SESSION #1, Breakout #1
Session Title: eduID and Interoperability and the Problem of the “Travelling Scientist”, Who Changes Affiliations Over Time
Session Convener: N/A
Session Notes Taker(s): Bas Zoetekouw, Fredrik Domeij
Time keeper: N/A
Time: Wed Feb 11, 10:45
Location: Colloquium
Tags / links to resources / technology discussed, related to this session:-
- – MyAccessId
- – ORCID
- – AAF (Australian Access Federation)
- – eduID (various national implementations)
- – GDPR
- – EuroHPC
- – Session on “eduID Discovery” (Mischa, following day)
- – International steering committee on eduID (Ines, SURF)
Problem:
-
- – People moving from one institution to another: how do we know that these two Peter Muellers are the same person?
- – Multiple federations are setting up an eduID for life-long identities.
-
- – MyAccessId:
Christos: MyAccessId was set up exactly to solve this “moving institution” problem. It starts out from the institutional identity and allows connecting a new identity at a different institution (possible in a different country). For research in Europe this is now being implemented: everything connected to a central proxy.
- – Wallet Paradigm:
The wallet paradigm will totally change this landscape: wallets should solve this.
- – eduIDs:
EduIDs work differently in different countries. German one is a proxy for other IdPs, Dutch one has internal accounts with separate credentials.
- – ORCID:
In research, ORCID is the “default” identifier. What is then the added value of an eduID? EduID has broader use cases beyond research. Assurance is key; ORCID doesn’t offer that.
- – AAF (Australian Access Federation):
Astronomy in Australia: people discourage using AAF-identities, because it is not stable enough. People are pushed towards Google.
- – Regional Solutions:
Fredrik Domeij: In Sweden, people can use government identity. But that’s not enough: we need to combine information from different sources. Their eduID handles the linking of the different information sources.
- – Requirements:
Christos: Requirements change in different environments. Can we come up with a “transferable identifier” that can be moved to a different domain or environment.
- – Composite View:
Assemble a composite view of different parts of data to give the correct “view” of a person’s data in a given situation.
- – Account Linking:
Service providers and proxies can easily do account linking (in principle), but in practice this is hard (for example, because people lose access to the old account before getting access to the new one).
- – Service Provider Perspective:
Arthur: Can we look at the problem from the perspective of a service provider (or Proxy) and can think about as a service provider in higher education or research we are aware that users are moving around and can issue the person behind the user a hand-over-password (“recovery code”) so if this person is coming back later with a different university identity, they can resume their account/work in my proxy/service. So solve this problem from the relying party and not from the IdP direction and putting the user in the center.
- – Government Identities:
In Denmark they are slowly moving towards using assurance and identity from government ID systems. R&E federation then needs to shift to a “affiliation federation”. The Danish government will also hand out government identities to foreigners.
- – Wallets:
“Wallets will solve all problems”. (maybe) (in 15 years) Can we do anything to speed this up? There is too much hand waving. Wallets can be easily integrated in other solutions like MyAccessID or eduIDs. Also, we will still need to support SAML etc.
- – MyAccessID:
MyAccessID will solve assurance problem by requiring passport verification for all users (for EuroHPC).
- – Common Identifier:
We need to be careful to define what we need: do we actually need a common identifier for everyone? It seems we only need a long-term stable identifier (that might differ for different SPs). Also: we should not want this (GDPR).
- – Domain-Specific Identifiers:
One identifier still does not “solve” the problem, because that identifier/identity protocol will not likely be usable by all systems that need to identify users. That points back to account linking and some semi-collective knowledge of a subset of identifiers that points to the same user. How can we get away from a global identifier, and move to domain-specific identifiers, where the domains can be dynamic.
- – Account Recovery:
How to handle account recovery? This is a hard problem.
- – MyAccessId:
-
- Mischa will have a session for tomorrow around “eduID discovery”.
- Ines (SURF) is coordinating an international steering committee around eduID.
-
- How can we accelerate the transition to wallets?
- How can account linking and recovery be implemented in practice?
- What would a dynamic, domain-specific identification system look like?
SESSION #1, Breakout #2
Session Title: What Federated Collaboration Models/Modalities/Business Models (UX/UI) Are Desirable?
Session Notes Taker(s): Andreas
Tags / links to resources / technology discussed, related to this session:-
- – GRID/Federation
- – Wallets
- – Login with Google/Facebook (as UX reference)
- – Payment federation models
- – Government identity systems (Germany/US/EU)
Background:
-
- – Craig has been in the game for quite some time with GRID/federation
- – Adoption has been relatively slow, especially in the US
-
- – virtual administrative domain?
- – A way how multiple domains can work together (common agreements/governance) while remaining independent
- – Forming a cohesive community
- – Being a user in a federation vs being the governing level of the federation
- – Users can again be divided into two groups: Service Providers and End-Users
- – Being part of a federation can be a pain as a user, (e.g. due to having to accept all kinds of policies)
- – There are already federations which work quite well (payment, government (Germany/US/EU))
-
- – How can we better hide the complexity from the users?
- – End users should not be aware of the federation
- – User surveys: what do you use? What do you like? (Or maybe focus groups instead of surveys)
- – What to handle UI/UX; users will gravitate to easier UIs/UXs
- – UX in context fed will require more attention
- – How to estab trust throughout entire transaction as part of UX
- – De/Increase(?!) opacity (of all the proxies in between)
→ Maybe more complex legal frameworks are required for that? (if we do that, we need to limit the scope of the frameworks very strictly)
- – Delegation needs to be transparent though
- – Delegation as part of the UX
- – Wallets may help in this regard
- – Authentication should be as easy as “Login with Google or Facebook”
- – Balance between centralisation and decentralisation – parties also want to/need to have some amount of autonomy.
- – Our user experience should be as good as the payment transaction experience
- – Why do we share user interfaces to people who do not know who we are?
- – Is user consent really consent (do they have a choice?) – but we still have to present them with something to inform them
SESSION #1, Breakout #3
Session Title: Designing an Educational Identity VC
Session Proposer: Niels van Dijk (SURF)
Session Notes Taker(s): Gyongyi Horvath (GEANT), Phil
Tags / links to resources / technology discussed, related to this session:
- – Slides
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
Notes:
- – SURF is running an edu wallet project. Actively testing and piloting wallet technology together with the institution.
- – Feedback on IDs required.
- – Verifiable Credential can be transported via a Wallet, or directly (or mechanism)
- – Digital Credential Query Language (DCQL), pronounced DuckL?.
- – Wallets add value, but will not replace our current technology stack. So need to combine the two.
Statements from the presentation TF;DR
An education identity verifiable credential:
- – MUST obey to minimal disclosure by design
- – MUST NOT contain identifiers in its claim values
- – MUST only support selective disclosure capable credential formats
- – SHOULD include claim lifetime considerations
- – Leverages capabilities of Digital Credential Query Language (DCQL)
- – Provides assurance information by default
- – Has schema consistent over credential types and protocols
- – Both the technical and the usage perspective.

-
- – Representing Educational Users in the Wallet Ecosystem:
There is a clear need to represent educational users in the wallet ecosystem that goes beyond the government credential (PID). The vast majority — 80–90% — of educational use cases do not require the high level of assurance that government use cases demand.
- – Government vs. Educational Policy:
Government and educational policy do not always align. Uptake of eIDs varies significantly from country to country and remains generally low across the board.
- – OECD Identity Definitions:
The OECD distinguishes between a functional identity system and a governmental (foundational) identity system — a fundamental design principle that underpins this discussion. For further reading, see the EUNIS 2024 preconference presentation.
- – Role of NRENs in the Wallet Ecosystem:
The question of what role an NREN should play in the wallet ecosystem remains open and is being addressed in a dedicated separate session.
- – REFEDS as a Foundation:
The basis for an educational identity ecosystem should closely mirror what REFEDS does (https://refeds.org/category/personalized) — but with a twist: the model would need to accommodate additional affiliations beyond the standard REFEDS framework.
- – Representing Educational Users in the Wallet Ecosystem:
-
- – Credential Lifetime and Updates:
Wallets cannot update credentials themselves. Credential and claim lifetime is therefore critical — to check validity or revocation, the wallet must contact the issuer directly. No current standard defines how to update a user’s credential within a wallet; a new credential must be obtained from the issuer each time.
- – Issuance Time vs. Current State:
The biggest challenge is reconciling what was true at issuance time with what is true right now. Some claims require more frequent updates than others — for example, entitlements need to be updated more regularly, whereas a “student” status changes less frequently.
- – Proving Identity Requires an Identifier:
As noted by Pål (SUNET), regarding the Reference Assurance Framework (RAF): proving that the same user is returning requires an identifier, not just a name.
- – Digital Credential Query Language (DCQL):
DCQL is a mechanism for a verifier to query a wallet for specific claims. Queries can span different credential formats, issuers, and trust frameworks, and can also target specific values. A live demo was presented. DCQL supports queries for minimum viable credentials. Note: DCQL does not currently support regex or predicate queries (e.g., “over 18”).
- – Selective Disclosure:
Selective disclosure does not mean the user selects which credentials to share — rather, it is the verifier that selects which credentials (from a bundle) they wish to receive.
- – Trust Frameworks and Governance:
Trust frameworks can provide governance and policy around what types of queries a verifier is permitted to construct. Federations may also limit what attribute bundles can be queried.
- – Entity Categories and DCQL:
A question was raised: we currently use Entity Categories (ECs) to group attributes — does this apply in the DCQL context? ECs are more than just attribute bundles; they encode policies. In an OpenID Federation context, these could be expressed through trust marks. Predefined entity categories would require a corresponding predefined DCQL query.
- – Credential Lifetime and Updates:

-
- – Identifiers in Verifiable Credentials:
Any identifier placed in a VC claim becomes permanently embedded — this effectively eliminates most, if not all, privacy-preserving features. Furthermore, the issuer cannot target an identifier for a specific relying party, as the issuer does not know who the relying party will be. This significantly limits the types of identifiers that can be constructed. The conclusion: do not put identifiers in VCs.
- – Holder Key as an Alternative:
Instead of identifiers, a Holder Key can be used — something bound to the wallet the user holds. Signatures are then used to prove ownership of the credential tied to that holder. However, this binds the wallet to the device, which is not ideal.
- – Linking Existing Systems to Wallet Identity:
Several approaches were discussed for connecting existing identity systems to the wallet:
- – A) Fingerprinting: Ask for everything from the wallet and infer who the user is — essentially a fingerprinting approach.
- – B) “Connect your wallet”: If an unknown key is presented, fall back to federated identity login. The user can choose between wallet or federated ID, and the two will be correlated.
- – C) “Ask a friend”: The issuer knows both the holder and their identity — so the verifier could query the issuer directly to resolve the identity.
- – Wallet Credential as a Second Factor:
A wallet credential could also be used purely as a second factor — ignoring the claims entirely and simply trusting the user holding the key via the wallet.
- – Identifiers in Verifiable Credentials:

-
- – Background:
The initial idea for creating educational verifiable credentials originated at TIIME 2024 in Copenhagen, where the question of how to best leverage existing educational attributes was first explored.
- – Background:
SESSION #1, Breakout #4
Session Title: Putting Users in Control of Their Education Data
Session Proposer: Adrian Fellman
Session Notes Taker(s): Laura Paglione
Acronyms:-
- – IdP – Identity Provider
- – EduID – An identifier associated with a person’s education
-
- – In Norway – have an IdP for entire education sector (K – post grad)
- – Everything is stored in the home institution – identity only exists when it is tied to the institution – it is lost when the affiliation is broken.
- – Consideration to have a more persistent situation when individuals receive an identifier at the start of their education.
-
- – Netherlands:
Dutch has something like this: eduID – now a lifelong learning identifier. At Erasmus (NL) eduID started as one that is tied to the institution, but opportunity was presented to the individual to tie a personal email address to the identifier to enable individual access/ownership of the data. Institution alliances asking for assistance to manage data to support life-long learning / learning mobility.
- – Denmark:
Sliding into this idea – individuals are able to claim these identities. Access federation seems to be migrating to be an “affiliation federation”. This conversation may be similar to the “travelling scientist” conversation in a different room.
- – Australia:
Does not have anything like an EduID, but have an effort called MortarCaps that promotes the propagation of education data for interoperability and education mobility – unclear if the student or the institution owns the data. My health record – tracking? Who gets access? What purposes?
- – UK:
Each institution has the ability to define their own ID – education information is siloed within a single institution. Cross-institution sharing is uncommon; there hasn’t been a student-demand for exchange of information.
- – Belgium:
Universities are unwilling to exchange this information – reluctant to give up the ownership. Students have the responsibility to move data if needed. Researchers from all over – they have so many accounts that are related to their education data.
- – Netherlands:
-
- – Dutch: Delete data after 5 years to promote learning data continuum – tie the national ID to the education identifier.
-
- – Dutch had an IdP of last resort / guest access – used this as a head start to support this model.
- – It is less likely to have user-driven education data; it is more difficult in times when orgs are relying on students to ask for this information.
- – Lifelong learner – verifiable credentials / micro credentials / informal education – issuing credentials directly to the individual that can be stored in a wallet.
- – EduID has no value if it is only a personal email address. There is greater value if educational verified information is included – this enables trust of the information. Maybe the type of account (for example, the EduID account) is less important than the quality of the assertions themselves.
-
- – Usually done individually – often the student/researcher is then either assigned a guest identifier or a new institution-specific identifier.
- – Concerns at institutions with the possibility of accounts being compromised (for example, there is a single ID/record for all education information for the individual). Can the individual be trusted to keep this information secure?
– Is this a valid concern? Is it really safer to have multiple accounts?
– This is an argument that keeps coming up.
– Personal challenges of having all of this data in one place – tracking? Who will have this data? What does “control” really mean – who can access without personal authorization?
SESSION #1, Breakout #5
Session Title: Discovery and Group Attributes
Session Leader: Meshna Koren, Elsevier
Session Notes Taker(s): Nicole Roy, Floris Fokkinga
Tags / links to resources / technology discussed, related to this session:
- – Seamless Access
- – MDQ (Metadata Query)
- – MDUI
- – WAYF
- – OIDFed / Trust Marks
- – SAML
- – Verifiable Credentials (VC)
- – InCommon
- – Switch
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
Discussion:
- – Meshna: Discovery mechanism – how do students or anyone else actually know what to do/how to use them? Everyone does discovery slightly differently, which means users have a lot of cognitive load. UX won’t ever be solved because there’s always new people inventing new things, new flows. What can we do to make
- – There’s existing WAYFs by federation operators that applications can use, or they can create their own.
- – Nicole: Recommendation to run discovery service close to your service, so you can cater it to your users. With MDQ (metadata query, getting SAML metadata by entity ID(?)), made it harder to run discovery service, in turn that meant a shift from the app operator to the federation operator. In the US, Seamless Access is used.
- – The problem can occur that a user sees two instances of the institution. A workaround is using the user’s email address, and try to discover the IdP from that. That has a bunch of problems.
- – Are there any UX / frontend designers in the room? Unfortunately not. (We need someone like Arlen Johnson from SCG CG who is a UX specialist to help us)
- – “I think there is a user outreach angle, that we are failing at.” We need to make it easier to access this stuff.
- – But if we have solutions out there, how do we run it?
- – What if we containerized Seamless Access? You can specifiy filtering and other config, it could even be run as a service.
- – We have data. Does that mean, ‘us, federation operators’?
- – There is mandatory information, but also optional, like display name. Logo is also very important.
- – Seamless Access can now publish attributes in metadata, that Seamless Access can filter on.
- – We’ve heard advantages and disadvantage of running the discovery service at the service, or more centralized, like at the federation level:
– More knowledge at the central level
– Familiar UX for users
– Option to remember IdP at central place
- – So: how do we avoid repeating the cognitive for the user, every time they log in (at a different service)?
- – Account linking: high barrier.
- – A discovery service needs more information to route the user to the correct /desired flow.
- – Nicole: what if we used VC? That would give more functionality than a SAML federation. The information is put there by the IdP.
- – An discovery service, SP/RP could ask the wallet for discovery credentials.
- – A wallet could understand federation metadata, and query for a selection of IdPs.
- – “Wallets for this use case sound like a usability nightmare to me.”
- – Something similar is also happening with cookies in browsers.
- – Many tech savy users use multiple browsers or containers to manage multiple identities.
- – It should be possible for a user to simply switch identities.
- – “A users is basically impersonating themselve.”
- – Logon switching is simply not something web developers think about.
- – Single sign out doesn’t work very will. It requires many round trips, and every time something can break. Both sides need to support single signout.
- – Google took a run at solving this in their own way, with an account chooser. Heather spoke with them, but they still produced something that doesn’t work, so noone uses.
- – Discovery needs more information to work good for the user, in a privacy preserving way.
- – MDUI (Where the metadata URL is stored).
- – Everything that is introduced that is not mandatory, will not be adopted.
- – In order to communicate, you need attention.
- – A problem that occurs, is that institutions have similar names, and sometimes have multiple IdPs.
- – Switch supports almost any MDUI element. IdPs can change them themselves (?).
- – InCommon got a ton of value for doing a logo thing.
- – Seamless Access require every IdP to have a logo, everyone uses Seamless Access has decreased the number of helpdesk tickets significantly.
- – Since SAML is EoL, OIDfed has trust marks. Might this be a solution for this problem? If so, please go to the OIDfed meetings!
- – The lowest common denominator is SAML.
SESSION #2, Breakout #1
Session Title: ZKP – Zero Knowledge Proofs
Session Notes Taker(s): Heather Flanagan
Tags / links to resources / technology discussed, related to this session:
- – Zero Knowledge Proofs (ZKP)
- – BBS ZKP
- – BLS
- – ZK-snarks
- – Longfellow (Google)
- – ISRG (Internet Security Research Group)
- – SIROS wwWallet (SUNET/GUNET)
- – EUDI Wallet / ARF
- – WE BUILD Consortium
- – DC API / Digital Credential API (W3C)
- – JSON Web Proof (JWP) – IETF jose WG
- – mdoc / ISO/IEC 18013 Annex C
- – OIDF OpenID4VC
- – FIDO / Passkeys
- – PSD regulation
- – eIDAS
- – https://xkcd.com/927/
- – https://mailarchive.ietf.org/arch/browse/zip/
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
- – The current discussions on Zero Knowledge Proofs unfortunately instilled no knowledge.
- – We’re talking today about non-interactive ZKP; meaning you only need one round to do them (one query, one response, and you can rely on that)
- – There is a difference between selective disclosure (the presenter can choose not to share some of the data elements) and ZKP. But because of holder binding, there are unique keys. The idea is to only use that key pair once with batch issuance. But the issuer knows what the public key is, and the verifier knows what the public key is, and so they can collude. The issuer can also add pre-defined salts to make sure they are aware of what’s going on (called subliminal channels).
- – One of the problems we have is verifier-verifier correlation. If you use multiple cryptographic keys with the several verifiers, they can correlate. With batch issuance (which is what most of the EUDI wallets are doing) they tried to break the verifier-verifier correlation.
- – BBS ZKP:
The classical ZKP using pairing-based elliptic curves has been around a while. BBS ZKP using elliptic curves are efficient and reasonably fast, but they currently aren’t post quantum (PQ) safe. There is a question as to whether we can work with them anyway. There are theories on how to do a version of BBS proofs that is PQ safe, but that’s still just research and not deployable. The biggest problem with BBS (the IETF jose WG is doing a JSON Web Proof (JWP), which is based initially on BBS) is that there are still unsettled issues on how to do holder binding. There is some effort to shift to BLS, but there are no common TPMs that support that algorithm.
- – Longfellow (Google):
The other contendor that’s come up is referred to as Longfellow, from Google. That’s a ZK-snarks (non-interactive proofs). It’s a class of ZKP based on circuits; a different approach to ZK. Google came up with a way of doing it over an existing mdoc, which has the advantage that it only needs an ECDSA signature, which can be done by existing cryptographic elements. Limitation: it takes a long time, it’s size inefficient, and the mdoc is the least efficient format. But the premise was: what could the do ZKP over with what people are actually issuing.
- – ISRG:
ISRG (Internet research group) has been doing a clean-room implementation of Longfellow, but they’ve discovered some problems they are fixing in their opensource library. They have a version that can run in typescript in the browser. It is assumed to be PQ safe since it uses hashes, assuming the underlying signature is also PQ-safe.
- – SIROS wwWallet:
The opensource wallet that SUNET and GUNET started, now rebranded as the SIROS wwWallet, has substantiated this. They are working this, and they are working on interesting pseudonyms in some deployments. Google is interested in the pseudonyms for account recovery use cases. If you need your national PID reissued, it is associated with the pseudonym.
- – Wallet Providers and Data Portability:
Wallet providers must support data portability, but everyone knows now if you are switching to a different wallet, that might not work seemlessly. But account recovery is being pushed to the wallets, with recovery meaning if an end-user has a wallet with a PID, get a new device, the wallet provider must recognize that and offer a backup UNLESS it was device-bound (which PIDS are), then they must be able to reach out to the issuer and ask for a re-issuance. Google’s interest and the WE BUILD’s interest aren’t the same. WE BUILD is more about anti-abuse, preventing people who abuse services from creating new accounts.
- – Pseudonyms:
There are different kinds of pseudonums. One where the entropy comes from the issuer, and another where some comes from the issuer and some from the wallet. If the user controls their wallet, the user might be able to change their own pseudonym. This is an area under discussion and experimentation.
- – Pragmatism vs. Perfection:
One of the clashes in WE BUILD are the people trying to design a perfect world, and those trying to be pragmatic about it. But given the deadlines, we probably need something to work with. For the purposes of presenting attestations, maybe PQ shouldn’t be a consideration? Can we start with something we know we’ll redesign in a few years?
- – Short-Term Solutions:
Best solution in the short term is BBS but there is no way to do holder-binding with secure elements available. The Longfellow approach lets you use traditional cryptography but it’s large and slow. One of the limits is how many things you disclose; the more things you disclose the larger and slower the proof gets. Practically speaking, the largest you can do now is one thing with three attributes. There are possibilities to do hybrid approaches; that’s under research now. If the issuer can do some more work than just issuing a standard ISO mdoc, then maybe we can make Longfellow more efficient, or BBS use a different kind of proof.
- – ZKP in eIDAS isn’t a “done deal” yet given the research still underway. Everything has drawbacks. If we can work with issuers and allow some change on the issuer side, maybe we can find compromises.
- – Passkeys as Pseudonyms:
One area that seems to be moving forward in the regulator space is using passkeys as the psuedonym. You could read the regulation as big tech as using the PID for authentication, but the EC has redefined that to say you can use a passkey as a PID pseudonym. How this will look for the regulated industries and big tech platforms is interesting, because they are mandated by 2027 to use the wallets for authentication.
- – PSD Regulation:
The PSD regulation says if you outsource authentication to a third party (e.g., a national wallet), then you have to have a signed agreement. That’s not going to go well. If the wallet is given, if there is an attestation in there we can rely on, if they can issue strong authentication into that wallet, maybe that will help. All the EUDI wallets are also supposed to be passkey providers, so some orgs think that means they’ll easily be “done”.
- – FIDO Attestation:
In a reasonable world, the wallet would provide a FIDO attestation, but in iOS the attestation is blocked so the wallets cannot provide attestations. The EC might have to have some strong words with some platforms. There is also no mechanism by which an RP can make a passkey in an EUDI wallet, which means users will have to split their passkeys across multiple credential holders.
- – One person in the room thinks that the ability to generate a recognizable pseudonym from a PID in an EUDI wallet is a huge deal, bigger than just Google (who is leading efforts on that). This is also why SIROS is working with the Lets Encrypt (ISRG) team to make sure this is more broadly applicable than Google/Android wallets. This will eventually work more broadly than just these efforts, and the ARF requires it, but nothing says how to do it yet.
- – General guess is it’s going to take another 5 years to get to the certification required by January. Up ontil then, it will all be highly regionally specific. Whether the wallets that support this work will be nationally supported is an open question. Also, right now, only 6 EU countries are going with an open certification scheme that will open up what wallets can be certified. There is a lot of responsibility being pushed to the wallet providers.
- – SIROS is focusing on being the wallet for the “10%” of use cases that the national wallets won’t properly support. That number will go up outside of Europe, especially where you find more people sharing devices, etc. Devices and technology are not evenly distributed.
- – Does the wallet really need to be the power tool covering everything? Basic issuing and presentation is actually ok, but when you venture into payments (as an example) they have their own use cases and standards that they want to see.
- – DC API:
Note that the use of “DC API” is a bit vague as some use it generally to refer to all the APIs involved, but the W3C also has a specific specification under development called the Digital Credential API that essentially solves the discovery problem (well, it solves part of it). That specification refers back to ISO/IEC 18013 Annex C (mdoc) and OIDF OpenID4VC on the issuance and presentation aspects of getting to/from the wallet.
- – How are the standards coming along in all this space? In the DC API, the big fight is if/how to support ISO specs in the standards. There is also work going on for potential harmonization to create a new standard that overtakes mdocs and DC API. See https://xkcd.com/927/.
- – See also https://mailarchive.ietf.org/arch/browse/zip/ is an IETF non-WG mailing list where we’re trying to bring together ZKP researchers and standards engineers.
- – Since the ARF 3.0, proposed final, is supposed to be done by April, someone needs to include work on ZKP in there.
Reference:
- – WE BUILD consortium – The WE BUILD Consortium is a large-scale, European collaboration consisting of public authorities, private companies, academic institutions, and technology providers. Together, they aim to design, implement, and test a trusted digital business identity ecosystem based on the European Digital Identity Wallet (EUDIW) framework.
SESSION #2, Breakout #2
Session Title: How to Facilitate Brownfield Deployments and Adoption Outside of R&E
Session Notes Taker(s): Craig
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Why limit the scope? Why put “edu” in front of everything?
Hopefully this analogy is relevant:
The HTMT (Hybrid Technology MultiThreaded) project sought to identify the chip technology, memory architecture, and processing models necessary to achieve petaflop performance. HTMT culminated in 1999 having identified multiple novel technologies that would take many years to develop.
Sustained petaflop performance was achieved in May 2008 using IBM/AMD commercial processors and interconnect essentially in a cluster architecture – using none of the concepts identified in HTMT. The HPC (High-Performance Computing) community benefited greatly from the use of commercialized technology.
If federation technology similarly underwent commercial adoption and development, would it benefit R&E federations? Is it within the scope of R&E to facilitate any such development?
SESSION #2, Breakout #3
Session Title: AARC 4 Education / FIM4E
Session Proposers: Licia Florio (NORDUnet), Peter Leijnse (SURF), Peter Havekes (SURF), Peter Gietz (DAASI)
Session Notes Taker(s): Floris Fokkinga (SURF)
People interested in mailing list: Licia, Floris
Sessions from Euler A and B were merged.
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Peter L:
University Alliances, recommended: look at what already exists: AARC and research use cases. I believe we can reuse common use cases. But University Alliances (UA) are not buying it. There are some essential differences. We need to open our mind to that. What would we need to change to FIM4R to become FIM4E? A university alliance, are 7-9 universities from different countries that create a shared learning environment, that need to be supported, also with a coherent identity solution. Because of legal requirements of legacy reasons, AAI is often still tied to the institutional accounts.
- – Peter G:
We have hands on experience with ‘Emerge’ (uni alliance). We’ve done the AAI stuff. We see interesting interoperability issues with attributes, and non-standard behaviour. We want some VO (virtual organisations) and group membership management.
- – Peter H:
We are involved with a university alliance, we are now in the enrolment phase. The research use case is different. Students don’t want to join a group, they need to be enrolled in a class.
Gaps: infrastructure and resources are issuees.
- – Christos:
We are talking about student mobility. We were asked for the Erasmus programme, university alliances. We thought it was the same thing as for research, but there are difference. The terminology is completely different. Because of they, education doesn’t think the solution applies to them, or will work for them. The problem space is not well defined. Education talks about a use case from identity, to users management, as if it were one problem. We need to define the boundaries. Secondly, at student mobility use cases, administrators are usually not (AAI) domain experts.
- – Janos:
There are commonalities. Especially with forming group: research group or a class. Also working on a research project or a class.
- – Peter H:
The role of the group member is different: are you active in the group, or just following a course in a class.
- – Niels:
The scale can differ: students can be in very different numbers. A goal for a university is 50% mobility, so that’s thousands of students. Researchers are much smaller groups. The learning management systems (LMS -for example Moodle, Canvas…etc) were never meant for these large groups. In research, from day 1, they were already collaborating.
- – Pieter:
Moodle (learning tool) has a SAML plug-in.
- – Niels:
If you are procuring a learning platform every 4 years, and then you need to adapt the system, you are too late.
- – Klaas:
There are huge differences between HPC, EOSC and open education. From an architectual point of view, they are extremely similar.
- – Peter L:
It is a language problem.
- – Christos:
MyAcademicID has 800k users. Scaling can be a problem
- – Peter G:
FIM4R was good to make the EC aware of the problem, and invest in a solution. FIM4E could be a good anchor for the conversation.
- – Niels:
AARC started with existing federated technology. It took a long time to connect with all relevant stakeholder. FIM4R made the research community identifiable for us. Does such a group exist for education?
- – Gyongyi:
In my experience they are somewhat organized, however there is a strong need to better align the different stakeholders:
– European digital education hub (EDEH)
– European university association (EUA)
– European University Foundation (EUF)
– FOREU4All – University Alliances IT representatives
EC is trying to synchronize research and education groups (European Research Area / European Education Area).
- – Christos:
Part of the success of AARC was not that FIM4R came to us, we embedded ourselves in AARC. Togehter we should create a common understanding. What we did for EOSC: we created a profile of AARC. We should do the same for education. We need to make sure our building blocks are solid, and general enough (so they don’t only work for research).
- – Anders:
Should we profile AARC for education?
- – Christos:
We need an identity layer (for example). We need to proper building blocks.
- – Peter H:
The main problem are the education systems that exist in the institution (student administrators).
- – Anders:
This is a completely different scale. You cannot expect a person to manually register the student every time (this is about business processes).
- – Licia:
What we saw in MyAcademicID it was not the representation of the university. We talked with SPs at the level of Erasmus. We needed to understand the terminology. Maybe we should make an attempt to connect with the relevant groups from universities with the understanding of the outside landscape. Where do we find the people we can talk to about the different requirements for the education use case.
- – Niels:
For research projects, it was a natural thing to improve their infrastructure, also AAI. For education, that does not apply. IT runs the printers and cloud. They cannot change their own systems.
- – Bas Z:
Alliances want to do this, and improve these systems. We know why these people are.
- – Christos:
People that are topical experts in alliances, are not in the groups. We need to find them and create a group to discuss these requirements.
- – Anders:
The problem is that people in the alliances often don’t know who the right people are. We could go to them with a specific check list to find these people.
- – Ian:
In the UK even organisation like the research alliance barely overlap with corporates. Underfunded and stretched.
- – Licia:
When we started with FIM4R, we said the same thing about researchers. There is a parallel with universities.
- – Niels:
I think the AARC BPA might not be the way to go here. Architectually, it might match. But the scale is very different. It’s not going to be 10 times, but 100 times larger. So we need to cater to decentralized systems.
- – Licia:
You are already talking about implementation. We need to think about what the starting point is. There can be different implementations. We need first to understand eachother.
- – Christos:
AARC BPA does not equals proxy.
- – Maarten:
The human side. European student identifier (ESI). You need to talk to your IdP people and IT department. That was challenging. Because the IT department is already busy, and often with other things.
- – Bas:
In each alliance (?)
- – Janos:
We have to go back to legal environment what we have for education. Education is part of the national authority. Every nation has their own education administration system. There usually have a national solution. Different environment from research. We have to work on an umbrella or proxying together the information instead of providing solution for each country. National Authority is responsible for the national educational administration system. Many cases it is not the same as the NREN but another organisation. We can complement the solution to support student mobility.
- – Licia:
Australian Access Federation (Australia, New Zealand, Canada). They have never seen universities changing things is such a short time, except on their own initiative.
- – Alan:
They still go to their own IdP, and still got to the same services. FIM4R started with wants, needs and desires, and AARC came out of it. We need to do the same with FIM4E
- – Licia:
Paper about Higher Education Interoperability Framework exists. That is a good starting point.
https://education.ec.europa.eu/document/european-higher-education-interoperability-framework
- – Peter G:
Who is working with a university alliance? ~6 people.
- – Peter L:
What is the reason to move? What groups should bring it forward? What project proposal are we going to submit to (some organisation with money)?
- – Licia:
The proposal should be brought forward by a university alliance, we can support, but should not submit.
- – Peter G:
Univesities have their own consortia. They came up with a base or commonly required services. We should ask alliances about requirements for federated identities.
- – Niels:
Another challenge is: we are mostly about identity and access. But in this case, I&A is mostly a minor inconvenience. It is about sharing education, grades. The NREN might not even be the national entity dealing with university alliances.
- – Peter G:
But we can be the solution.
- – Bas Z:
That is no different than the research use case.
- – Licia:
FIM4R changed that: researcher groups thought they were very different as well.
- – Christos:
Scoping is very important: what problem we want to address.
- – Alan:
An alliance can be catered by serveral NRENS, and they might not agree on which solution they want.
- – Peter G:
Lets’ think about forming FIM4E and how to proceed.
- – Licia:
Me and a few others in SURF will have meeting about this.
- – Peter L:
-
- – Fredrik Domeij fredrik.domeij@umu.se
- – Peter Havekes
- – anders sjöström
- – Janos Mohacsi
- – Peter Bolha
- – Liam Atherton
- – ian Collier
SESSION #2, Breakout #4
Session Title: Group Attributes and Federation
Session Leader: Meshna Koren, Elsevier
Session Notes Taker(s): Marlies Rikken (SURF)
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – A ServiceProvider want to know GroupMembership
- – Main question: is it possible to simplify?
- – Why would you care about the groups that the IdP has?
- – Example: Uni that has subscriptions to receive specific service. ”Subset of user to be expressed in a group”
- – Which types of groups do we talk about in this session? ‘group of people’ or ‘group of people with specific rights’ – you are entitled to use a certain service.
- – How do you identify users that belong to a certain group?
- – It doesn’t matter what groups are called or what attributes get used or how they get formatted.
- – Some identity providers do not manage group memberships (or don’t manage them well).
- – Which kinds of groups are the services interested in?
- – With respect to the Internet2 collaboration management platform, which injects account linking and access rights, InCommon has tried using Grouper attributes that include the SP entity ID, and the proxy will only release group membership data if the group includes that SP entity ID in its attribute. That is very complex and might only work for spoke-hub federations (or proxies).
- – Is there some kind of alignment between zero-knowledge proofs and attribute authorities?
- – There is also a business problem around what a group means within the institutions themselves. What users should be part of which groups? More and more home organizations lack the means to accomplish this (knowledge/skill/staffing), making this a business problem, not a technical matter.
- – If done incorrectly, this might disclose private information to parties not authorized for that information.
- – In the general case, IT works for the business side of things, but SPs are asking about things served by librarians or principal investigators.
- – How do you release the group information? Nicole using eduPersonEntitlement, memberOf or GroupClaims.
- – Controlled vocabularies around eduPerson Entitlement? Some IdPs cannot assert custom attributes at all.
- – Publishers position – different approaches per publisher. For example, Wiley asks subscribers which attribute and value authorizes access to a particular subscription. Automating that business process is a SMOP—both on the part of the IdP and of the SP.
- – Distributed groups and communicating those is hard – easier when automating based on existing attribute.
- – There are plenty ways to figure out the technical options to communicate groups – the difficulty is → defining the groups, knowing who is in a group – this information is not necessarily present in the IT, but on the business side.
SESSION #3, Breakout #1
Session Title: SCIM
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
GAP1: Public Subject Identifier
- – Problem:
The AARC-G056 Attribute Profile requires a persistent, non-reassignable, globally unique string representation of a subject’s identifier. The analysis indicates inconsistent exposure of this identifier across platforms: Mutable attributes (e.g. userName), Custom extensions (e.g voPersonID), Missing data, i.e. the identifier is not exposed in the SCIM User resource.
- – Proposal:
Option A: REQUIRE use externalId attribute (SCIM Core)
Pros: Standard Core attribute (RFC 7643); no schema extensions required. Semantically defined as an identifier from the provisioning domain.
Cons: externalId is readWrite in RFC 7643; if externalId is adopted, the AARC Profile MUST enforce immutability and non-reassignment by policy and document this behaviour. Potential collision if externalId is already used by the platform for other subject identifiers.
Option B: REQUIRE use of voPersonID (voPerson namespace)
Pros: Aligns with voPersonID (SAML) and voperson_id (OIDC) usage.
Cons: Relies on a temporary namespace. AARC is not authoritative for the voPerson schema registration. Non-Core attribute; requires custom configuration for commercial SCIM clients. Defined as multi-valued attribute in voPerson schema; MUST be defined as single-valued array or single-valued string by AARC Profile.
Option C: REQUIRE use of single-valued publicSubjectId or other custom attribute (AARC namespace)
Pros: AARC Community is authoritative for extension namespace definition and versioning, e.g. urn:geant:aarc-community:scim:schemas:core:1.0:User
Cons: Non-Core attribute; requires custom configuration for commercial SCIM clients.
Option D: REQUIRE use of voPersonID (AARC namespace)
- – Problem:
GAP2: Home Organisation Attributes
- – Problem:
AARC-G056 distinguishes between a human-readable Organisation Display Name and a Home Organisation Domain (schacHomeOrganization). The analysis indicates that SCIM implementations do not represent these attributes consistently, and SCIM does not define a standard attribute for the Home Organization Domain.
- – Proposal:
Option A: Hybrid Approach (SCIM Enterprise User extension & AARC namespace)
Mapping: Organisation Display Name: Map to the standard SCIM Enterprise User Extension (urn:ietf:params:scim:schemas:extension:enterprise:2.0:User:organization). Home Organization Domain: Map to a dedicated AARC SCIM extension attribute.
Pros: The organization attribute is standard. Commercial clients will automatically display the user’s organisation name without custom configuration.
Cons: Fragmentation: Organisation data is split across two different schemas (one standard, one custom), requiring clients to query both namespaces.
Option B: Unified Approach (AARC namespace)
Mapping: Organisation Display Name AND Home Organization Domain map both to a dedicated AARC SCIM extension namespace. URN: urn:geant:aarc-community:scim:schemas:core:1.0:User. Organisation Display Name → Single-valued organizationName (see organization_name in OID-Fed). Organisation Domain → Single-valued organizationDomain.
Pros: All organisation-related data resides in a single, consistent namespace governed by AARC.
Cons: Lack of Native Support: Commercial SCIM clients will not display the organisation name out-of-the-box. They will see the standard organisation field as empty unless manually configured to read the custom AARC schema.
- – Problem:
GAP3: Affiliation (voPersonExternalAffiliation)
- – Problem:
AARC-G056 requires expressing the user’s role at their home organisation (e.g. faculty@helsinki.fi). The analysis reveals that this attribute is largely missing from current SCIM implementations.
- – Proposal:
Option A: REQUIRE use of mutli-valued voPersonExternalAffiliation attribute (voPerson namespace)
Pros: Direct alignment with the existing voPerson standard used in SAML/OIDC.
Cons: The voPerson SCIM namespace is currently temporary (urn:temporaryNamespace…), requiring standardisation efforts external to AARC.
Option B: REQUIRE use of userType attribute (SCIM Core)
Pros: Native support in SCIM clients (Core schema).
Cons: Single-valued: Standard SCIM userType allows only one value. It cannot support users with multiple concurrent affiliations (e.g. someone who is both “faculty” and “member”). Loss of Scope: It does not capture the scoped syntax (affiliation@scope) required by the AARC profile.
Option C: REQUIRE use of multi-valued scopedAffiliations attribute (AARC namespace)
URN: urn:geant:aarc-community:scim:schemas:core:1.0:User
Pros: AARC Community allows authoritative definition and versioning. Allows strict validation of the affiliation@scope syntax required by the AARC profile.
Cons: Non-Core attribute; requires custom configuration for commercial SCIM clients.
- – Problem:
GAP4: Assurance (eduPersonAssurance)
- – Problem:
AARC-G056 and the Refined Assurance Framework (RAF) require communicating identity assurance levels. None of the analysed platforms currently expose this attribute via a standard SCIM mapping.
- – Proposal: REQUIRE use of multi-valued assurance attribute (AARC namespace)
URN: urn:geant:aarc-community:scim:schemas:core:1.0:User
Pros: AARC Community allows authoritative definition and versioning. Allows carrying complex URIs exactly as defined in AARC-G056/RAF.
Cons: Non-Core attribute; requires custom configuration for commercial SCIM clients.
- – Problem:
GAP5: Modeling Roles in Groups
- – The AARC SCIM Profile mentions “Handling of roles within groups” but leaves the technical implementation as a gap.
- – Proposal A: The “Entitlement” Approach
Mechanism: Roles are serialised into the User.entitlements string (e.g. urn:..:group:mygroup:role=manager).
Pros: 1:1 match with OIDC Claims/AARC-G069. No schema changes needed.
Cons: “String typing.” SCIM Clients must parse regex to interpret group memberships and roles within groups. SCIM Servers must parse regex to assign roles within groups.
- – Proposal B: The “Extended Member” Approach
Mechanism: Extends Group.members with a role sub-attribute.
Pros: Clean SCIM data model.
Cons: May break commercial SCIM clients.
GAP6: Operational Baseline
- – Problem:
Operational features vary significantly, e.g. some platforms lack support for standard SCIM Filtering and Searching.
- – Proposal: Minimum Operational Set:
Filtering: Support for eq (equality) operator on specific attributes: Public Subject Identifier (see Section 5.1), Email?, Other?
Discovery: Exposure of /Schemas and /ServiceProviderConfig endpoints. Exposure of the scim_endpoint as per the OIDC Profile for SCIM Services Draft.
- – Problem:
Discussion:
- – only use the core and register own extension (P.G.)
- – make it as simple as possible so there is little ambiguity
- – put all external schemata into the AARC namespace?
- – Interoperability between SCIM, verifiable credentials, OIDC needs to be upheld
- – → It’s in general about JSON representation of our attributes, not just for SCIM
- – one issue about voPerson-based attributes is multi-valuedness, creates ambiguity for RPs
- – proposal: go with option B (unified approach) and register everything under the AARC namespace
- – get Leif’s opinion, too
- – how to highlight changes in custom/AARC schema in comparison with core schema?
- – Proposal to register all attributes under a common AARC namespace to avoid having multiple schemata in a query
– Does this also include core scim attributes?
- – next proposal to use all attributes available in the core schema and register all additional attributes under AARC namespace
- – AARC namespace extension would make use of (RFC 7643) urn:ietf:params:scim
- – How to you handle group/roles updates through the core User.entitlements
SESSION #3, Breakout #2
Session Title: Business Cases for Federation Membership Value and Business Models for ADI Infrastructure
Session Notes Taker(s): Matthew X. Economou, Keith Brophy, Dedra Chamberlin
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Nothing guides deployers to multi-lateral federations. Service providers can try to encourage federation membership, but individual SPs lack the required influence to drive organizational change (and justify organizational costs/risks). Sometimes, organizations are in the federation but don’t know it (whether due to staff roll over or whatnot). University libraries and central IT teams often do not interact, which exacerbates this gap.
- – People not aware of federation – start running IdPs / Microsoft.
- – No awareness of being part of a federation – even if they already have an entry there.
- – Approaching institutions – asking if they want to join but they do not know what the federation is or it is somebody else’s problem.
- – Leadership/administrative layer needing to understand why they should join and reasons for funding.
- – Need to define Value Description – help promote benefits of federation
- – Divide between library and central IT teams – difficult to get buy-in to make decsisions – the people who pay/make decisions can be difficult to meet.
- – Adopters/deployers – challenge to make this stuff work – it is hard with limited documentation. Tools are complex. Question: I have a website – how do I install/integrate? Steep learning curve.
=> Less technical – need better documentation, copy’n’paste solution that can be deployed more easily. InCommon talking about making Federation easier to integrate.
- – JISC/OpenAthens sees the difficult part being access to SPs, which typically happens out of band and takes away from the value of multi-lateral federation.
-
- – Research infra on clinical research – users are on record (legal requirement) – need strong assurances that scientist working is who they say they are
– Workaround for lack of assurance data – know your researcher partner concept – through principal investigator relationships → results in Invitational model for SPs.
– Waiting for IdPs to release assurance data (enable self-signup model – with moderation step)
- – consider smaller groups?
- – International collaboration problem is solved through Federation
- – From SP perspective: one value proposition → not having to implement and enforce credential management (account reset, etc.)
– Smaller number of researchers across institutions
- – Small research groups connecting to commercial publishings
- – Research infra on clinical research – users are on record (legal requirement) – need strong assurances that scientist working is who they say they are
-
- – Could federations improve their value-add by offering additional licenses or services to participants? That might make better sense for federations like OpenAthens.
- – Misconception? => Federation does not provide access to resources but connects infrastructures
- – In some cases, it’s easier/faster to set up authentication against commercial vendors (e.g., Microsoft, Google) than to set up bi-lateral trusts.
- – Online license content providers have begun adopting multi-lateral federation within the last 10 years. Are there things that happened to promote that, which we could apply to other industries?
– The majority of the service providers are actually small, so they have under-developed infrastructure and support. They don’t have the money to invest.
- – The more institutions connected to the Federation the better for all involved – but still challenging for smaller research groups. Challenge in understanding what the benefit is → back to Value Description.
- – OpenAthens – lack of documentation/value description on why small publisher should join? Small publishers need finished module that they can plug in and finish the system – Authn and Authz in a box (due to them having limited resources).
=> Federation (signing up one form) vs defining connections across all SPs.
- – MS Entra – every institution is a separate IdP
- – Q: What can we learn from MS?
- – MS focuses on $ maximisation – they lock you into ecosystem vs Federation (allows you to select you infrastructure stack and what you want to integrate with)
- – Argument: REFEDs is not a completely open – could argue proprietary protocols in similar way to Azure protocols
- – Marketing is the solution – MS has done a good job of getting training material out there and getting into training/education resources space – good job of creating sample code – example projects that help people understand how to integrate → integrates with ADFS / Azure – makes plugging into ecosystem easier. No YouTube videoes on how to integrate Federation pieces.
- – This community does not have strong marketing experts – technical but not marketing.
- – Scaling perspective – instead of being locked into Google/MS/Facebook button – entire world is open to you. How do we get people to know that is a possibility? We need to become advocates of this.
- – Marketing roles costs money – commercial endeavour to promote Federation.
- – Universities market to students – can/should they market to researchers – we can let you collaborate with research populations that you could not normally connect with.
- – Q: unable to join Federation as commercial entity? Are some of the rules too strict (on membership). => Good reason for restricting membership.
- – Good thing about onboarding – good workflows from InCommons for eduroam registration (cost is on IdP that want to be part of that group).
– Academic/research requirements not too onerous
– In Denmark, you must be eligible to join the NREN (“do you do research?”) in order to be able to join the identity federation.
– In Australia, AAF also has a subscription model:
– Provide metrics around usage – help support argument for Federation
– Part of 26 national research capabilities (NCRIS) – provide researchers, citizen scientists, etc. access to resources and services
– AAF hosts a group of member comms teams dedicated to uplifting the importance of national research infrastructure, currently aimed at advocating their abilities to government research groups. They do customer road shows, webinars, conferences, etc. Lots of relationship building. They also have pilot projects that become champions for others with related problems.
– The maintain a service catalog and specifically reach out to new services. That provides the value proposition for existing IdPs: https://manager.aaf.edu.au/service_catalogue
SESSION #3, Breakout #3
Session Title: Should We Support Microsoft?
Session Notes Taker(s): LoganA
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Intro context: We (SURF) have dilemmas, should we help institutions go deeper into the Microsoft ecosystem via e.g. EntraID, External Authentication Methods?
- – Question: Do others have this dilemma? How do you approach it?
- – We see 2 types of integrations, push and pull w/ entra, depends on local IT at institution. Sometimes “we already pay for MS, so let’s use as much as we can” versus “we care about digital sovereignty so we will do stuff locally as much as we can”.
- – Is it good to adjust our services to adapt to MS stuff? It costs us a lot of energy and time, and it means working with MS specific, non-standard stuff. Given we are financed by our members and we see variation in member appetite for MS integration, spending resources on MS integration is not a value for all financers.
- – Tradewar and geopolitics changed ideas of what was possibe – no longer unthinkable that a big red button gets pressed. So non-MS efforts get more support.
- – Does not integrating MS into our stuff help institutions move away from MS, or do we just lose the institutions as members?
- – UX is central, potential future risk of red button action is theoretical only. If UX is improved by MS, then okay.
- – Why is MS special? Similar effort not spent on e.g. google IdP. So one tech giant gets advantaged thanks to us.
- – Split between administrative style workflows and services within instititions that are more tightly coupled to MS, versus non-administrative that are less tightly coupled.
- – Be very clear with selves and membership base on the “why” behind any decision you make. Justifications are critical and must be included. This applies for both choices (MS vs non-MS)
- – Reasons to do it and not to do it:
Sovereignty, cost (short term, long term), implementation difficulty.
- – Common pathway:
Local → Microsoft AD → Microsoft EntraID
But our aim is always to serve requirements of the research community. In our domain (hungary), the RC uses MS stuff. The MS efforts had financial support, trying to do e.g. google workspaces did not and did not succeed, so MS > Google at the end here. Also, we serve primary and secondary schools and they are deep in the ecosystem and no demand for change comes from here. Around 50 secondary schools are using Linux environments.
- – How could we get to a viable multi-vendor ecosystem? Problem is less “MS” but that MS has a monopoly.
- – Note that in France, a minister has sent a letter saying that universities may no longer use some MS stuff
- – Perhaps risk based approach could be a way forward here – if the chance coefficient increases, that changes the risk envelope, will they accept that risk?
- – Something that could be of value: if you’re already running multiple proxies, it can make swapping components / suppliers easier.
- – Dutch R&E instititions IDMs are mostly not Microsoft, but the IdPs are. We published a whitepaper encouraging such institutions to at minimum have a local copy.
- – We started a disaster recovery process and simulation (norway, sikt) and that was useful. AWS specifically, if we lost an availability region.
- – Perhaps useful to collaborate with other NRENs on disaster scenario planning.
SESSION #3, Breakout #4
Session Title: Post Global ID – What is a Federation’s Role? How to Survive the EUDI Wallet? GovIDs Effect on R&E Federations
Session Proposers: Peter Leijnse (SURF), John Scullen (AAF), Antonio Coucelo (FCCN)
Session Notes Taker(s): Andy Nguyen (AAF), Zacharias Tornblom (SUNET), Niels van Dijk (SURF), Gyongyi Horvath (GEANT)
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – MortarCaps:
Open data standard for Australia, not a friendly posture for international students. So student can pick up and move from uni to uni. Express degrees, certs from AWS, employee details, health related info (student may need additional time) and in a way that does not hose information (the right info and the right time). Open standards that are not held by the MortarCaps, so even if they go away the standards will continue to be evolved. Vendors are building into their APIs to ensure the longterm use. Codesigned in collab with universities and industry. Institute of engineers is a first use case.
- – Some background by Peter: Misconceptions about wallets and digital identity
- – Australia there is the Consumer Data Right – AAF approached the Australian government directly for the educational and research use case. A lot of siloed, working towards a common data model.
- – The most recent student data in aus is 12 months old – this will enable more real time data on students.
- – The vendors are not all at the table, some vendors are helping paying for this initiative.
- – There is now a need for a persistent identifier, not issued by a single university, because of this new infrastructure.
- – Govt IDs must coexist with these data standards:
– The govt can’t decide who is a valid researcher
– Not authoritative of international students
- – MortarCaps:
APPLY IT WHERE YOU CAN, WHERE YOU MUST USE IT, AND FOR THE REST – IGNORE IT
-
- – How is it interacting with our systems? Will it be core to- or peripheral to our systems?
- – Our Trust ecosystem can’t be expanded to outside – EUDIwallet will contribute not replace.
- – There are big differences between a national identity depending on what country it is issued in – some identites are more trust worthy then others… how do we represent this.
- – For education it would come from understanding and acknowledging degrees.
- – Some Govt wallets will not interplay with international needs – some support for non EU to become a RP.
- – PID base attributes: Firstname, Lastname and Date of Birth will be mandated – every other attribute will be dependent on what country it is being issued from:
– Need to certify that a John Doe with DOB has a degree, how do we know that it is the real John Doe
– Issue some sort of student card or identity that will then be linked to the wallet data
– We like the idea of decentralized ID, we just don’t like that it being so closely bound to the EUDI-wallet
- – Universities does already have to make claims about a student, saying that they have a right to study and your right to be there.
- – Many countries have different authoritative sources for native people, people born abroad who have later in life migrated.
- – Immigration is not part of your educational boundry, when does it need to cross the boundries?
- – In many countries there are only certain times in the students life-cycle that you are allowed to use the government issued identity (onboarding and offboarding).
- – What is the responsibility of education to let the govt know if there is a discount:
– Can the data be subponead? No there shouldn’t be… by principle you should not be able to tell when the EUDIwallet is presented
- – Will we have specific education wallets?
– Some countries are not comfortable with the govt deciding on what goes into it
– Do we have a specific definition of what a wallet is?
– You don’t want to present your Passport when you are just getting coffee for a discounted student price – you only need a subset of the information
– The apps that work the best, utilise the data it stores for very specific functionality (think banking apps) therefore we think there is a use case for a specific edu wallet
– The stuff that you need supported won’t be covered in the government wallet
– Dependencies to government services aside, you might use Government data sources instead of fetching this data yourself when this data is more easily available
– Our institutions don’t have the staff or competences to handle the move to a digital credentials infrastructure
– In analogue the business processes can be handled by our institutions
- – Awarding bodies, will they need to also be involved with this ecosystem? Yes as they will keep track of student achievement as well.
- – A move away from 4 years of work for a student and receive a degree, to instead person has achieved module 1,2,3 that gets assigned to an individual wallet.
- – A train ticket doesn’t require a Passport, a plane ticket does require some information from the Passport – but the Passport is only needed once you are travelling – and it is easy to give out your Passport information to someone else so they can book you a ticket.
- – We will have to play a much broader role for the trust ecosystem – not just the user attributes but instead extended to the trust of issuing degrees, data etc:
– To be an issuer requires the adminstrative overhead involved.
SESSION #4, Breakout #1
Session Title: Open Source MFA
Session Notes Taker(s): Martin van Meulen, Lukas Hämmerle
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Lots of commercial options, what’s in the OSS world for MFA?
- – Commercial IdPs have MFA solution implemented
- – Commercial IdPs like Auth0 and Okta offer an MFA (Multi-factor-authentication) solution
- – Only few OSS MFA solutions:
– Keycloak: Has MFA integrated but can do a lot more
– PrivacyIDEA: Backed by German company NetKnights, mixed experience from universities with contributions/development requests. Came from LinOTP – there were issues at german institution, wouldn’t accept patch.
– eduMFA: A fork of PrivacyIdea. Supported by more than a dozen (mostly German) universities. Consortium formed to sustain development, plugins for various IdPs. Are in progress of forming a consortium for long term funding.
– LinOTP: PrivacyIdea was forked of this but seems not to be very active anymore, still a company active for selling LinOTP
– ESUP Portail: French consortium (https://www.esup-portail.org/), used for FER hosted MFA solution. France: Renater runs MFA as a service.
– Fudiscr (FU Directory and Identity Service): German universities use this mostly with Shibboleth
– OpenConext-Stepup
– Cirrus Identity: Use open source, but some of their software is closed source
- – What about non-web access?
– PrivacyIdea and eduMFA support LDAP proxy (password authentication against an org. ldap plus token string checked by MFA API), which can be used for PAM
– UI is an issue. The client has to support the authentication type.
– There are PAM modules. (mis)-use of OAuth code flow. Push notifications. Channel binding is an issue.
– Does any authentication type work with any device? No. Different devices support different things.
- – It’s important to have backup/multiple keys in an MFA system as end user.
- – Services should ask MFA depending on the role the user has in these services.
- – Google and similar providers that operate authentication and the actual services for end users can analyze the user patterns (i.e. how the service is used) and then enforce MFA in a risk-based manner if they think it’s needed.
- – Passkeys is phishing-resistant compared to other MFA methods (SMS token, TOTP token, TAN token)
- – Multiple components go into a MFA solution, these can be open source:
– a token registry
– an authentication solution (TOTP, authenticator app, FIDO2)
– Many open source solutions for authentication apps exist, e.g. Tiqr
- – Can a user choose the app? No, depends on protocol. The IdP will tell the user what to use.
- – Discussion about what is MFA:
– Is face ID multi-factor? Yes. Something you have (phone = something you have)
– MFA – biometrics.
– MFA is bad at availability.
– MFA is a means, not an end. It is there to mitigate risks. You need to understand risks for this to work well.
– Protecting access is hard.
– MFA is not user friendly. A user’s account being hacked is also not user friendly.
– You need multiple options.
– There is a role for stepup.
– Public devices and shared devices do not go together.
– You need SSO for usability.
– Passkeys are not SSO friendly.
– Continuous authentication.
– Phishing resistant MFA.
- – Why are passkeys important? Passkeys are different?
SESSION #4, Breakout #2
Session Title: Passkeys
Session Notes Taker(s): Filippo C (Switch), Peter H (SURF)
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Background:
15 years ago, project with Google called “universal second factor” (U2F), That migrated to FIDO2, and was then rebranded to passkeys by Apple. Different kind of passkeys with different authenticators (physical, digital wallets, …). Security considerations: passkeys may be shared/moved/… so it’s wrong to assume that they are bound to a single person. New way’s (UX) of passkeys are being developed, with different levels of support and success.
- – User experience from Peter (SURF):
Browser integration is a mess and opens a lot of different scenarios. Linux is more problematic but is being improved. Chrome on Linux should work well. As long as you are in one (apple) ecosystem it will work, all other combinations could work.
- – User guides are important, but it’s difficult to target all different cases. New features will come to browsers at some time, but at different timelines.
- – Primary school usecase at Switch, some manuals can be given, but you can’t cover all scenario’s. You can’t use attestation, but AAGUID isn’t stable either.
- – Some are using attestation, based upon the fido metadata service and sometimes are adding some others. Tiers based on the presence in the FIDO metadata: if present, acceptable for passwordless authentication, otherwise password is also requested after passkey (passkey acts as “second factor” before password).
- – Changes are coming to help embedded browsers allow passkeys. e.g. the RPs can have a list of “well known” embedded browsers that are allowed to support passkey authentication. Example in-app instagram browser visiting a webshop.
- – Other problems occur in appliances like chromecast.
- – If offering passkeys, also alternative methods are offered for cases where passkeys don’t work.
- – Refedsmfa is going to be updated with phishing-resistant mfa, that could increase passkeys adoption.
- – Recovery is hard 🙂
- – Background:
SESSION #4, Breakout #3
Session Title: InfraEOSC-WP3-Task 1 – CSC bid + Géant bid = ?
Session Notes Taker(s): Rob Smith, and…
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Zacharias and Licia has begun by describing in a high level way the concept of EOSC.
- – Discussion about the EOSC EU node and the fact that it was procured by the EU commission, multiple NRENs + Géant, the commission does not intend to run this service forever but they don’t want to end of life it suddenly. They want a succession plan. Max extension for the current contract is 1.5 years.
- – Some successor nodes have been funded.
- – Expectation that these new nodes will bring further nodes in.
- – Question around whether this is communication between four projects + existing nodes. Response is that this is happening but hasn’t been shared much.
- – Zacharias asks how we can build something and ensure that it doesn’t diverge. If the architecture is going to evolve how do we ensure interop and coherence.
- – János says there is a regular meeting and validation framework for participation in the EOSC federation; is of the opinion that this should be kept and that participants should need to be certified.
- – Licia clarifies that EOSC federation has mandatory requirements:
– compliance with EOSC AI architecture
– nodes must support catalogues
– considering adding others (helpdesk, security, etc) in future. Not currently mandatory
- – Requirements are now being gathered for 2026. Big question around how we do authorisation.
- – Zacharias challenges the assertion that the community is aligned on the end goal.
- – We want to end up in an environment underpinned by OpenID federation and underpinned by global federations. Time window + 5 years to get there expected.
- – “How important is OIDF” posed to nodes and the response was not very. More interested in maturing services, OIDF as an end goal.
- – Are there resources in the community to speed up adoption?
- – General agreement that using open source is preferred by the community.
- – Proposal to reuse components from one node within others. Node as a service offering?
- – Zacharias says that, since there is a weekly call and more alignment here than he had previously thought, that provides him an answer.
- – Licia has said it would be good if there are interop tests even as a proof of concept for some of the new things coming.
- – Topic of the session now refocussed to talk about some of the new nodes and what is going on with the nodes: EOSC association is doing updates on this.
- – Some discussion around whether there is a financial sustainability problem. Discussion of the VAT situation of charging for services cross border. Intellectual property question around EOSC services also raised.
SESSION #4, Breakout #4
Session Title: IdentityPython (https://idpy.org/)
Session Notes Taker(s): Laura Paglione, Ivan Kanakarakis
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:-
- – Matthew Economou demonstrated a mocked up test SAML flow in python. He used this to create a test platform to test SAML interoperability: https://federationcheck.incommon.org/
- – What would be useful for those using Identity Python tools?
SaToSa is a helpful tool, however…
– “As a proxy I always go to SaToSa”, though, as a library, they are too complicated to configure for a prototype use case
– Perhaps we should not spend any effort, time, money on SAML… OIDC / Federation tools could be a better strategy – but folks are still using SAML – to what degree to we continue to support them – Maintenance only or continue to add new functionality?
- – What’s the difference between the different efforts?
– Identity Python as an organization is relatively new – pySaml2 is the initial library that came to be a thing 16yrs ago
– SaToSa – in practice, this effort is using things that flask is doing; goal to make it easy to just “plug in” this work
– Web – flask: https://flask-saml2.readthedocs.io/en/latest/
– django Saml: https://github.com/grafana/django-saml2-auth
- – Challenges for Identity Python:
– Documentation and links to other efforts are difficult to find for Identity Python tools
– Additional plugins for other frameworks would be helpful
– There was a sunet project that Roland worked on with OpenIDFed. Perhaps we bring this into Identity Python. – there has been some work, but it’s not in the main branch at the moment.
– The library would need to be stable at some point – eventually available with other tools
– Needs new front end and support
– Does the hype match the need?
– Given the limited resources that this community has, we should be selective about what we provide and fill a gap that won’t be done by someone else
- – Where should we focus efforts?
– Fill documentation gap: Better / more documentation
– Address the following use cases within SaToSa – differing opinions:
– Enable proof of concept uses – libraries that are suited for straight-forward use cases with a high degree of ease of use. (plug in / abstraction layer) – “Python is my go-to language for proof of concept” (satosa is good a good defaults)
– Improving SaToSa – Flexibility for middle layer / proxy layer – SaToSa is the main thing being used:
– Testing
– Additional flexibility
– Create a pre-packaged solution for specific use cases? (EntreID) – or maybe create this in documentation?
– PySAML2 – make it easier to integrate with other frameworks (though not as well used as SaToSa)
– Re-establish the developer calls – increase engagement and feedback models:
– Will there be sufficient interest in participating?
– What is the ideal cadence?
– Increased promotion – who should be in this conversation?
– CERN (Hannah Short)
– SURF
– CILogon
– InAcademia (GÉANT)
– Core AAI Platform (GÉANT)
– AARC Compendium – software stacks to implement proxies – should SaToSa be included?
– EntreID Tenants << available as a service… EduID as a proxy << SUNET
– DAASI
– Some commercial companies
– PyFF – Still maintained by SUNET (one guy is still working on this) – may be a tool uniquely provided by IdentityPython
- – You can subscribe to the mailing list here: https://lists.sunet.se/postorius/lists/idpy-discuss.lists.sunet.se/
- – PyInfra for infrastructure vs Ansible:
PyInfra does the job; one participant mentioned not choosing PyInfra, but it was purely because of non-technical reasons
- – Federation Adapter (EntreID doesn’t support multilateral federation – it needs an adapter)
SESSION #5, Breakout #1
Session Title: What IAM Looks Like in Industry
Session Proposer: Heather Flanagan
Session Notes Taker(s): Nicole Roy
Discussion Setup:
- – Observations from broader industry trends, including insights from Identiverse (content chair perspective) and The Identity Salon (strategic 5-year outlook).
- – 7–10 year outlook: Research & Education (R&E) IAM has not fundamentally changed, while industry is evolving rapidly.
- – Historically, human trust enabled eduGAIN and positioned R&E ~15 years ahead of industry. That advantage no longer holds.
AI and Industry Momentum:
- – 25% of Identiverse submissions referenced AI; none of the TIIME sessions did.
- – AI accelerates processes. If processes are broken, AI makes them “fast broken things.” Focus must remain on fixing underlying processes.
- – Hottest topic: Delegation (acting on behalf of others, including agentic AI).
- – Industry sees rapid turnover and constantly revalidated permissions—changes happen in seconds.
- – Example: MCP agents. Aaron Parecki is working on tying MCP and OAuth together to integrate identity functionality.
- – AI/ML may benefit from R&E’s strong documentation and contextual frameworks.
- – Visa and Cloudflare partnership exploring identification and management of agentic AI bot traffic—determining what to allow and monetize.
- – Industry marketing often includes AI due to executive pressure, even when practical implementations are minimal.
- – Key challenges: Quantifying context and intent. Human judgment remains critical and cannot be fully trusted to automation.
Supply Chain Security (Non-AI Focus Area):
- – Strong awareness of software supply chain attacks; AI exacerbates the problem.
- – Key question: How do organizations effectively manage software supply chains?
- – IETF has three working groups addressing this:
- • SCITT (Supply Chain Integrity, Transparency, and Trust) – grounding document available by request via NCSA.
- • WIMSE
- • SPIFFE
Wallets and Verifiable Credentials in Enterprise:
- – Enterprise awareness of wallets and verifiable credentials (VCs) remains low.
- – In the EU, significant education efforts have been required; R&E and enterprise are at similar maturity levels.
- – Wallet adoption typically arises where government identifiers must be consumed (e.g., age verification).
- – Example: Utah’s SEDI project focused on age verification.
- – Tension exists between ISO mDL (e.g., MDOC) approaches and OpenID / W3C Verifiable Credentials models.
- – Blockchain continues to be used in some supply chain implementations.
Community & Events Mentioned:
- – IIW (Internet Identity Workshop) recommended.
- – DIICE conference in Copenhagen (June), organized by the same community.
- – All standards bodies currently engaged in AI-related standards development.
Key Themes & Takeaways:
- – R&E previously led through human trust; industry now moves faster due to automation and AI pressures.
- – Delegation and agent-based identity models are emerging critical areas.
- – Supply chain integrity is a parallel, urgent concern.
- – Human judgment, governance, and trust frameworks remain essential despite automation advances.
Additional insights and commentary can be found on Heather Flanagan’s blog: https://sphericalcowconsulting.com/
SESSION #5, Breakout #2
Session Title: Naming: eduID for education and research
Session Proposer(s): Floris Fokkinga (SURF)
Session Notes Taker(s): Filippo C (Switch), Tim W (DESY)
Discussion Setup:-
- – Isn’t it confusing?
- – Edu-ID and research-ID: ERID? Not catchy enough…
- – Changing name can be confusing for well established habits
-
- – Janos: Difficult to sell services to other sectors because “edu” restricts to a specific sector, not very well recognized by governance because “edu“ does not necessarily also contain “research”
- – Anass: eduroam in France: same issue. Eduroam sounds for higher education so other organisations and gov-institutions are confused.
- – Janos: Govroam sets higher expectations so it’s not interchangeable with eduroam
- – Anass: Same for eduIDs? Have students lower security expectations?
- – Janos: Not really coming from the students/involved people, depends more on the accessed services that can have higher requirements.
- – SURF: Also (mostly) institutions can have higher requirements for their members
- – Tim: using eduroam from university, don’t care too much about naming
- – Filippo: in CH edu* is used for universities, research institutions and libraries, tickets received very seldomly about the naming especially from library users that are not involved at all in the “edu” world
- – Jos: It’s about knowing that you’re authorised to use edu* resources
- – Janos: Should we take actions for these cases? Should we identify more cases where edu prefix is confusing? Example: eduroam in an airport. People don’t know what eduroam is and may complain for the “waste” of money
- – Gyongyi: Provide standardized meaning/communication of eduID initiatives across national initiatives?
- – Anass: eduID is called identitas in France and it is accepted also by researchers (just for the neutral name?)
- – Government: ministries (leaders) can control in a different way education/university/research depending on the country with different powers and structures.
- – Jos: educational resources and licenses have a significantly different price tag compared to standard licenses
- – Tim: distinction between edu* resources and general/commercial use necessary mainly because of better/cheaper license terms for R&E
- – It looks that eduID as name can confuse users and make it rejected from the target audience (e.g. researchers in Portugal prefer to use Science ID instead)
- – Gyongyi: Identitas from RENATER can be confused with another Identitas provided by the government
- – Eduroam had likely a similar issue in the past since it’s significantly more established that the various eduIDs. They do not refer to the educational sector in their website front page.
- – Proposed conclusion: keep edu* prefix because it is well-established in the R&E world
- – Logan: should we protect the domain eduID for the national level.
- – Adriana: should we have a basic faq about what the concept of eduID is / could be?
- – Serbia (?): initially hub and spoke federation with RADIUS. Was a pain to upgrade it. We may build an eduID on top on it, but for which goals?
- – Janos: some national federations are called “eduID”, for example Czech Republic, Hungary.
- – EduID without borders: eduIDs can mostly be used inside of national federations, but almost everywhere users are not usable via eduGAIN internationally. The eduIDs should agree on use cases for these users
- – Gyongyi: if you’re interested in getting updated about advances in standardizing eduID across the nations, leave your name here
SESSION #5, Breakout #3
Session Title: Could the AARC BPA be configured and deployed to act as a distributed API Gateway
Session Leader: Craig Lee
Session Notes Taker(s): Matthew Slowe
Discussion Setup:-
- – Christos notes the similarity of the proposed architecture to an EOSC deployment diagram
- – Ref: AARC-G075 for notes about using JWT tokens between infrastructures – some issues at the moment about cross-domain trust (should be “fixed” by OpenID Federation when that comes along).
- – Need to agree an authorisation model in advance – need that policy to be consistent so that Issuer-in-A understands how to issue a token allowing access to Service-in-B
- – BPA defines Resource Capabilities – what a given user can do on a given resource
- – Depending on use case, the token may pass the high level role (eg. PI for ProjectB) so that the remote service is empowered to implement the authorisation decision there… in other cases IssuerA may pass very fine-grained access entitlement claims (eg. Allowed to SSH into nodeZ) instead.
- – Is the BPA intended to be used where the Service Owners (at the bottom of AARC BPA) are expected to operate their own Policy Decisions? In some ways yes – the Service can be an API gateway which makes those decisions but BPA doesn’t define how it does that.
-
- – The initial service the user is interacting with [S1] wants to make an API call to a service on another deployment [S2].
- – S1 gets an access token from its proxy [P1] and uses that to make an API call to S2
- – S2 asks its Proxy [P2] to verify the token. P2 already trusts P1 and asks P1 to validate the token then passes that response back to S2
- – S2 makes an authorisation decision based on answer from P2
-
- – See also option for running a Service Catalogue which allows each deployment to aggregate their services up to a Global Service Catalogue out of band. This is not defined in BPA but see Resource Metadata for a starting point on how to systematically discover how to interact with other services.
- – Where do the Policy Decision Point (PDP) and Policy Enforcement Point (PEP) roles sit in BPA? It depends: different deployments have done this differently with some putting the them in each service while others let the Proxy make and/or enforce the decisions.
-
- – Different use-case in the Student mobility space but similar problems.
- – The following diagram derived from the NIST Cloud Federation Reference Architecture was used to motivate discussion and comparison with the AARC BPA:
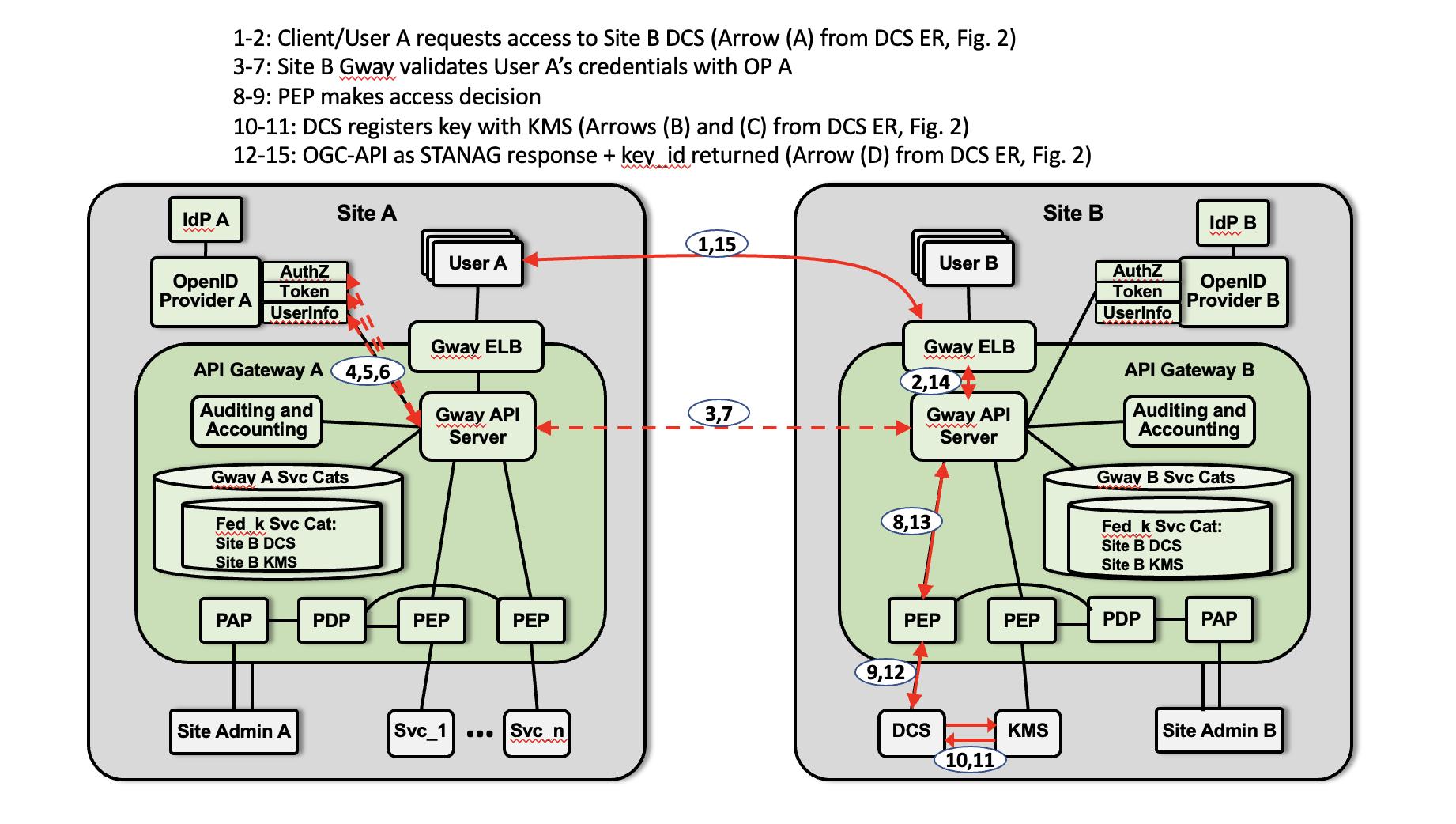
From: Lee, C.A., Federated Security, OGC 20-027, http://docs.opengeospatial.org/per/20-027.html, January, 2021.
SESSION #5, Breakout #4
Session Title: How to help operators trust the trust frameworks (David Crooks)
Session Notes Taker(s): Donald Chung
Key Summary:-
- – Aware of the issue that trust framework / agreed policy is circumvented in favour of “getting work done”
- – Trust framework is costly so would benefit from collaboration between FIM4R v3 and AARC to develop something similar to a PDK to support research community
-
- – Across the Grid, Certificate bundle from IGTF deployed to compute element
- – Issue: Transition from X509 auth → token auth
- – One community using CA that is not part of IGTF bundle
- – Jobs are unable to be executed
- – Problem: Increase likelihood for Operators to operate outside of agreed procedure and trust framework
- – Manually dropping the cert into the trust anchor
- – Disregarding trust framework agreed
- – Loss of experience and trust within community for expediency
- – Technology exists but not guidance or policy for building a trust federation (such as requirement, guidance, policy, and procedure)
- – Policy development kit is useful
- – Need to make trust into requirements
-
- – Technological agnostic solution for building trust federation
- – Don’t just be a security officer to say no
- – Where is the trust?
- – How to build trust fabric
- – ID federation within ENRAND has its own trust fabric
- – How to implement technology without breaking trust fabric
- – In the past, Grid is a federation; now we only have interoperable sites but no organisation to coordinate
- – ID federation has challenges to talk to each other
- – Should big research infrastructure also join as federation?
- – In the past, there are only limited options
- – No joint policy due to divergence in technologies
- – Losing oversight body
- – Service providers are creating ad-hoc trust frameworks
- – Often trust framework is of lower priority
- – Overlapping infrastructure outside of ENRAND space
- – They have trust frameworks already, just not in one place
- – Useful to build a template for trust framework?
- – Talk to AARC?
- – Important not to overdo the template
- – CATANRA (Kantara) business-oriented?
- – Actors are in more than one community and have acceptable trust but not interoperable with other communities
- – HE physics may have a higher standard
- – Change in trust and threat landscape breaking existing framework
- – Knowing that the above is a fact, how do we change our way of working to still provide enough trust?
- – Still useful for some baseline (such as AUP approach) sort of minimum baseline expectation
-
- – InCommon Baseline
- – Higher education moves slower than WLCG
- – To attract participants, standards/trust are relaxed to lower barrier of entry
- – eduGAIN: choice of different trust levels
- – Federation relies on transitive local trust (e.g. PGP)
- – Building trust barrier
- – Some communities are too small to be their own federation
- – Expensive to run federation
- – Sometimes even small cost is too much for someone
- – How to keep expertise of IGTF
- – How much trust policies are imposed vs. how much we think it is beneficial
-
- – Q: How much AARCTREE can we use and how much FIM4R as well?
- – Is this something that AARC should cover?
- – How do we re-envision the trust framework?
- – In WLCG, how to rebuild trust at service provider and infrastructure provider
- – Policy side of AARC is quite technical
- – No architecture for your trust
- – You need these policies
- – PDK for policies? Where do I get my trust from?
- – BPG
- – Some document adjacent to AARC document
- – Gap to distil AARC to a useful document?
- – Effective communication of these policies
- – AARC seems to become in parallel with community and leads to divergences
- – At the same time, some infrastructure might feel that it doesn’t 100% suit them?
- – Ad-hoc trust framework
- – Topology keeps getting rewritten
- – People not talking with each other
- – Engage FIM4R v3 to make them aware of this gap
- – Token transition is big and ephemeral (WLCG)
- – FIM4R can also lead to an AARC project
SESSION #6, Breakout #1
Session Title: EOSC AAI
Session Convener: Maarten Kremers (SURF)
Session Notes Taker(s): Floris Fokkinga (SURF) with assistance from Maarten
EOSC AAI – Christos
EOSC History
-
- – EOSC AAI WG (working group) meets every 2 weeks on Friday 9 AM.
- – Next meeting will be at 26 February.
- – This is the fourth generation of this group. It originally started in 2019/2020, by the EC (European Commission).
- – The EOSC community will not develop a new architecture, but it will use the AARC BPA and adapt it where necessary.
- – Research is global. EOSC needs to be able to interoperate globally.
- – In October 2024 the third generation of the WG started.
- – In January 2025 we got the permission to go, with a working implementation in November 2025.
- – An initial selection of 13 nodes, called the first wave.
- – The WG is an open working group. There are a few AAI experts across Europe, with limited time. There are about 50 participants.
- – The 4th generation of the working group was endorsed to continue to support the first wave of nodes, and start with the second wave.
- – Current 2025 EOSC AAI Architecture: https://zenodo.org/records/15388270
Goals & Requirements
-
- – What we wanted to achieve:
- Single sign-on across nodes
- Agents running on behalf of the user doing stuff on other nodes.
- – If we want to be a production node at the end of 2026, what do we need to do about AAI?
- – Requirements:
- >=1 infra proxy
- >=0 community AAIs
- >=0 users
- >=1 resources (services)
- – Whatever happens within the node, is not the business of EOSC. The requirements are for interoperability.
- – We use OpenID Connect, not SAML. Internally, you can do whatever you want.
- – We use MyAccessID as common identity layer for the federation. Users log in through MyAccessID. Local users can use a local AAI.
- – MyAccessID is also the hub of the federation and provides transitive trust (to be replaced with OIDfed in due time).
- – MyAccessID also provides remote token introspection.
- – In the future, MyAccessID will be replaced by OpenID Federation.
- – Of 13 nodes, 9 of them have implemented all technology required.
- – Other 3 or 4 offered services via the EOSC EU node (for now) and they will move to own nodes in 2026 planned.
- – The EOSC EU node has been in production since 2024, as the first node. It is scheduled to be disabled in 3 years time (?).
- – The EOSC federation as a whole is not production ready, although EOSC AAI is. The goal is to have this production ready in November 2026.
- – 3 of the 9 nodes are in full production for AAI.
- – What we wanted to achieve:
Going into Production
-
- – Legal entity
- – Privacy notice published
- – Terms of use published
- – Incident response: SIRTFI operational
Next Few Months
-
- – Getting into production. The 3 nodes that decided to go to production in 2026: CERN, Czech, German nodes
- – Second wave of nodes, currently applying.
- – We are evolving the requirements, we now have a minimum viable implementation. In the future, things will be ‘a bit’ different: wallets, OIDfed.
- – In the next update of the EOSC architecture, we will decide what pain points we need to prioritize for 2026.
- – For 2 nodes, assurance capabilities are very important, but not for all.
- – OpenID Federation is deemed too soon for 2026.
- – Wallets are also more suitable for the future beyond 2026.
Data Spaces
-
- – Data spaces are being pushed by the EC (European Commission). It is not immediately clear to us what they are.
- – The ‘Simple’ framework is under development.
- – The vision is: EuroHPC, EOSC, data spaces all will come together. We are on our way to unified access.
- – The next version of the EOSC AAI requirements is being worked on, we expect to finalize it by summer. Your experts need to be involved.
Production Readiness & Legal Aspects
-
- – What does it mean for AAI that the other parts are not production ready yet?
- Not much
- Going to production as EOSC federation. Non-EC nodes have signed a memorandum of understanding. For 2026 the goal is to have a legally binding document. This affects AAI, because it will state how tight or non-tight the integration will be. E.g., about data processing agreements. This will be complicated for across node cases with tokens.
- – About the agreement between nodes: do you expect this is going to be a major blocker, or do you expect this will go smoothly?
- This is the reality, we need to face it. For example, in eduGAIN, bilateral agreements also occur. But we cannot control this.
- – What does it mean for AAI that the other parts are not production ready yet?
Large Projects
-
- – We have had 4 large project requests granted.
- – EC had a call for consortia:
- Lead by GEANT
- Lead by EGI, with thematic and national nodes
- Lead by CSC: the main proposal to bring national nodes to EOSC
- Lead by Blue Cloud (?)
- – So called EOSC Infra 0101 calls
- – It is expected, the work that is done for EOSC AAI will be useful for research AAI in Europe and globally outside of EOSC.
SESSION #6, Breakout #2
Session Title: Getting More Research Communities to Adopt AARC / Tools and Models to Support the Upskilling of the Community in T&I
Session Convener: Sarah Thomas (AAF)
Session Notes Taker(s): Keith Brophy
Time keeper: N/A
Time: N/A
Location: N/A
Tags / links to resources / technology discussed, related to this session:-
- – AARC BPA (Blueprint Architecture)
- – PDK (Policy Development Kit)
- – FIM4R
- – AAF (Australian Access Federation)
- – CILogon
- – EuroHPC
- – NCRIS
- – SKA
- – GEANT T&I Incubator Program
- – WEHI (Medical Research Group): https://www.wehi.edu.au/
Key Questions Framing the Session:
-
- – How do we get people more excited to use AARC?
- – What tools can be developed to support increased adoption?
- – What best practice guidance can be shared to help upskill the research community?
- – Note: The Technical Blueprint Architecture is relatively easy to adopt, while the Policy element requires more thought and is more challenging to implement.
Increasing Adoption of the PDK / AARC:
-
- – Building on Existing Work (Liam):
People have taken the PDK and implemented it in their own way. Suggestion to find semi-related areas (e.g. HPC) and build upon what has already been done.
- – Directory of Use Cases (John S):
There is lots of AARC activity in Europe, but it is difficult to find documents and artefacts. Suggestion to build a centralised directory of use cases. Some pilots are very specific to one community — the challenge is how to scale or apply them through a different lens. Question: Is there scope to request that if you use the PDK, you upload/share your work? Is there a consistent way to enable this? Liam noted that examples have been built into the new PDK — each document includes examples, though consideration is needed around how these documents age over time (e.g. still relevant in 6 years?).
- – Feedback Loop in the PDK (Andy):
There is a need for a feedback loop within the PDK to enable sharing of feedback, which can help with iterations and improvements. A potential download request form was also suggested.
- – Marketing and Communications Challenge (David):
How do communities hear about the PDK in the first place? Reaching the audience is key: approaching SPs via their customers (rather than directly) is more effective — customers raising the issue makes SPs more likely to consider it. For institutions, SPs can be used to promote Federations, but SPs may not know who or where to point institutions within the Federation.
- – AAF Incubator Pilots (Sarah):
AAF has 9 incubator pilots that bring the PDK into activity. Question: is this a sustainable and scalable business model? Australia has 26 NCRIS institutions/capabilities/infrastructure — AAF has good relationships with partners, but there may be scope to connect through collaboration reporting.
- – Technology Before Policy (John S / David K):
Developing stories that highlight value to researchers and provide a clear pathway to connecting and use cases is important. Espousing the AARC PDK/BPA often meets the response that communities would rather not be told what to do and prefer to focus on technology — suggestion to start with technology before getting into policy. There is also no shrink-wrapped product that can simply be downloaded and installed, making it challenging to understand and deploy infrastructure. Success stories need to be made easier to share.
- – Alignment with Proposal Requirements (Scott, USA):
Potential to align use of BPA/PDK with existing requirements in the proposal process, showing that use of BPA/PDK aligns with other existing requirements.
- – Pre-Rolled Guides for Communities (John S):
Most HPC facilities have broadly similar requirements. Suggestion to set up simple guides for parameters to start an HPC project / open data — provide pre-rolled guides for communities that match certain characteristics. Question remains as to how this would scale/work in theory. David K noted that EuroHPC has the Commission forcing a federated approach, but there is still no evidence they will use common policies.
- – Domain-Specific Focus and Core Policies (Scott / Liam / David):
Potential to focus on a specific domain (e.g. astronomy — little need for privacy, potential to pre-fill). Sarah noted AAF is working with Astronomy and Genomics. Liam suggested a potential core set of policies for simple/initial stages. Scott suggested harvesting what smaller research collaborations have done and sharing those outputs to help others get started. Most people want policy in place for when something breaks — it enables conversations and helps understand the space. David noted astronomy as a good example where a broad set of initial policies has privacy-focused elements built on top. Increased usage and promotion of the PDK and sharing of use cases could develop momentum across the community.
- – SKA:
SKA is using their own policy development process — question as to whether the PDK helps start discussion/thinking and what benefit it offers in that context.
- – Building on Existing Work (Liam):
Policy Awareness and Operational Readiness:
-
- – Desktop Exercises (John S):
Potential to simulate a breach of infrastructure (desktop exercise) — working through the PDK to identify gaps: what they should do, who they should contact.
- – Operational Translation of Policies (David K):
It is relatively simple to write policies, but this does not always translate to appropriate operational activity in response to events.
- – Annual Training and Confirmation (John S / David):
AAF has started ergonomic handling and workplace assessments — annual training with certificate upload to confirm understanding/awareness. Suggestion to translate this to the policy side. There is a need for a reasonable expectation that people have read policies — a lightweight and frequent table-top process to re-confirm policies and supporting operations. David K noted this works well for larger collaborations but becomes difficult for small research collaborations.
- – Desktop Exercises (John S):
Upskilling the Research Community:
-
- – AAF Internship Programme (Sarah):
AAF is working with WEHI (Medical Research Group) on an 8-week internship programme with a mid-point check-in and a final presentation. Attempts are being made to set up an ongoing, formal connection: https://www.wehi.edu.au/
- – Challenges with Internship Approach (Scott):
Described as a complete failure at NCSA with astrophysicists and genomics researchers — lots of software development but a lack of awareness of CILogon. Hard for people moving through the system to know about available avenues, even when sitting in the same building. AAF noted it has lots of documentation tested with the community, and that engagement gives pathways forward.
- – Gap Between Federation and Research Software (Scott):
FIM4R highlights that people on the Federation side are often not aware of research software.
- – GEANT T&I Incubator Programme:
Open call for internships — one example started as a Bachelor student, had a good experience, and was offered employment at the end of the first year. Seen as a good channel for employment opportunities.
- – AAF Internship Programme (Sarah):
SESSION #6, Breakout #3
Session Title: Is There Any Interest in Incorporating Device Trust into Federated Environments?
Session Convener: Craig Lee
Session Notes Taker(s): Craig Lee
Time keeper: N/A
Time: N/A
Location: N/A
Summary:
- – Zero Trust design concepts map very nicely to what federations do. Federations define and manage trust boundaries, which is central to Zero Trust.
- – What constitutes trust can be extended to include device trust, i.e., the devices that users and services — including the federation hosting services — must be verified based on hardware rev, software stack, etc. Once verified, a cert is issued to the device. These certs can be traced back to a common Root CA.
- – In a federated environment, devices hosting users and services must all be able to trace their certs back to a trusted Root CA.
- – This manner of device trust is implemented by KeyScaler (KS) from Device Authority. The following diagram was presented that illustrates a prototype architecture.
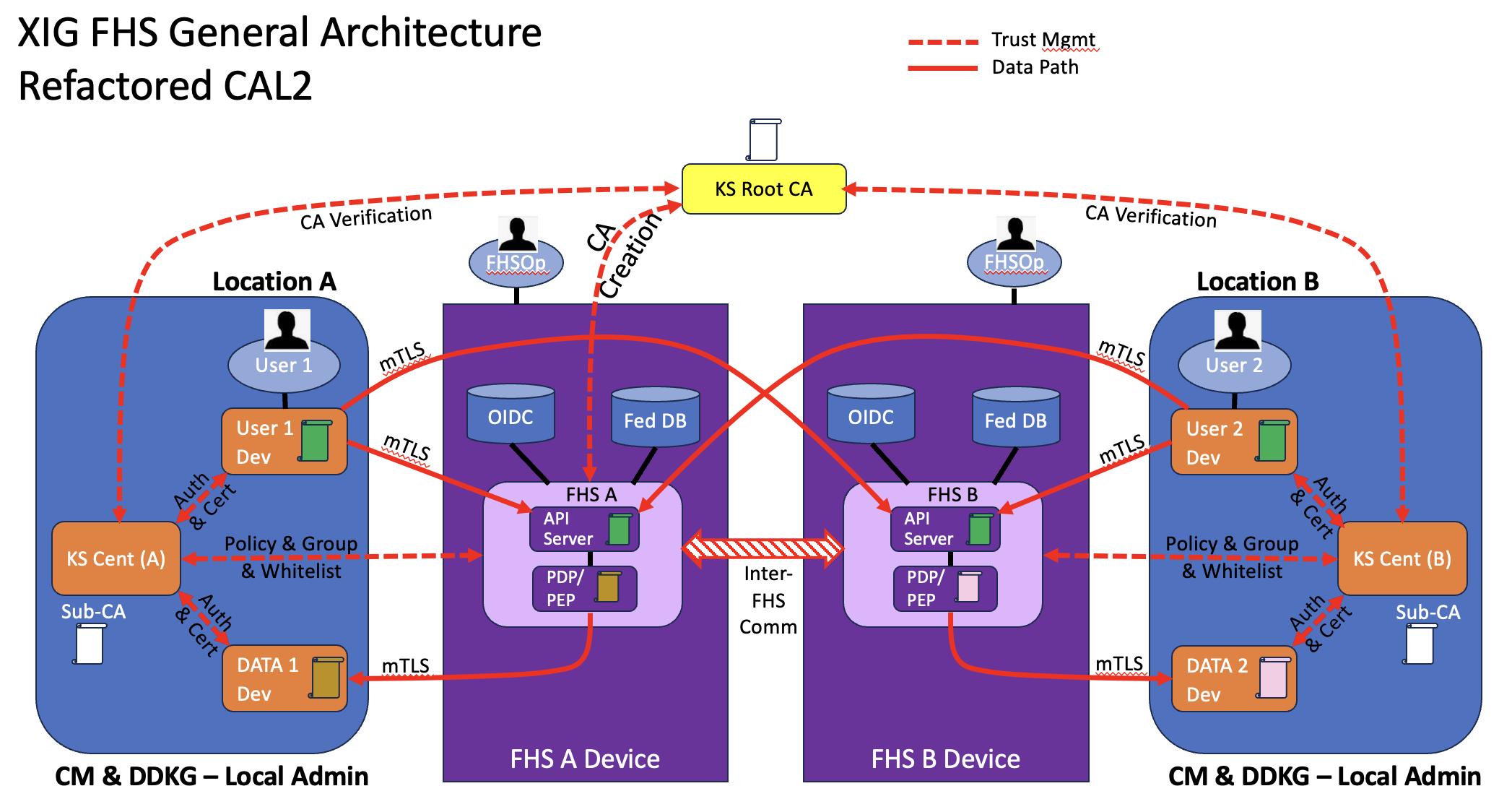
-
- – Other possible aspects of Zero Trust, e.g., configuring encrypted tunnels among federation participant devices, is also possible but was not discussed in this session.
- – While not of direct interest to R&Es, there are possible applications. One example is issuing certs to user/student devices on campus, e.g., x-boxes.
- – Scalability could be an issue. As the scale increases, having an actual common root of trust becomes hard to achieve. Device Authority is known to be targeting “factory-scale” deployments. It is unknown what their largest deployments are to date. (But scalability would be a good problem to have!)
SESSION #6, Breakout #4
Session Title: Hub+Spoke Architecture and OpenConext
Session Convener: N/A
Session Notes Taker(s): Bas Zoetekouw
Time keeper: N/A
Time: Thu Feb 12, 11:30
Location: Positron
Tags / links to resources / technology discussed, related to this session:
- – Hub+Spoke Architecture
- – OpenConext

-
- – SURFconext / OpenConext (Pieter):
SURFconext in the Netherlands uses a Hub+Spoke federation. SURF is redesigning the core of their federation (called OpenConext: https://openconext.org/). Would like feedback from community: what should such a component look like? What should we do and what should we definitely not do? Current status: brainstorming, not yet developing. Would like input from other federations.
- – Terminology (Martin):
Think about terminology (e.g. do not use confusing terminology like “frontend/backend” in Satosa).
- – Danish Hub Architecture (Martin):
In Denmark: uses a central hub for SAML in 3500 lines of Go. OIDC get converted into SAML at the edges. Internally, SAML is used as a data structure. No internal configuration, all external info comes from SAML metadata. All necessary metadata (including eduGAIN etc) in an internal SQLite db. Everything is mapped to SAML. Rely on cookies to keep state between requests/responses. No internal persistent session state. OIDC state is stored in tokens.
- – Cookie Blocking (Pieter):
Browsers are getting more and more aggressive about cookie blocking. Would like a solution without relying on cookies for state.
- – Fine-Grained Authorization (Pieter):
SURF needs to support also fine-grained authorization policies in the hub. So IdPs can set (e.g.) group-based access, where the groups come from external sources. Multiple external sources are present: external policy decision point, attribute aggregator from external sources. Main hub does call out to external component (also for e.g., MFA). About 30% of the authentications uses these advanced features like authz.
- – Why Not Shibboleth?:
It’s mature, modular. Internal access to requests and state is possible.
- – Single vs. Multiple Components (Pieter):
Current architecture has lots of small components, which adds complexity. Can we do this in a single component?
- – Pipeline Architecture:
Most products use a type of pipeline, with multiple steps that a request or response needs to take. Can we design a generic “pipeline” application to handle this? But not build a generic workflow application. Should be close to the problem domain. Pipeline (selection and ordering of steps) configured probably by static configuration.
- – Core Problem:
Our current product is ~20 years old, and is becoming hard to maintain, develop and deploy. We need something that we can develop on more easily and that should keep working for the next 15-20 years.
- – Existing Components (AARC BPA):
Are there any existing components (for example from AARC BPA) that can replace the components in OpenConext? For example MyAccessID/Satosa.
- – WAYF:
Uses hub, but from the outside it looks like a mesh federation (with separate endpoints for each entity, rather than a single endpoint of the proxy).
- – Pieter draws picture of OpenConext components.
- – SURFconext / OpenConext (Pieter):
-
- – Most of OpenConext is custom software (sometimes using parts or components from other open source projects, like SimpleSAML). Lots of the components are based on old software development principles.
- – Everything runs in dockers. Load is not really an issue, but system uses multiple nodes for redundancy.
- – Shibboleth IdP:
Is it an option to use Shibboleth IdP? Should be possible. Does Shibboleth still use SAML internally? Because we would like to move away from that. Need to look into that if this is an option. Not sure how well Shib IdP handles proxy usecases. French primary education uses it for their Hub+Spoke federation for 12M users.
- – Maybe use plain SimpleSAMLphp?
- – Keycloak can handle a lot of the functionality but doesn’t handle federation very well.
- – Most of OpenConext is custom software (sometimes using parts or components from other open source projects, like SimpleSAML). Lots of the components are based on old software development principles.
- – Everything runs in dockers. Load is not really an issue, but system uses multiple nodes for redundancy.
- – Shibboleth IdP:
Is it an option to use Shibboleth IdP? Should be possible. Does Shibboleth still use SAML internally? Because we would like to move away from that. Need to look into that if this is an option. Not sure how well Shib IdP handles proxy usecases. French primary education uses it for their Hub+Spoke federation for 12M users.
- – Maybe use plain SimpleSAMLphp?
- – Keycloak can handle a lot of the functionality but doesn’t handle federation very well.
SESSION #7, Breakout #1
Session Title: EOSC AAI
Session Convener: Maarten Kremers (SURF)
Session Notes Taker(s): Floris Fokkinga (SURF) with assistance from Maarten
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
EOSC History (Christos):
-
- – EOSC AAI WG (working group) meets every 2 weeks on Friday 9 AM. Next meeting will be at 26 February.
- – This is the fourth generation of this group. It originally started in 2019/2020, by the EC (European Commission). The EOSC community will not develop a new architecture, but it will use the AARC BPA and adapt it where necessary.
- – Research is global. EOSC needs to be able to interoperate globally.
- – In October 2024 the third generation of the WG started.
- – In January 2025 we got the permission to go, with a working implementation in November 2025.
- – An initial selection of 13 nodes, called the first wave.
- – The WG is an open working group. There are a few AAI experts across Europe, with limited time. There are about 50 participants.
- – The 4th generation of the working group was endorsed to continue to support the first wave of nodes, and start with the second wave.
- – Current 2025 EOSC AAI Architecture: https://zenodo.org/records/15388270
- – What we wanted to achieve:
1. Single sign-on across nodes
2. Agents running on behalf of the user doing stuff on other nodes.
- – Requirements (for a production node at end of 2026):
1. >=1 infra proxy
2. >=0 community AAIs
3. >=0 users
4. >=1 resources (services)
Whatever happens within the node, is not the business of EOSC. The requirements are for interoperability. We use OpenID connect, not SAML. Again, internally, you can do whatever you want.
- – We use MyAccessID as common identity layer for the federation. Users log in through MyAccessID. Again, local users can use a local AAI.
- – MyAccessID is also the hub of the federation and provides transitive trust (to be replaced with OIDfed in due time)
- – MyAccessID also provides remote token introspection.
- – In the future, MyAccessID will be replaced by OpenID federation.
- – Of 13 nodes, 9 of them have implemented all technology required. Other 3 or 4 offered services via the EOSC EU node (for now) and they will move to own nodes in 2026 planned.
- – The EOSC EU node has been in production since 2024, as the first node. It is scheduled to be disabled in 3 years time (?).
- – The EOSC federation as a whole is not production ready, although EOSC AAI is. The goal is to have this production ready in November 2026.
- – 3 of the 9 nodes are in full production for AAI.
Going into Production (Tackling the Policies):
-
- – Legal entity
- – Privacy notice published
- – Terms of use published
- – Incident response: SIRTFI operational
Next Few Months:
-
- – Getting into production. The 3 nodes that decided to go to production in 2026: CERN, Czech, German nodes
- – Second wave of nodes, currently applying.
- – We are evolving the requirements, we now have a minimum viable implementation. In the future, things will be ‘a bit’ different: wallets, OIDfed.
- – In the next update of the EOSC architecture, we will decide what pain points we need to prioritize for 2026.
- – For 2 nodes, assurance capabilities are very important, but not for all.
- – OpenID federation is deemed too soon for 2026.
- – Wallets are also more suitable for the future beyond 2026.
Data Spaces:
-
- – Data spaces are being pushed by the EC (European Commission). It is not immediately clear to us what they are.
- – The ‘Simple’ framework is under development.
- – The vision is: EuroHPC, EOSC, data spaces all will come together. We are on our way to unified access.
- – The next version of the EOSC AAI requirements is being worked on, we expect to finalize it by summer. Your experts need to be involved.
- – What does it mean for AAI that the other parts are not production ready yet?
– Not much
– Going to production as EOSC federation. Non EC-nodes have singed a memorandum of understanding. For 2026 the goal is to have a legally binding document. This affects AAI, because it will state how tight or non-tight the intergration will be. E.g., about data processing agreements. This will be complicated for across node cases with tokens.
- – About the agreement between nodes: do you expect this is going to be a major blocker, or do you expect this will go smoothly?
– This is the reality, we need to face it. For example, in eduGAIN, bilateral agreements also occur. But we cannot control this.
Large Projects:
-
- – We have had 4 large project requests granted.
- – EC had a call for consortia (so called EOSC Infra 0101 calls):
1. lead by GEANT
2. lead by EGI, with thematic and national nodes
3. lead by CSC: the main proposal to bring national nodes to EOSC
4. lead by Blue Cloud (?)
- – It is expected, the work that is done for EOSC AAI will be useful for research AAI in Europe and globally outside of EOSC.
SESSION #7, Breakout #2
Session Title: Research Assurance Architecture
Session Convener: Bo Nygaard Bai (DeiC)
Session Notes Taker(s): Matthew X. Economou (RDCT)
Time keeper: N/A
Time: N/A
Location: N/A
Slides: See the end of the document
- – EOSC needs a way for federation infrastructures to communicate compliance with agreed-upon legal frameworks on a global level (“trust in the infrastructure” vs “trust in the user”, knowing the infrastructure itself meets regulatory requirements and have pre-approved infrastructures). In GÉANT, Bo’s proposing a blueprint infrastructure for a common European object storage built specifically for research, which features sovereign zones to comply with data homing laws. However, any data controller can have any rules, so simple data classification isn’t enough. Some authority must approve the infrastructure or the data won’t go there. Right now, the identity federation tries to do this through attribute release, which Bo thinks is insufficient as identity providers cannot self-certify.
- – Data from a customer’s perspective:
- – Data needs protection.
- – Institutions need trusted data management.
- – Researchers need seamless collaboration.
- – Research infrastructures need seamless data exchange.
- – Compliance officers will probably handle the first two items, but researchers won’t get the seamless UX because to solve that problem requires building siloed, trusted infrastructure within a controlled environment (“trusted research environment”).
- – Has anyone come up with distributed trusted research environments? ELIXIR comes close, but they have essentially the same rules for everything and have a closed community as a result.
- – Out of scope:
- – data provenance
- – data integrity
- – data semantics
- – data formats
- – bibliographies
- – What should be served? Rules and regulations:
- – GDPR
- – NIS2
- – operational standards
- – information security
- – dual use
- – data sovereignty
- – Infrastructure must be certified by a data controller. That certification must be published somehow and used to restrict data transfers, i.e., so data may only be used on approved infrastructures. That’s different than being able to access the data by an individual.
- – Is this supposed to be evaluated in a formal policy statement in some automated way? Probably not (still reliant on contracts and wet signatures), but the infrastructure needs a way to determine SHALL/SHALL NOT in an authorization check.
- – This would be some kind of trustmark. Does that exist? The concepts are there. Craig Lee has done related work for the Crossroad Innovation Group and the Open Geospatial Consortium (OGC) related to federated security mechanisms; cf. https://docs.ogc.org/per/20-027.html.
- – It’s becoming more difficult for researchers to access distributed storage and HPC services because these trust relationships do not exist.
- – FIM4R was “just documenting the research community’s requirements,” and this effort could start there. Someone else would have to come up with implementations.
- – Would the trustmark be audited (and by whom) or self-asserted (via self-audit and peer review)?
- – Georgia Tech (GTRI) defined a trustmark architecture, where recipients had a wallet of trustmark profiles they could present to relying parties, who would validate that with the trustmark provider; cf. Figures 9 and 10 from the OGC report linked above.
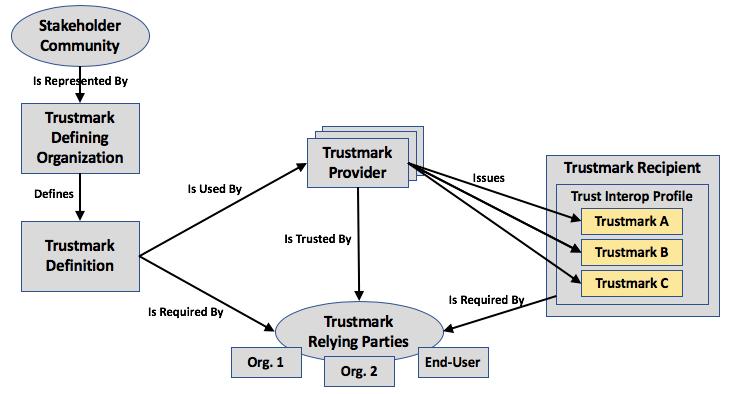
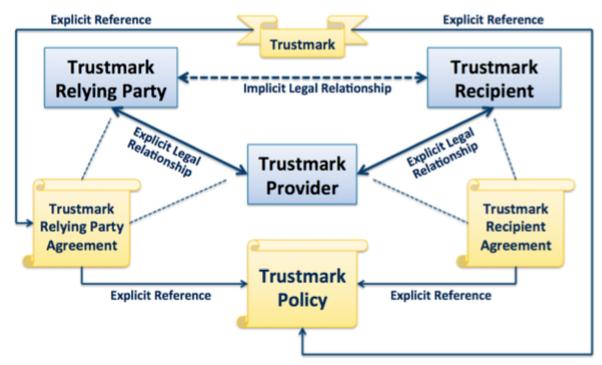
-
- – (From GTRI—the trustmark legal framework) The Georgia Tech project actually built something, but Craig doesn’t know where it ended up.
- – Bo thinks something like FIM4R needs to document the requirements and build consensus.
- – Matthew Economou described “system interconnections” per the NIST SP 800-171 Risk Management Framework that document and authorize these kinds of data flows for FISMA-compliant systems. How could those interconnections and authorizations get published at scale?
- – An European grid project had some kind of similar mechanism, which authorized not only the user but the data store.
- – This seems to be orthogonal to identity federation. Maybe this aligns with OIDF trustmarks (possible use case?), non-human identity, etc.
- – SLIDES:



SESSION #7, Breakout #3
Session Title: Trustworthiness vs Inclusivity: Where to Set the Bar in REFEDS Baseline Implementation
Session Proposers: Maarten & Davide
Session Notes Taker(s): Marlies Rikken (SURF)
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – How much do we want to raise the bar of compliance? How to remain inclusive?
- – Brave question – Hard to find an answer to this question. Probably need to compromise.
- – The extremes are both not wanted – can we tackle the concrete problem what is eduGAIN for – get identities with low assurance.
- – Getting to a ‘perfect eduGAIN’ It is not a goal in itself. The baseline is a means to solve some of the assurance issues.
- – What is useful? – an eduGAIN that can convey more assurance and meet expection of attribute release in a predictable way.
- – IdP an SP are interested in ‘It working’
- – Certified IdPs is low ‘about 20%’
- – eduGAIN strategy has been formulated (2025-2030). https://edugain.org//wp-content/uploads/2025/06/eduGAIN-Strategy.pdf
- – How to implement the eduGAIN baseline* expectations? Need an incremental approach.
*references futures working group recommendations, that are based on refeds.
- – Low hanging fruit = certify at entity level. Require institutions to have at least a security contact by end of year. Make mandatory later. Stage each set of requirements.
- – Try to implement requirements in small batches.
- – Non-compliant federations can be kicked out – but that is not what you want to be doing. What are alternatives, what is the ‘carrot’ and is there alternatives to the ‘stick’?
- – Need a paper trail or policy – is a non-technical requirement.
- – How can specific items be checked or be made ‘measurable’? – goes beyond this room (too specific)
- – Need to make visible what we are doing – the fact that we ‘have a security contact’ – does help increase trust if it is indicated.
- – So why is it a hard sell?
– Building awareness and communicating the ‘why’ is very hard.
– It’s a lot of work to manage all the entities.
– Getting people to add logo’s was a big improvement.
- – Responsibility is not usually a specific person – the one implementing is not always decision maker.
- – People need guidance on how to implement the requirements. Needs to be discussed in the involved committees.
- – More federations want to join – getting them on the right path when getting onboarded should help. Make sure there are good FAQ etc. (Still hard process, even with FAQ)
- – Has anyone done a mapping of SIRTIFI? https://refeds.org/wp-content/uploads/2022/08/Sirtfi-v2.pdf
- – When there is overlap with compliance by law it is beneficial.
- – Keep ISO and NIST2 requirements separated.
- – SIRTIFI can be a tool to implement those some sets of ISO or NIST requirements. That is a carrot.
- – Talking and thinking about it is a good thing – a start.
- – 20 out of 34 federations needed a bit of ‘coercion’ to deliver on the security contacts. What is the takeaway? Other requirements are more difficult to implement, so will be hard to say how long it will take.
- – We do want to be a part of this community and there is value – but actually doing it seems hard.
- – Implementing isn’t the work – its hard to get all the entities on signing off on these demands.
- – Cookbook/template – What are the next steps to prevent being excluded from eduGAIN?
- – Should we check on ability to implement? → if it feels like an option of saying ‘no’ that is not what we want.
- – EOSC nodes moving fast – eduGAIN moving slow
- – We live in a context with increasing security requirements – law and circumstance – make people worried with services can still be leveraged. Happening in all of EU.
- – Q: Should we invest in a currated comms package to help sell this?
- – Q: Can there be a plan for phasing the implementations?
- – Deployment guideline.
- – We have a 5 year strategy. Do need to communicate the full vision.
- – Communicate that this will be a standard – make sure its a recommendation that it is the best thing to do for yourself.
SESSION #7, Breakout #4
Session Title: Who is Missing from TIIME That Should Be Here, and How Can We Get Them Here?
Session Notes Taker(s): Logan
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
Who is Missing?
-
- – Smaller eduGAIN connected IdPs / federations.
- – The IdP operators are filtered through Federation Operators. If we could hear from IdP operators directly, that may be helpful in some cases?
- – Junior and mediums, younger folks, for sustainability.
- – Tool developers used to be present at prior TIIME meetings pre-COVID. Other tools which are less mature, could be nice to get them here.
- – South Africa, Zimbabwe, Ethopia, West Africa NRENS – folks from Uganda would like to see them here (they collaborate often) but they either don’t know about it or see the Europe part as meaning “not for me”.
What Are Barriers?
-
- – E in TIIME, cost, awareness
What Are Solutions to Barriers?
-
- – Invitations could be sent directly to federation operators before the conference. Could use the eduGAIN portal for this.
- – A pre session run by a friendly moderator which helps people learn the acronyms, familiar faces, etc. Could be a labor of love for the right mod. See ACAMP model via inCommon.
- – Maybe good if REFEDS meeting considers moving from TNC to TIIME
Misc Notes:
-
- – TIIME – The E at the end stands for Europe, is that restricting? We do see US, Australians, and Brits here. We don’t see as much from the asia-pacific regions. There has been talk about moving this meeting outside of Europe occasionally. Maybe Australia, Japan, Korea.
- – Advanced CAMP, ACAMP in the US via inCommon, unconference style. They started a pre-session for new people to come and get an introduction. Acronyms, people, context setting, who is here and why, what do they do. Could be high effort, but for the right person could be a labor of love. Could have parallel session in a less intimidating.
- – How to follow-up on this topic after the conference ends? The sort of logistical core of this meeting is via GEANT. Target next year’s sponsors and go to that group (possibly Germany, Marcus Hart) and talk to them about it.
- – General note that TNC meetings appear to be increasingly less relevant for T&I. Used to be spoiled for choice. Hallway conversations sure, but the content itself not so much. So TIIME is possibly going to be more relevant. TIIME might be the only remaining global meeting for T&I in this area of the world. REFEDS meeting may also make more sense at TIIME rather than TNC.
SESSION #8, Breakout #1
Session Title: REFEDS (RAF and Future)
Session Notes Taker(s): Peter Gietz, Romy Bolton
Slides to initiate discussion: https://surfdrive.surf.nl/s/NmFZgHdnK6Byx7a
Both meetings were put together, first on RAF then on Future of REFEDS
1.) RAF
-
- – Kyle Lewis participates online
- – Identity assurance framework and Authentication assurance (MFA)
- – All 41 NIH funded databases related to international collaborations are using RAF (CADR “NIH Controlled-Access Data Repositories”) and requiring a IAP High in the near future to access
- – List findable by NIH controlled access databases: https://grants.nih.gov/policy-and-compliance/policy-topics/sharing-policies/accessing-data/requirements
- – Currently it is known that 3800 institutions are accessing the NIH CADR so well beyond the US population of institutions so certainly international access is happening.
- – If the institutional process already is IAP high, signaling RAF is not mandatory
- – European organizations through the implemented frameworks are almost certain to have appropriate levels and will have an easier time than the US
- – In European student mobility the receiving institutions are worried about assurance of the information, at least in NL
- – REFEDS being the body that created RAF should also sustain it
- – Passport based validation will be mandatory in future if users want to use EuroHPC supercomputers.
- – In the US not anyone knows about what REFEDS is
- – NIH is an example of adoption
2.) Future of REFEDS
-
- – RAF is a reason for the future of REFEDS
- – REFEDS is important for accepting and promoting standards.
- – Projects like AARC have contributed to REFEDS ultimatly leading to such standards.
- – There still is a lot work to do, e.g. wallets.
- – If there is no REFEDS either others will do it in ways we dont want or it will not be done at all.
- – EduGAIN and REFEDS are intertwingled.
- – Is expectation to have a branding, as it is used today, or is it also about maintenance.
- – NRENS want common specs, a wg is founded and REFEDS is the place to do so.
- – Is REFEDS a SDO (standards defining organization)?
- – What we saw in AARC and now see in education: discussion is happening at different places. We have to be where those discussions take place.
- – Focus and scope is needed. We should focus on trust and identity, where REFEDS can play an important role.
- – All of these people use REFEDS standards every day.
- – If you want to be global it needs to be aligned with eduGAIN.
- – Standards need implementation.
- – Nicol Harris input document can be summarized as follows:
– Move REFEDS under eduGAIN
– Focus only on standards
– Appoint dedicated coordinator
– Streamline T&I landscape
- – REFEDS has produced valuable things, there may be expansion in scope. It is also a business sustainability problem. We need dedicated resources.
- – Further formalisation of the standards process is also needed.
- – Old discussion already took place: how we could do the process more formal.
- – What about other sectors, what about relation to ISO standards (too heavy weight processes).
- – A single community consultation with global input, as it is now was ideal
- – See also MDQ standardization at IETF takes ages.
- – What is exactly the problem: not enough standards? Not implemented standards? Is it both? Or are they not “standard-enough”.
- – Is adding an RFC-number to a REFEDS standard helpful for adoption? Probably not.
- – Its harder and harder to get people getting the work done? Running the process, organizing meetings, finding authors, etc.
- – Who points to SAML2Int? You get a 404. Kantara standards still exist on-line.
- – At least maintenance of the existing standards is needed.
- – Branding is really important and thus the REFEDS brand is important.
- – The same community has the same issues for different technologies (e.g., SAML → OIDC)
- – REFEDS endorsement is visual.
Key Challenges:
-
- – New T&I directions
- – Lack of governance
- – Overlapping fora
- – Low adoption of standards
- – Limited resources
-
- – A Key standard is RAF and some lawyers might not recognize REFEDS as SDO
- – SWITCH: Low adoption of RAF because it is not asked for.
- – REFEDS is the forum of the federation operators, who should require standards like RAF and then adopt it. Is adoption a problem of REFEDS?
- – Demands should come from the users or service providers not federation operators.
- – It would be a strategic mistake to move the global REFEDS under EU funding bodies.
- – It took 10 years to create the brand, it should not be moved
SESSION #8, Breakout #2
Session Title: What Should We Do to Handle the Risk of PQC
Session Notes Taker(s): Phil Smart
Discussion notes, key understandings, outstanding questions, observations, and action items/next steps:
-
- – Interest in PQC lots of crypto in a federation. The question about PQC is being raised at higher levels of organisations. Question how does this affect our federations. Other peoples approaches to mitigate this.
- – What are the issues:
– In netherlands there is a timeline for PQC, maybe 2030.
– US, NSA guidance is 2030. US federal government evaluate purchases that have good PQC stories. 2030 cut over for signing algorithms. This takes a long time for agencies to move.
– Look where crypto is used, look at encryption that can be intercepted. Store now decrypt later (is happening, storing)
– For authentication, that is point in time, you only have a problem when this becomes feasible. Symmetric key algorithms are infected, but not as much e.g. AES256 has the strength of AES128.
- – How do these algorithms effect performance? Bit of an unknown, they have drawbacks, slower, longer signature sizes, double precision maths. What about side channel attacks on these new algorithms, low powered devices.
- – Devices are much more powerful these days. ML-DSA (range of strengths) are an order of magnitude slower than RSA. Next generation processors make it possible for the higher parameter sets to be used in reasonable times.
- – From a risk management perspective, this is an annoying risk. John B. we are pretty sure this is going to happen.
- – How robust are the algorithms? They are new, classical attacks have broken some of the candidates. Hybrid schemes help mitigate that, chain the algorithms together. Is hybrid good? Some think doing both increases the attack surface (two signatures may break at the same time). NSA think it is really hard to get people to change, US defence is mostly RSA based (4k RSA) and one migration to ML-DSA. Europe are keener on hybrid signatures.
- – Follow the advice you are given.
- – Split, into meta data signing, and protocol signing. You could sign SAML metadata in a JOSE JWT e.g. in openID connect. Faster key rotation is one thing.
- – TLS will be updated, overhead of new TLS versions.
- – SAML elephant. Standards wise, it is dead.
- – Microsoft post quantum transition is OpenID Connect. What about government level? John B. get US government to identify where XML DSig is used, and look to migrate away from it (even some parts of DNS). Easier to migrate than get SAML implementations to support it.
- – TLS is being solved by others, what about others fixing the XML case? Dutch government needs it for the SAML case. Donald Eastlake might update XMLDsig signature identifiers etc. But still needs support.
- – Should we be trying to extend the life of SAML, or just move to something modern which has native support already (OIDC/JOSE etc).
- – From federation operators perspective, do they have a migration plan to OIDC federation. Parallel running between SAML and OIDC. Surf have been experimenting with that. Some smaller organisations are finding it harder to commit to transitions.
- – Moving SPs from SAML to OIDC is a huge effort.
- – JOSE standards work for PQC is mostly done, some work done in COSE which is linked to in JOSE. ML-KEM is slightly behind ML-DSA, some issues around that. JWE will be updated alongside this.
- – FIDO2 authenticators need to be updated as well. John B. looking on how you do key rollover in authenticators. Not started yet. Windows Hello has some prototype PQC. Windows Hello is now Edge authenticator. Windows Hello will hang around for single device, Edge authenticator will synch credentials like Google Password Manager.
The session explored the growing urgency of post-quantum cryptography (PQC) migration, with key deadlines around 2030 from both US and Dutch authorities. While new algorithms like ML-DSA are available, they come with performance trade-offs and open questions around side-channel attacks. Hybrid approaches are being discussed, though opinions are divided. The session highlighted that SAML is effectively end-of-life from a standards perspective, making migration to OIDC/JOSE — which already has better PQC support — the more pragmatic path forward. TLS migration is largely being handled by others, but XML signature migration remains an open problem. FIDO2 and authenticator key rollover are not yet addressed. The overall message: follow the guidance you are given, prioritise where crypto is most vulnerable (e.g. stored encrypted data), and begin planning migration strategies now.
SESSION #8, Breakout #3
Session Title: Infrastructure!
Session Lead(s): Matthew X. Economou (RDCT)
Session Notes Taker(s): Martin van Es
-
- – Matthew introduces himself
- – Telling about the failed attempt to discuss this yesterday
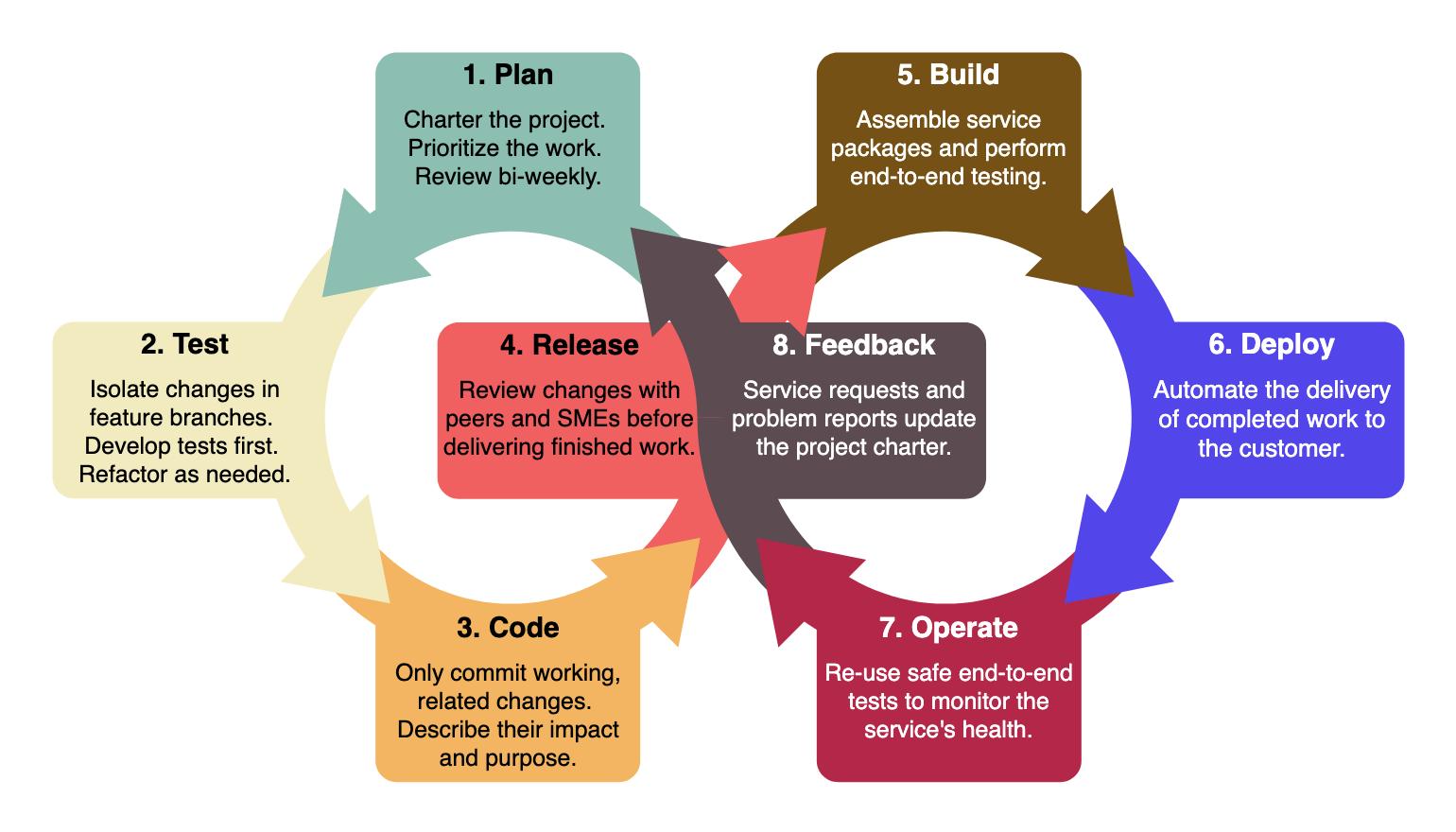
-
- – Matthew explains his story from private documentation
- – Test first!
- – Project management: Agile (Kanban, new – in progress – done) even physical, small sticky notes, write big! Small amounts of work per note.
- – They also practice ITIL (Build and Feedback)
- – Continuous delivery via Kubernetes using Docker images in AWS
- – Scanning is working against deploying from laptop, getting Firewall exceptions e.g. is Hell. Kubernetes solves that problem.
- – Helm chart vs Docker compose file, more of the same
- – A git repo for every location and environment, move shared defenitions in their own module.
- – Matthew is a big believer of Free software/Open Source software.
- – Use other people’s work (Kubernetes, infrastructure as code) and build from that (build on the shoulders of giants). A good developer is lazy.
- – Floris: How do you combine the idea of Free Software and working in AWS? Matthew: Kubernetes is Cloud agnostic.
- – Round question: what are we using?
– Nico (Norway): PAAS, Kubernetes manifest expressed in Python
– Just like Monarch (wrappers for CI/CD pipelines Matthew, internal only)
– SURF uses Ansible playbooks and roles to manage their infrastructure. Per-environment directories symlink to shared resource definitions. They automate using Docker Compose, with Compose project definitions templated using a Python script.
– RENU has scripts that manage their IdP containers, which they host on behalf of some federation participants (~300 institutions). Parameterized container images get customized from a CSV file. They’re using Semaphor (linked below), a dashboard that can perform Ansible deployments.
– SURF doesn’t use GitHub Actions for production deployments. However, they do test from GitHub Actions using multi-process Docker containers mimicking physical/virtual machines to ensure everything is deployable. Testing includes Selenium and Behave, which describes test in English sentences. (They do use Terraform to create infrastructure, but that’s fixed. They never redeploy.)
– SUNET uses masterless Puppet and Cosmos. Each server checks out the configs from Git and applies them every 15 minutes. Everything’s signed, so only trusted commits get applied. The Puppet manifests handle the Docker Compose invocations, etc. Their repositories are public, although private components are encrypted. They can also use Ansible when necessary. They have implemented secrets scanning to prevent unencrypted secrets getting published by mistake.
Cosmos: https://github.com/SUNET/cosmos-dpkg
Baseline for host repo: https://github.com/SUNET/multiverse
Main manifest repo: https://github.com/SUNET/puppet-sunet
Presentation about the tooling: https://github.com/SUNET/sunet-cm-tooling-presentation/releases
- – Code should be readable, just like you speak English, just like infrastructure as code
- – Matthew: git Head of main is production (Github). Nico uses Gitlab, but more or less the same.
- – Martin: Being able to run everything locally really helps developers!
- – Matthew: E.g. locally deployable IdP’s for SP’s trying to integrate in the federation.
-
- – https://opengitops.dev/
- – https://pyinfra.com/
- – https://www.pulumi.com/
- – https://opentofu.org/
- – https://devopswithdocker.com/
- – https://devopswithkubernetes.com/
- – https://tdd.mooc.fi/
- – https://www.digitalocean.com/community/tutorials/how-to-use-ansible-with-terraform-for-configuration-management
- – https://convergetp.com/2020/10/02/how-to-package-content-and-make-it-available-on-ansible-galaxy/
- – https://marp.kalvad.com/fosdem_2026 (PyInfra Fosdem talk)
- – https://github.com/ResearchDataCom/get-good-with-gitops
- – https://www.willmunn.xyz/devops/helm/kubernetes/2026/01/17/building-robust-helm-charts.html
- – https://semaphoreui.com/