mpg.de/q/eap-fido)

Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Different kinds of passkeys. Hardware of software. Problem with attestation. Especially with software passkeys.
A problem with synchronization of passkeys, is that the level of assurance can differ per device it is used from.
A difference between the big tech solutions, is that they cater to the consumer use case, users protecting their own data. In our case, it is usually institutions protecting their data, and granting users access.
Many different ways to use passkeys, hard to recommend a configuration.
Zacharias tells about passkeys in eduID. Written in python
EduMFA, privacyIdea copy. Passwords first or passkeys first.
Advantages of passkey first: you cannot hammer passkeys, and you don’t teach users to enter their password in any form that asks for them, just like that.
Disadvantages: users are used to type in their username and password first/together.
Passkeys in password managers, please don’t, because both factors are stored in the same place.
Passkeys added as a second factor. Not using passkeys instead of passwords.
Björn tells about Duke university with username + passkey as first factor and password as second factor. (https://oit.duke.edu/service/duke-unlock/)
Passkeys are better not using passkeys, for instance totp.
Hard as verifier to know what kind of trust to apply to the key received.
Problematic with software based passkeys that they lie.
CloudHSM, trusting apples account security.
Why are we using passwords first?
Shibboleth and eduMFA implement it as separate plugins with username+password and passkey
Use a flow with a separate username step.
It might be possible to enumerate usernames when using passkeys first.
Usernameless is not supported in shib idp. Need conditional UI support.
Most deploys use phone software passkeys.
Why not use a combination of a passkey and MFA app? Or another solution to go passwordless?
Platform lock-in and fights between vendors hinder adoption.
What recovery process do people use with passkeys?
- • One that always works is slow. Contact support and delete passkey for account.
- • National authenticator / BankID as recovery
Apple might have attestations on passkeys on managed devices.
https://support.apple.com/en-gb/guide/deployment/depf72b010a8/web
SESSION #7, Breakout #2
Session Title: How to (en)wallet core AAI
Session Convener: Christos, Leif
Session Notes Taker(s): Alex
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
LJ = Leif Johansson
CK = Christos Kanellopoulos
SL = Stefan Liström
MW = Michelle Williams
CK: how we do things today with research community. How to get information that’s not provided by home org? Community AAI! What we did was simplest possible: make it look like an IdP, put in front of actual IdPs & get extra information in the same flows that we already use.
Not he bst
- – Double discovery problem
- – Confuses users often
Want to move outside of login flow & explina UX we provide.
- – Use myaccessid to login & manage identiy
- – There have a profile; in user profile “click here to bring your collaborations” and see a list of collaborations. Already know which IdP so can select community & do SSO & bring back membership info & refresh token for later use.
Change narrative: user brings identity & adds
Looks like wallet! So
Peter Leijnse we won’t need MyAccessID
LJ: Might still want issuer for common identifier.
CK: have codebase wwwallet
LJ: consider wallet as a profile store
SL: today split into 2 roeles
- – Issuer, Responsible for attribute (looser or tighter coupling)
- – Wallet itself
GH: coreAAI part of verification process?
CK: let’s do that later
IdP; Community AAI: both issuers
LJ: this.js as a way to populate (some type of) credentials “base academic credential”
Discovery flow through S/A optionally populate the IdP hint into the wallet. Next time, go through the VC API and the RP knows … short circuited the home org … similar through Community AAI
CK: how we do this without … in 1 month from today. SAML from IdP, OIDC from community AAI
LJ: this is the issuer!
CK: CoreAAI collates .. same info, same wallet.
LJ: backport some stuff, been using for DC4EU
CK: Can we provide nice UX?
LJ: People liked the look
CK: I’m talking more about experience; EOSC starting up
SL: nextcloud?!
CK: bunch of services from my PoV
SL: eduID.se to be an issuer to wwwallet to access NextCloud; so s’one use CoreAAI to gather credentials, …
CK: we willproxy to what they understand
LJ: in the longer term, can’t use intermediaries; can use now in our environment
CK: so get the experience in our environment
??: you reduce complexity in your federation, and manageable from an introspection pont … make a decision aout authn.authz … now we push it in to the network, now we invert the flow.
CK: Crazy idea coming up: eduID put stuff in wallet; assumed user provisioned into origin of wallet. If you don’t have wallet, experience will looks similar.
LJ: why care?
CK: it’s the experience
LJ: only a problem if a mobile only solution; there is no need to build a fallback ‘cos browserbased is fallback
CK: v diff go to EOSC and say everyone use this now
LJ: we did this with discovery, and didn’t …
CK: build into
LJ: ur trying to make this harder tan it is. wwWallet is another website
CK: but can just download app
LJ: Nope. It should look like … we should give you stuff. Send to somewhere to get that credentials, which appears on the website, things not decided yet
CK: want to have on MyAccessID at this time
SL: MyAccessID act as both issuer & wallet,b ut that would be a mistake; breaking design pattern, easy to underestimate what a wallet is. Issuer is collector, not the carrier.
CK: TO be clear: everything accessible through wallet, but in 1 month EuroPC will get stuff from MyAccessID.
LJ: Services talk to NyAccessID, obv to put it there today. Set a cookie on the browser … have you switched to wallet
CK: Yes!
LJ: Once you;ve gone through the process, set a cookie. We do this in S/A when you turn on a new feature set a “feature cookie”. Basically feature negoationa between browser & S/A. COld be fore A/B testing, or feature discovery.
LJ: talking to SIROS and Chrome team. They will probably introduce specific workarounds for specific origins. They will whitelist origins.They don’t have app store control. Will recognise that there will be an enrollment flow into the wallet.
CK: Want your expert advice. Can we steal UI of wallet?
LJ: NO, probably not legally, we want independence from the issuer. So the owner feels happy to release. Mixin UX signals dangerous
CK: Back to original point. Do we want to add features
LJ: don’t want to give users a wallet-curious experience in MyAID, you would be dangerous you would tell users you have control, but some would scratch it and might get . Be careful about privacy promise to the user
CK: of course
LJ: YOu want to stay clear of that. There’s a legacy, there’s that.
SL: What would CoreAAI look like as an issuer? With issuer-specific UI. So once user flips switch, looks same on issuer, don’t log into an get profile, just get into profile.
LJ: you get two credentials .. “you could issue to wallet and don’t do again in future”. It’s “skip this step in future”
Still look at verifier from MyAccessID
LJ draws picture from left to right
- Verifier and issuer colocated
- In future, add wwwallet
CK: And they go directly there, the issuer is used once.
SL: doesn’t user start at the verifier?
LJ: looks like classical consent screen
CK: Add to your wallet if you have one
PL: just what we’re going to do with the Dutch eduID
SL: Practically work with use cases after Summer
LJ: we might not use through verifier, could still use it as an issuer
CK: This is great. Thank you very much. This is everything
MW: Could this extend beyond academic use case?
General agreement could repeat pattern
MW: policy & decision-making?
CK: I was thought the verifier would be something 3rd party, Leif killed this
MW: thing drwaing on bard yesterday has gone?
LJ: Yes if in eEIDAS legal regime,
SL: Could use but don’t want to, don’t want 2x ways of doing something
CK: under reposnsibility of service
MW: sound goods. If we can’t interrupt flow, no-one else can
CK: Problem might want to build a verifier & a service comes to us and asks for verifier (AS not sure here)
LJ: Wouldn’t pass inspection ‘cos each country has oversight.
CK: I have platform. I provide a verifier on platform. I provide tech
LJ: No sure you would be given access certificate
PL: might be possible
SL: this is why eIDAS tries for complete unlinkablility
CK: as an ethical vendor I could do this
SL: definitely ppl looking into business models of being issuer or Verifier, not really wallet
PL: doctors’ practices in NL, serviced by one party, some multi-tenant offering.
LJ: As long as a legal boundary, you might get away with it
CK: New opportunities for business?
LJ: Look at OIDC today, Keycloak etc, I suspect they will develop wallet capability
SESSION #7, Breakout #3
Session Title: Microsoft Entra
Session Convener: Martin van Es
Session Notes Taker(s): Peter Havekes, (plus Jon Agland hanging in here)
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps
UK federation our page pretty much exists because of Entra-ID – https://www.ukfederation.org.uk/content/Documents/ProxyingIdP
Links to Microsoft’s guidance in there, that explain they don’t support multi-lateral fed (from an IdP perspective)
https://learn.microsoft.com/en-us/entra/architecture/multilateral-federation-introduction
External authenticator MFA asked by SURF:
Even more difficult to get out of the Microsoft ecosystem, APIs, just get your tenant here and to stuff here. Hotel California (The Eagles) “check out but you can never leave”
Peter can share about what SURF has bumped their head into… Orgs migrated to Microsoft and services, and own services, own service in Azure infra, or Office 365 and to own users/identity, and then to external guests. Whatever license you want. Really want to federate with eduGAIN. Example of SURFconext is hub and spoke federations.
Actively trying to support by supporting working against you to find a solution.
Two different problems: Entra as IdP and Entra as SP (MS365 access)
Problems with full mesh federations. Individual imports. A proxy can help to translate SAML to SAML, and map attributes.
MFA in entra is a big driver to migrate to Enrra in several federations
Is the fight worth fighting?
Current geo-political state, and whether that has an impact?
Google and Microsoft have done so well, so alternatives have died.
Data more safe and protected from other parties is a concern . even data stored in a ‘local’ cloud can be affected.
Can email be moved away from cloud providers? Is it still possible to run a own mail service of a federation scale? Will the ux suffer? The French NREN is running running a mail service.
The federation(s) needs killer features to stay relevant
Some points about “Cloud” IdPs like entra-ID in a full-mesh federation (might be useful, using these to UK fed participants)
- • Doesn’t support SAML encryption by default
- • Doesn’t have the ability to consume federation metadata
- ○ Doesn’t verify the signature of SAML metadata
- • Required for compliance with our trust-model
- • Doesn’t preserve user privacy
- ○ Sends attributes containing Personal Information by default
- • Doesn’t support the eduPerson attributes required
- ○ (or the new SAML subject Identifiers)
- • Doesn’t allow you to configure the entityID (vendor lock-in)
SESSION #7, Breakout #4
Session Title: High-level risk assessment
Session Convener: David Crooks
Session Notes Taker(s): Liam Atherton
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Context: Continuation of meeting at CERN in Feb with Hannah, Experiment sysadmins, EUGridPMA attendees.
How do we implement security controls for tokens in a useful way? One of the suggestions being that if we take a risk based approach we can see what controls we need. So, is there some headway we can make on doing a useful risk assessment?
We should start by taking time to consider what is in and out of scope. There is a lot of infra used by WLCG OPs so we need to set the boundaries. This is a multi-dimensional consideration, there are robots/users/admins.
There are 2 approaches to risk assessments
- Assets first
- Threats first
If we do threats first we can tie this closer to what the experiments want.
Are we only talking about WLCG, there is an urgent problem here but it is a restrictive way to look at this?
- WLCG is a good example and viewing point to do this.

Scope
- • 4 x LHC
- Data management
- Job execution
- • Low sensitivity data
- • User & experiments
- Community AAI
- Downstream services
- • Connected external activities
- • 4 x LHC
Primary assets
- • Experiment data -> research results
- • Distributed computing ecosystem
- • Well-structured research community (the people)
- • Societal visibility / Reputation
Threats:
- • Large data loss e.g. user deletes all data
- • Data theft or loss of integrity
- • Storage of illegal data
- • Resource misuse (e.g. coin mining)
- Misconfig
- • Threat leakage to other experiments
- • Inappropriate authorisation
- • Inability to have supported software
- • Danger of self-developed software being vulnerable
- • Internal environment forces insecure operation (forced by management)
- • Inability to interoperate without custom solutions
- • Compromised entity (user, issuer, service, site, token)
- • Malicious insider (token manager or site admin)
- • Lack of commensurate and proportionate response capability
- • External tech advances e.g. protocol becomes vulnerable, e.g. quantum
- • Loss of availability of issuer
- • Inappropriate security architecture
- • Loss of funding
SESSION #8, Breakout #1
Session Title: Lobbying for FIM
Session Convener: Andreas Klotz
Session Notes Taker(s): Maximilian Brinkschulte, Sander Apweiler
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
How do we find software vendors to make changes to our liking?
For small institutions it’s hard to get heard. Grouping multiple small institutions to a larger group might give a better voice. E.g. 40k users instead of 2k.
Software vendors often do not see the benefits for their products/say it won’t fit to their plans.
Can we create guidelines as a community to convince vendors to implement our standards?
What is a software vendor? There’s a difference between start-up and commercial companies. The more these companies depend on your budget, the more influence you have. It has to be to their economical benefit. Different strategies are needed for the different types of software vendors. E.g. A project with regular (small) payment can be interesting for a start-up but not for big companies.
Maybe we need to start using our big names in research. E.g. Cern or Internet2 for US universities, …
Another possibility is to use personal relationships (CEOs went to Universities as well …)
Can we use community feature requests as a pressure point? Could work if we organize.
Can we standardize our needs? It can be worth the effort; standards could convince even larger companies to adopt their products.
Do we maybe lack organization? Universities have big players/ budgets. Research institutions/budgets are more scattered.
Can we certificate vendors?
SESSION #8, Breakout #3
Session Title: Do we understand what a credential is?
Session Convener: Peter Leijnse
Session Notes Taker(s): Stefan Liström
Tags / links to resources / technology discussed, related to this session:
Heather wrote this about verifiable digital identity credentials
Digital Credentials That Can Be Verified: A Lesson in Terminology
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
Credentials need to be portable across different media, e.g. both a wallet and a USB-stick
Credentials are much more than just digital information
It needs to be possible to examine and verify them, they do not have value otherwise.
The EUDIW seem to have many limitations on what a credential can be and which credentials can be put into the EUDIW. We need a broader view on what credentials can be and who can evaluate which credentials are “good” or “bad”.
Do we have to do things better when we move a physical credential into the digital domain?
We need to keep the same possibility for the verifier to evaluate a digital credential in just as good ways as physical credential.
Digital credentials have a higher risk of being manipulated and used at a higher scale.
Physical credentials are usually represented in its entirety, i.e. it is self contained and includes all the information the verifier needs. Digital credentials can be dataminimized and sometimes several credentials can together include the complete information the verifier needs.
Each credential is an “authorization thing” to let me access a certain set of resources.
External links to information needs to live for a long time of the credential is supposed to have a long life.
Important to think about what we put in the credentials, is the information really necessary.
Extracts from sheets:
Some ways to categorize credentials:
- • The value they represent
- ‘identity’, ‘money’, ‘qualifications’, ‘skills’, ‘membership’, …
- • The ecosystem that creates them
- ‘education’, ‘travel’, ‘finance’, …
- • The ecosystem functions that benefit
- ‘payment’, ‘enrollment’, ‘sales’, ‘certification’, …
- • The information they contain
- being a student, being 18+, being a qualified professional
- • The technical representation they have
- Paper, electronic card, badge, digital credential, …
- • The container that carries them
- Physical wallet, frame on the wall, pocket, digital wallet, smartphone, web locker, …
- • The size they have?
- Micro, meso, macro; nano, micro, kilo, giga; lamda, micro, nu…
- • The value they represent
Educational perspective:
- • smaller units of learning (‘microlearning’) create flexibility and relevance
- • credentials may make the internal structure of large programs more explicit and allow for variation
- • credentials can be the ‘fuel’ for mobility and exchange, for reskilling and upskilling (‘recognition of prior learning’)
- • credentials enable learning paths beyond the boundaries of educational institutions
- • credentials must have recognizable value outside the education system
- • diplomas are credentials by definition
- • education seems the largest consumer of educational credentials
- • uptake of (micro)credentials seems highest in ‘new’ application areas
- • credentials are not yet widely used to streamline existing educational processes
Infrastructural perspective:
- • Digital native and digital first are the norm
- • Everyone is in digital transformation
- • Target audience for education is adopting new technology fast
- • Digital credentials fit in the broader trend of self-sovereignty and decentralized systems
- • Educational credentials should not be too dependent on particular technology
- • Infrastructure enables, but does not execute the transformation, (use the enabling power)
- • ‘If it fits in the container, infrastructure can support it’
- • Infrastructure can provide the technical trust, but not the truth
- • Multiple competing infrastructures and standards
- • Multiple trust ecosystems (cross-national & cross political blocks)
Information systems perspective:
Two very similar processes, both dealing with learners, accreditation, recognition, etc:
- • the diploma track – very established, but also tied to ‘old’ practices;
- • the microcredential track – innovative, promising, but not yet carrying the weight to trigger a wholesale overhaul of educational information systems.
Both have in common the need for capturing valuable information from educational processes, ensure their quality and share with learners and society
How can we combine both approaches to create future proof educational information systems?
- • Build parallel systems?
- • Leverage old systems?
- • Migrate to new systems?
Mix and match?
SESSION #8, Breakout #4
Session Title: Endpoint capabilities to support incident response
Session Convener: David Crooks
Session Notes Taker(s): Liam Atherton
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if appropriate to this discussion, action items, next steps:
What are the tools we can implement on the IdP side to help the IR process that would be available for use without building a whole process around them? Marcus had a suggestion, would it make sense that there could be an endpoint for responders to help contain malicious activity.
??What tools can we conceive of in the background so that when we need them they have been thought of??

Discussion became around
- – Endpoint capabilities that could help incident response
- – Introspection point for security teams to obtain user details based on possession of a token
- – Endpoint capabilities that could help incident response
- – Endpoint capabilities to help contain malicious activities
- – Blocklist
- – Security Event Tokens
- – Endpoint capabilities to help contain malicious activities
Ultimately, the discussion ended in the finding that implementing changes to support (eg) SETs has to happen across broad community(ies) to be fully useful. Note that resources are constrained – and may well need to be focused on operational functionality without broad acceptance
Even within one community, likely that implementation would need to take place in multiple places/softwares
Focus on human sharing of intelligence supported by technical means like MISP
Mention of SIGNALS working group (I think https://openid.net/wg/sharedsignals/); potential for work on this to continue in the background at a slower cadence as the community moves forward.