GUT Profile
Session Convener: Mischa S.
Session Notes Taker(s): Nicolas L, Jens Jm Markus H.
Tags / links to resources / technology discussed, related to this session:
https://github.com/GUT-profile-WG/GUT-profile
There is a mailing list, a running notes document in Google docs
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps
Participants: 30 (!)
Goal: Save the scientific world!
Existing profiles:
- RFC9068 JWT Profile for Access Tokens
- AARC guidelines, e.g.
- AARC-G002 & AARC-G069 group/roles information
- AARC-G026 user identifiers
Issues
- Software developers need to handle several profiles
- We can standardise claims
- Opportunity to learn from experiences with the different profiles
- Can borrow from SCIM though they are very prescriptive which may not fit our needs
- No version claim (standardised)
- User identifiers (sub+iss, voperson_id)
- Need backward compatibility
- Authorisation
- Tend to use groups/roles at least on this side of the Pond, move towards capabilities
- some tokens designed for offline validation
- AARC profile has namespaces for groups but they get fairly verbose
we standardise claims: in a joint profile
- Parallel discussion is happening within DC4EU on university use cases, e.g.:
- student mobility
- diploma
- There are two profiles for bining access tokens to clients: DPoP and MTLS
- in one of them there is a private key residing on e.g. a mobile phone
- GA4GH: used in Life Sciences / Elixir
- Also a jwt token
- acts like a passport that can collect permits / visa that allow access to data
- Contacts:
- One person of Slavek’s Team (but I forgot the name, sorry!!)
- From ealier notes: diego.ciangottini@cern.ch is a contact for ga4gh
- ?
- Lifetime and revocation are out of scope for GUT profile (and covered by other groups)
- Recommendation from Vlad:
- Start with RFC9068
- Use IANA registry whenever possible
- Consider setting up a claim registry to register
- security group defined their own json container
- Avoid complext jwt substructures
How to move on?
- Visit the GUT github project
- Join the mailinglist: https://mailman.nikhef.nl/mailman/listinfo/gut-profile
- Event page: https://indico.nikhef.nl/category/93/
- Doodles (for monthly meetings) will announce varying timeslots, to ensure that everybody can join (EU, US, AP) frequently
Questions
- Are Distributed Identities / Wallet profiles in scope?
- Yep. Discussion there is ongoing (DC4EU)
- Do we need interop with wallets, ls and other attributes
- Do we just focus on the claims or also on how the access token is bound cryptographically
- If there are multiple issuers
- Can we handle more specialised cases, like the medical case, access to genomics data
- Would it be helpful to have a survey a la RFC 9068
- Nicolas has presented a cross-profile comparison: https://docs.google.com/presentation/d/1kVnnXBB0IjD24PU3BW7tfoLiBrCaQvC1zBZfiJ04xo0/edit#slide=id.g11972d451b4_0_15
- Does it make sense to have a basic profile (core) with optional extensions
- E.g. RFC 9068 as the base profile
- Benefits: Can use existing client libraries that have support for it
- IANA registry
- Basically we need to reinvent namespaces – for jwt claim names
- Could do an OIDC spec instead of an RFC which would be a more lightweight approach
- E.g. RFC 9068 as the base profile
- Do we know how many kW we burn verifying signatures etc, like RSA signatures. EC would be cheaper
- An initial assessment on RSA yielded about a GW globally (equiv to 1 powerplant)
Actions
- Christos to reach out to GA4GH people to get them involved into this group
- Consider running rounds of surveys
Passkey / FIDO
Session Convener: John Bradley
Session Notes Taker(s): Zacharias Törnblom, Niels van Dijk, Matthew Slowe
Tags / links to resources / technology discussed, related to this session: FIDO2, Passkeys
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
- “In the beginning” (NABI -> U2F -> Fido2)
- RP sends a challenge
- Browser routes that to the device with a challenge – make credential and create assertion (cryptographic pairwise)
- The answer is then used to register the user/device
- The RP looks up the user and sends over a list of their previous registratered devices
- The hardware device finds the one they recognize and prompts the user to touch the device
- Sign in happens
- Fido 2 added user verification
- When the request (if its prefered or required) is sent with the allow list
- In the response it will tell the RP if the second factor has been used
- Apple doesn’t always require the second factor (because it might cause security problems if the user is asked for their login password over and over)
- How do we answer the question:
- You probably don’t need Yubikey 5’s, unless you’re signing software or
- The security key-series that just provide Fido2-tokens is mostly sufficient
- Suggested UI: Decouple the “who am I” from the authentication option
- The idea being that once you’ve looked up the account you can provide them with the options specific for this account.
- Google and Apple and Microsoft have platform authenticators inside of their platforms.
- Passkeys replace Passwords
- A Passkey is a type of credential that isn’t an authenticator
- They don’t require an allow list
- Passkeys replace Passwords
- All phones apart from Chinese made phones that can’t use the Google Play
- A Yubikey, for example, with the proper setup will meet the eIDAS High-requirements
- Apple will spread the Passkey across their accounts different devices, and also share it with someone else – they are super convinient but might not be very secure
- A multidevice Passkey are kind of all (Something you are, Know, or Have) and none of them at the same time – since their sharable (so its not something you have) and they are not
- A relying party will not be able to see how the authentication has been done or the security features of a users account – thus they have to assume the lowest common denominator
- How to deal with the “unexpected” ways users may treat their accounts – especially when getting new devices (new device == new AppleID == no credential restore)
- Q: Do passkeys remove problems w/ account recovery? No: while it improves the problem, usres are likely to still find ways to mess up. What e.g. when users get a new mobile phone: this in practice may mean they get a new icloud account. It may just go the same way w/ passkeys.
If you want to read up on passkeys in an R&E environment, have a look at “Passkeys Use and Deployment for R&E Services” https://zenodo.org/records/10210492
Not all PassKey providers are created equal, some are not behaving as well as they should and one should check for FIDO certification if you want to be sure the rules are being followed correctly. (eg. Bitwarden?)
Proof of User Presence is aiming to reduce the attack surface for malware rather than ensuring that the correct user is present.
Safari had some issues with user attestation – where it supported the process but segfaulted when using it from the platform (but not external keys). Apparently now fixed.
Some lengthy discussion about the finer details of synchronisation of keys across devices, “sync fabrics” and between ecosystems. Various flags (Backup Eligable & Backed Up booleans) and supplemental public keys (device and syncfabric) are important to verify if an RP wants to be really sure an authenticating user is them when the pop up on a new “fingerprint”.
Discussion about “hybrid” (handing off the user-presence and key signing to another device via TLS and Bluetooth). Requires internet connection to establish TLS tunnel via “browser vendor proxy” for key exchange and bluetooth to ensure proximity.
How do we support EU alliances better?
Session Convener: Peter Havekes
Session Notes Taker(s): Marlies Rikken
Present:
- Victioriano Giralt -> in committees for one of the alliances (uni malaga and others). Are looking for solutions for alliances. Erasmus without papers, etc.
- Arnout Terpstra -> working on SRAM , can potentially support these usecases.
- Rancor -> Uni belgrade – Circle EU allianceFederated eduGAIN style structure. looking to integrate apps and courses more closely. Like to know if similar alliances have something to learn
- Marnti -> just here randomly!
- Thomas -> DCEU, start up, want to make wallets, ebsi learn
- Understand how legal and tech framework can be put into practice.
- Tomas, -> know more how to participate in alliances.
- Peter L. -> architect at SURF, help higherEDU standardisation workgroup.
- Lucas -> also random! Enlighten me!
- Michiel 0> like unconfenecresw
- Casper Dreef, GEANT -> workpackage to enable communities. Has money!! Looking for people to work in the work in the workpackage. Please send your proposals to casper.dreef@geant.org
- Marlies -> SURF , eduID NL & guest onboarding . We are getting approached as individual NREN to support , we have good services, but
- Bas SURF
- Francisca Martin-Vergara. University of Málaga
Opening question:
Questions asked by Dutch Uni’s that are involved in alliances. Difficult to follow collaborative courses, much paperwork. How to help students enroll with ”one click”?
Used Open Education API on the websites.
Made it possible to approve with oauth, enroll with NL eduID. Prove they are a student with oauth token.Make sure all info is present to enroll and go back to.
Euroteq technical studies: like the setup and wanted a similar setup.
No centralised oauth token provider or scope validator available.
How can we fix that?
Discussion
Issue for alliances -> Alot of good services at SURF. But it’s ”just” a national NREN. Can it be opened up to be used by other alliances?
Not all members of alliances are in the EU. Sometimes countries leave the EU.
Where is the problem? Tech/Policy/??
Seems like there are agreements between the alliances.
Technical solution can be chosen, but who will be responsible for it?
There are multiple federations and alliances, but not real hierarchical structures. Things happen because ”everyone agrees” and it doesn’t cost too much. Alliances do seem to have money and people available.
Individual alliance partners cannot solve these issues. Above that is the NREN, if individual NREN cannot support it, then GEANT?
Christos CORE AAI initiative might be a direction.
What is the current situation? Seperate identity and student numbers?
Exchanges that happen at Erasmus level:
can work via ESI (dreadful). Duration is limited to the exchange. Unique identification only available during the mobility. Then the Uni forgets about you and history is kept at the home institution.
Oauth/token method:
Using oauth and tokens. People select a course, select a course in Denmark, and then automatically arrange is. Needs a central authentification service. So needs something European to make it work.
This would be too modern for EWP. EWP method is not student centered.
Need solutions that also work at front side, provide students direct control.
EMREX approach is similar to oauth/token method. Still needs a central authorisation server.
What if a student gets results and forwards to home institute. How does the home institute validate? Problem of transport and problem of validation/interpretation.
If each alliance needs to figure this out for themselves would be a waste. Could there be a general platform for this? Integrate existing content and attributes to systems. In a way that legacy systems could also use these attributes.
Workpackage for profile of educational credentials in Malaga on 19th and 20th of feb. related to DC4EU
Need infrastructure support to help institute.
Automate transport system and need to convert to local standard / grade systems. EWP is building converters (wip).
Alliances should do checking / translation / mapping to see if the standards match their common needs and note what is missing from the standards. Don’t expect that all surprises can be avoided.
Is it possible to do a project on curating which alliances are there, what their issues are, what the solutions we could offer? Note available technologies. Make GEANT whitepaper, to note how to solve in a more general way, not another new solution. Potential to step up towards EU, workgroup.
Could map ontologies and transform to standards of different institution, could already start coding to realise this?
Translation of the formats
Need a solution in one month for Euroteq. Some good hopes in CORE AAI project, extend GEANT project. Pilot code that supports the use case will be made and will be open. Would be nice if eduGAIN can support these use case. Has to be on EU level. NRENs individually can make it work, but better on EU level.
See how eduGAIN solution maps to the requirements of alliances / use cases. See if institutes/alliances can respond to the use case.
Making the complete solution on paper is hard, also need to start work. Possible for SURF to help alliance when a NL institute is in the lead. Meanwhile governance issues should be figured out on the EU level.
Should seperate content from the transport method. Semantics and syntax and transport..
Internet is transport agnostic -> should adapt to be agnostic on higher layers as well. Adapters should be central, can be placed anywhere. Should be same protocol to do the translation.
What matters for people in edu: being able to interpret the content.
Tech community should keep in mind what value this brings to the end user.
Alliances trying to find if other solutions have been made at other alliances. Should not be like this, should be easier to support and share knowledge on this.
Transitive Trust of Assurance across eduGAIN
Session Convener: Matthew Slowe
Session Notes Taker(s): Liam Atherton
Tags / links to resources / technology discussed, related to this session:
Context
How can a Service Provider/Relying party in one part of eduGAIN know/trust that an IdP in another part of eduGain is conforming to specific requirements?
Examples:
REFEDS Assurance Framework assertions
MFA profile compliance
SP trusts an Auditor to audit an IdP such that the metadata is trustworthy
Auditor outputs a signed statement into the Entity Descriptor so that the relying party can check it and trust that the metadata is trustworthy
I have a diagram to attach here but no permission to do so… please contact matthew.slowe@jisc.ac.uk
Discussion notes
What’s the basis for the trust?
- If it’s an audit that doesn’t scale
- Audit firms dont audit this risk, they are more focussed around business risk
- GAKUNIN do more “reviews” with kantara to develop trust
- May scale better through federated reviews
- Reviewing can take a long time, maybe half a year for each IdP. Needs to be updated every time operating procedures are changed
- A federation may be the only place to do a reasonable audit
From the SP perspective:
- This seems like a lot of complexity to make sure that an IdP is asserting properly
- For ORCid if you want to check GDPR compliance you can look it up on the website rather than going through a long and expensive process of auditing and digitally asserting.
- Is the reputation hit of being found out to be falsly asserting compliance enough?
- Could a self assessment be enough?
- There is self assertion to be part of EDUGain that you abide by the rules
- Judgement is done case by case on a per federation basis
- Trust works within your federation
- What does trust mean?
- A lot of EDUGain metadata is optional
- Have to trust the path including the relationship between FederationB and the IdP
- There is self assertion to be part of EDUGain that you abide by the rules
- For ORCid if you want to check GDPR compliance you can look it up on the website rather than going through a long and expensive process of auditing and digitally asserting.
The cost for an audit falls on the IdP?
- Does any IdP have the money for an audit?
- Any university IdP will not do it
- How do we distribute trust for the auditors:
- Establish trust through the federations
- The cost would fall on the Federations
- EDUGain is about 80 federations so 80 certificates
- 80 certificates is a manageble amount to audit
LUMI tried to get medium assurance as a requirement however users started to complain as they couldnt achieve that level of assurance
- Lawyers have risk aversion and so IdP’s may not wish to become liable
- LUMI have “postponed the date” to achieve the required level of assurance
Would the processes in SWAMID scale?
- no
- there are 50 IdP’s
- A lot of time and manpower to federate those IdP’s
- Came from the universities that they want to trust each other
- All teachers need AL2 if not are frozen out of centralised system
- Assurance levels are public
- Slightly above REFEDS low/medium/high
- https://wiki.sunet.se/display/SWAMID/SWAMID+Policy#SWAMIDPolicy-SWAMIDIdentityAssuranceProfiles
action items/next steps/outstanding questions
Role for Edugain to not accept federations that assert attributes outside of their scope
Web Wallets are the Bomb
Session Convener: Niels van Dijk
Session Notes Taker(s): Mary McKee
Tags / links to resources / technology discussed, related to this session:
- AARC project (https://aarc-project.eu/architecture/)
- RUST-based issuer: https://github.com/spruceid/oidc4vci-issuer
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Ecosystem:
- Institutional identity provider – providing basic credentials (name/email/affiliation)
- Attribute authority – something the research community is running to express rules/business logic for establishing membership validity in community
- Service Providers – e.g., compute resources, storage, datasets, document sharing, etc. International
- Proxy – the glue between the three
- Takes credentials
- Aggregates from IdP and attribute authority into combined set for the service provider so it can establish identity
This was worked out by AARC project (https://aarc-project.eu/architecture/) – this is a lightweight version
Background:
- Proxies are helpful but not without challenges
- Could we have a wallet-based model so user is in direct control of credentials etc ?
- EU is focused on mobile-based wallet, but not everyone can or wishes to use mobile to engage with all these credentials
- Maybe we could create an ecosystem to keep credentials more close to where they are needed – through the browser
- Hoping to create an interoperable ecosystem with wallet-based ecosystem
- Benefits
- No dependency on mobile device
- Credentials are closer to where they are needed
- Browser-based will be easier than mobile dependencies (dependencies on major mobile device providers and their requirements) to deploy and maintain
- SFA/MFA
- Possible solution to long-term storage of combined sets of user credentials – Research AAI, eduAID
- Considerations:
- Current implementation not suitable for ARF Type-1 data
- Not all passkeys are created equal (may need specific versions with specific capabilities)
Use Case + MVP:
- Trusted, wallet-based access to genomic DB
- Researcher applies to access for DB, sends application to MMS presenting personal ID and email from wallet
- MMS notifies committee that someone wants to access DB, committee makes decision and sends response to MMS
- MMS notifies researcher of approval, researcher re-presents credential
- Access is established
- Demo
- Add a credential in wwWallet
- log in with passkey + user verification
- Add a new credential – National Verifiable ID Issuer
- Consent to sending credentials to wallet
- Wallet now has verifiable credential
- Add another credential – University of Athens
- Add another credential – EHIC (European Health Insurance Card)
- Use case – employer (ACME Verifier) is looking to verify user’s deploma
- Scan QR code or open with wwWallet
- Select wwWallet, open browser-based wallet
- Select credential, return to verify
- Considerations
- QR codes may be more viable for user experience
- Need to look at integration with other products (other wallets, other issuers, other verifiers)
- Add a credential in wwWallet
SpruceID:
- Issuer used for testbed: https://github.com/spruceid/oidc4vci-issuer
- Proof of concept ready, limited documentation but nice code
- GÉANT T&I Incubator contribution: merged documentation, future plans to implement certificate load instead of hard-coded cert, testing
John Bradley
- WebAuthn level 3 includes “PRF”, some browsers are adopting early
- Any device you can run Chrome on, you can use security key + PRF extension to allow wallet to send a seed to authenticator to create a new crypographic value to encrypt credential store
- Wallet allows you to register multiple keys against same credential store
- If you register same key on desktop and platform authenticator on phone, you can use either (using Hybrid Transport) to encrypt/decrypt credential store and have running as progressive web app on android phone
- Can have multiple authenticators, back up authenticator, you can get back in if you lose one and be able to instatntiate on any device you can use your authenticator on
- Back end storage is encrypted blob encrypted by multiple keys (any of which can decrypt) – this works fairly well
- Currently a bug with Android that affects interaction with hybrid – to be resolved
- Expected that Apple will also support PRF (perhaps after webauthn L3 is rolled out)
- The reason Google implemented in Chrome is because a lot of password managers are using it, we are using the same technique for web wallets (similar to a password manager wallet)
- John and Leif have a vision that not everyone in the world has a mobile phone. We can’t disenfranchise people who don’t have the latest devices. We need a range of complements to mobile-based wallets for inclusivity. In addition to web wallets, perhaps even governments could distribute FIDO authenticators/smart cards with national IDs/digitial credentials.
- Proposal:
- WebAuthn extension – PID-based raw signatures
- Command to get seed
- Wallet talks to authenticator (security key, etc., including whatever authenticator requirements)
- Authenticator creates seed for hierarchical keys (seed creates two other crypographically-related seeds – public and private, public can make many other public keys that all look like unique public keys unless you have the seed to see the relationship, private can mint private keys for any of the child public keys)
- Wallet operator can then create any number of attestations (e.g., issuer, make n credentials to store in wallet) without needing to do more than one operation with the security element/key
- For each presentation user needs to put in PIN/biometric/etc
- Even if someone got access to your wallet, they would not be able to use the credentials without the security element
- Good mix of security + user experience – technique to let external security add security to wallets operating outside of smartcard contexts
- There are going to be a lot of different wallets – API to allow multiple wallets to live on the same device so you can have (e.g.,) a mobile drivers licence request that allows you to choose from wallets that contain mobile drivers licenses (an EU wallet, or a US-based wallet).
- Similarly, you could pick wallet on your phone for request originating on computer. Cross-device flows with QR codes have known problems (attack vector successfully being exploited), this allows you to use hybrid transport similar to webauthn session previously
- WebAuthn extension – PID-based raw signatures
Questions:
- Can I choose where I want to store this stuff (iCloud, etc): could be similar to use of password managers, whatever your preferred syncing message is. Brower API lets you choose where and how to store so that when verifier asks for x, you can choose where you stored x. Trying to maximize choice
- How did some of these QR code attacks happen? not all implementations adhere to W3C requirements, that was enough for scams getting people in Singapore to log in with national ID, resulting in access to retirement savings
- Verifying – private material never leaves the security key? yes, you can’t correlate
OIDC device code flow improvements
Session Convener: Bas Zoutekouw
Session Notes Taker(s): Marcus Hardt
Bas Arnaud Mischa Marcus Manuel Tom James Tomas Tangui Pavel Janne
- Problem with device code flow is that it was meant for not-always-online devices (e.g. a TV)
- Fishing problem: get another person to click on the right link, the attacker can e.g. ssh into a machine
- With ssh and device code flow coming, this might become a big problem
- Ideas on what can be done
- Add one step where the logging-in user is prompted for the actual authorisation code displayed on th elogin page.
- This additional info is requested from the AS, even if the code was part of the URL followed by the user
- This ensures the authenticating user at the AS is the same that sees the code on the e.g. the ssh server
- Any impementation should always limit the lifetime to “short”
- User might be on the same IP, but that is kind of an edge case
- Add one step where the logging-in user is prompted for the actual authorisation code displayed on th elogin page.
- Important to understand the use cases
- TVs will have public clients
- SSH servers will be private clients
- 2nd factor pam module
- Blackboard: https://marcus.hardt-it.de/PXL_20240131_114227356.MP.jpg
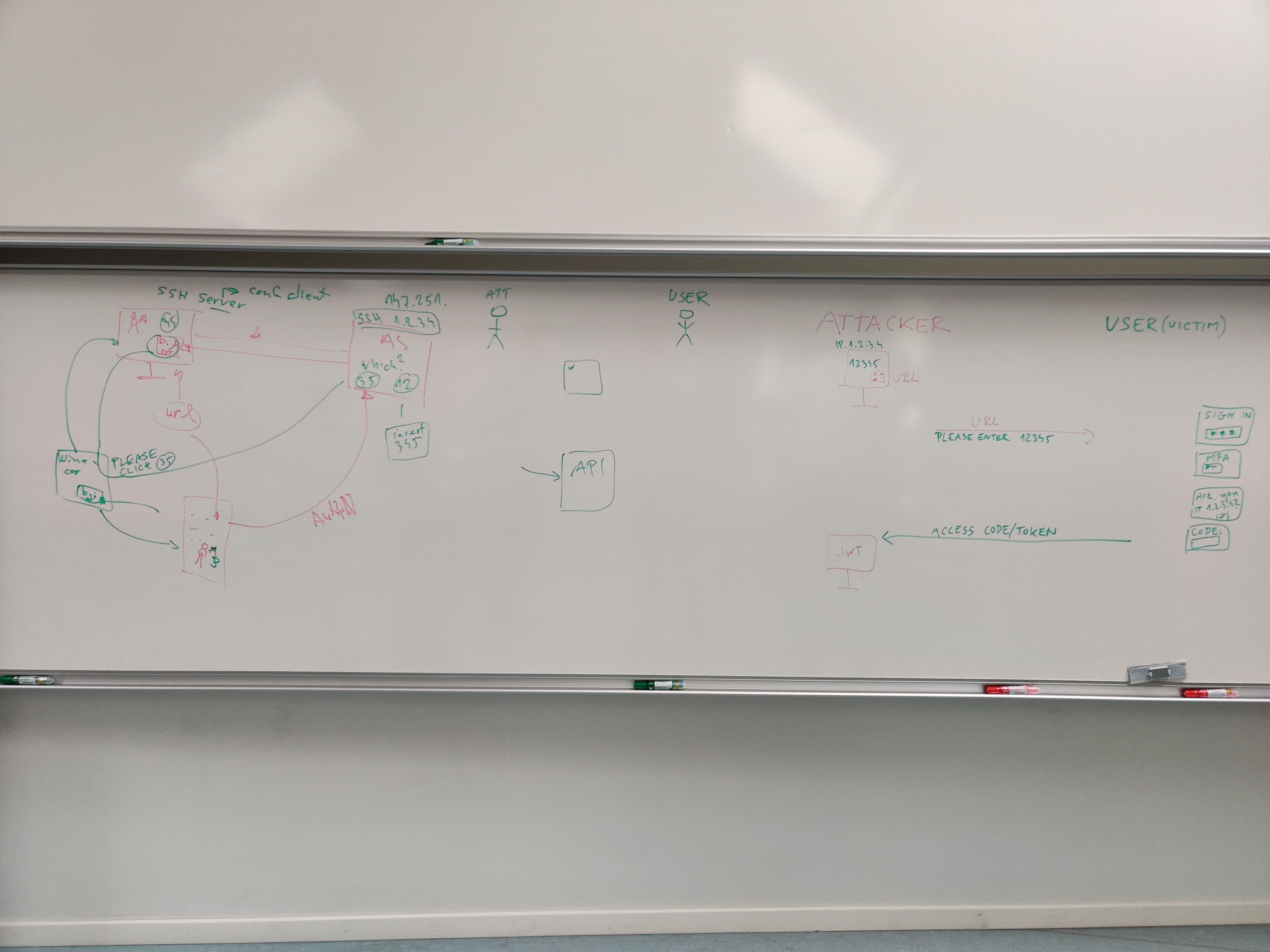{kind=link}
OpenID Federation for eduGAIN trust flow
Session Convener: Davide Vaghetti
Session Notes Taker(s): Phil Smart
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
- Trust in OID Fed is hierarchical and chained. Different to SAML.
- Can go end to end through the trust chain, from End Entity to Anchor
- SAML entities trust the public key of other entities in metadata and can trust the signature of the federation operator
- This is the same with eduGain. But the RP can not check the metadata came from eduGain. The eduGain signature is dropped and replaced by the federation operators signature
- Example. Users trying to access RP inCommon from another home organisation. The RP can inspect the metadata to see it came from eduGain. But there is no signature to explicitly validate it does
- In OID Fed. The entity statements are signed by each node in the trust chain. So you can check technical trust at any level
- Very similar to certificates (how the trust chain is built and presented)
- You can have different trust chains to have or show different levels of trust
- And you can use the policies
- OP can present different metadata based on policy constraints defined by the federation operator (PS. I think)
- What you advertise and what you get might be different
- It is not just trust, it is the metadata policies that can be applied at the trust anchor level e.g. algorithms, entity category (trust marks),
- Can be done with current federation pipelines, but that is not transparent
- In OID Fed, this is more transparent, and can be viewed from the metadata
- Is an entity published by eduGain, and if not, you might not know why.
- What is the hierachical trust model? (picture comming)
- eduGAIN as a trust anchor
- federations as intermediaries (can also be trust anchors)
- then the OP’s and RP’s as leafs
- the leafs can form any trust chain, the trust anchor can be the federation operator in some instances, and in others eduGAIN.
- The RP could choose which trust chain and hence which policy chain to use (possibly)
- The policy is applied (and combined) transitively from the anchor to the leaf
- The metadata is transferred peer to peer, but the trust and policy is determined via the chain
- Each entity publishes its own metadata at a well-known endpoint
- It will tell you where to fetch the next metadata in the chain
- The entity statement is like an x.509 certificate
- eduGAIN helps with (in the OID Fed model):
- Scale, managment (e.g. key managment — just need to trust eduGAIN), policy
- sirtfi is self asserted currently (but they comply to the policy, it is just not actively auditted). In an OID Fed it could be a trust mark?
- You can declare which entites are authorised to issue which trust marks
- Actions
- Collect feedback. Then feedback to PSE? activity
- What does eduGAIN look like in OID Federation
- Setup the trust model and define the technology profile and develop some tools
- It is not about taking SAML metadata and forming an OID Federation from it
- Setup the trust model and define the technology profile and develop some tools
- What does eduGAIN look like in OID Federation
- eduGAIN PoC. How do we keep track?
- Working on defining some drafts (kernel) with general architecture that should be a starting point. Published on the REFEDS list March time 2024.
- Collect feedback. Then feedback to PSE? activity
!!WARNING!!. ChatGPT summary:
Key Understandings:
- Hierarchical and Chained Trust in OID Federation: Unlike SAML, trust in OpenID (OID) Federation is hierarchical and chained. It can be traced end to end through the trust chain, from End Entity to Anchor.
- Trust Chain Verification: In OID Federation, entity statements are signed by each node in the trust chain. This allows for the verification of technical trust at any level, similar to how certificates operate.
- Metadata and Signatures: While SAML entities trust the public key of other entities in metadata and can trust the signature of the federation operator, eduGAIN signatures are dropped and replaced by the federation operator’s signature, making it less transparent.
- Different Trust Chains and Policies: OID Federation allows for different trust chains, showing various levels of trust, and the application of policies. Policies can be defined at the trust anchor level, influencing aspects like algorithms and entity category (trust marks).
- Transparent Metadata Policies: Unlike current federation pipelines, OID Federation provides transparency in metadata policies, making it visible and verifiable in the metadata.
- Hierarchical Trust Model: The hierarchical trust model involves eduGAIN as a trust anchor, federations as intermediaries (which can also be trust anchors), and OPs (OpenID Providers) and RPs (Relying Parties) as leafs. Different trust chains can exist, and policies are applied transitively from the anchor to the leaf.
- Metadata Publication and Retrieval: Each entity publishes its own metadata at a well-known endpoint, guiding where to fetch the next metadata in the chain. The entity statement is akin to an x.509 certificate.
- eduGAIN’s Role in OID Federation: eduGAIN contributes to scale, management, and policy enforcement in the OID Federation model. It aids in key management, and policies such as Sirtfi (Security Incident Response Trust Framework for Federated Identity) could potentially become trust marks.
Ongoing Work:
- eduGAIN PoC: The group is working on a Proof of Concept (PoC) to understand how eduGAIN fits into the OID Federation, and mechanisms to keep track of this integration.
- Draft Definition: The team is working on defining drafts with a general architecture that should serve as a starting point for OID Federation incorporating eduGAIN, with a target publication date on the REFEDS list in March 2024.
Browser mediated authentication flows
Session Convener: Zacharias Törnblom, Phil Smart
Session Notes Taker(s): Matthew Slowe
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Discussion notes
- https://github.com/fedidcg/FedCM/issues/240 “Allow IDP registration”
- Seamless Access is a thing of two parts… a place you search for IdPs and the mechanism for storing and handling persistence which uses a “Cross domain post message flow” to support IdP choice persistence across services
- Investigating how this persistence could be handled by a “browser wallet” of sorts rather than local storage and integrate that with information about the IdP discerned from the metadata with a view to supporting (and signalling the support of) Verifiable Credentials
- Google planning to remove “third party cookies” from Chrome which will apply to “looking into” iframes. Current trajectory is 1% of Chrome users are already seeing this behaviour but this can be overridden in the local browser configuration. Login processes not affected by Seamless Access discovery persistence will break.
- Cookies become “Chips” (https://developers.google.com/privacy-sandbox/3pcd/chips) which looks a bit like webauth…
- Allow developers to opt a cookie in to “partitioned” storage, with a separate cookie jar per top-level site.
- Chromium only at present
- This could become very complicated for users especially when traversing transparent proxies
- FedCM has “Bring your own IdP” [to return a signed JOT if the user is already logged in] via the browser API but is not typically useful; no SAML assertion is available. Other methods require the RP to pre-authorise which IdPs they’re happy to accept – but this doesn’t scale for us.
- Browser vs IdP may disagree on what the isLoggedIn() semantic means
- Apple assert they will not implement FedCM, so it will remain Chromium derivatives only
- FedCM will (might) merge into Google Wallet? It’s likely that the Wallet API will get wider support.
- Seamless Access could become a Web Wallet provider and use that as a persistence store
- It would seem more likely that a technology that Google intends to monetise (Wallet API) is more likely to last longer than other things and to be more flexible.
- FedCM intended to provide a “social” level of assurance but could initiate a SAML flow instead
- Q: how much of an overlap is there between the Wallet API and other approaches? Not a huge amount.
- Longer term we may need to construct a new form of credential which can kick off the authn flow we want
- Full page redirects will continue to work… isn’t that “nicer” for the user than needing to invoke a wallet for the user?
- Also of concern is browser “bounce tracking” protection which may impact the SAML or transparent DS flows. Unclear how to pre-seed the “allow” list for this. Verifiable Credentials need some work…!
federation topologies
Session Convener:
Session Notes Taker(s): Davide, Niels
Two terms are use in the OpenID Federation specification: Bilateral and Mutilateral
Q: Do you know what they are?
Federations are relationship systems.
The federation provides a way for the entities to learn about each others, so they can ultimately trust each other to interact.
The TA has a rol to ‘coordinate’ the relationship.
The technical relation between two entiteis is always bilateral. In a bilateral federation the organisational relation is also bilateral
In a multilateral federation the technical layer is still bilateral. However the organisational layer is shared between the participating enties
Use Cases for Managed Open Access
Session Convener: Peter Gietz, Jiri Pavlik
Session Notes Taker(s): Ben Oshrin
Already collected use cases:
- Time and geo embargoes, e.g.:
- licences content until 70 years until the death of an author
- time management governed by publisher licenses, then gets reissued
- national license allows OA only from within the country
- also dual use / embargoes against certain countries
- but physical location of accessor should not prevent access if otherwise eligible
- licences content until 70 years until the death of an author
- Control access while creating Open Access material (control who has access before publication)
- Infrastructure for discussing Open Access materials
- You want to know who you are discussing with
- Authorship of reviewers
- Reviews can be open access, but need to be authenticated by the authors
- There are many types of reviewer models in scholarly publishing: https://doi.org/10.1087/20150411
- Authenticity of the source
- Age restrictions, potential intersection with nationality
- Zero knowledge methodology, obWallets
- University specific contract exceptions (eg: university gets access to papers authored there)
- Aggregating rule management across multiple sources of attributes
- Switching from reader pays to publisher pays
- Research data requirements (vs Publication)
- How to handle access requests (workflows, technical processes, etc)
- See also “Supporting Open Science Through Attributes” REFEDS Workplan Proposal
- Finding a specific data point but then requesting access to associated data
- eg: I’m looking at blood pressure data, but now I need to know the related age data
- Data might need versioning
- Might be open access or not access
- Attribution
- Recording who accessed data / “google analytics” use case
- Publication author roles (paper and data): https://credit.niso.org/
- Data access metadata: https://ukdataservice.ac.uk/learning-hub/research-data-management/document-your-data/metadata/#
Two terms are use in the OpenID Federation specification: Bilateral and Mutilateral
Q: Do you know waht they are?
Biliater
Does the Proxy Need to Do All
Session Convener: David Groep
Session Notes Taker(s): Jens Jensen, Marcus Hardt
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
The proxy is the middle thing in the AARChitecture: SPs see it as an IdP, IdPs see it as an SP. They can translate protocols but not much goes through despite attempts like SNCTFI (= opaque proxy). It is the trusted component – ie mediates trust – though mainly in a hierarchical setup.
Bridge PKI could do a lot of funky stuff, though was hard to do in practice. Could OpenID Federation be useful? OIDC Fed does not cover discovery.
A dynamically created RP scenario, eg internal resources – could it be bridged into a federation environment without doing ∞ work? And without doing something hugely complicated
Split work into:
- Technical trust
- Policy trust
Use (trust) path discovery.
Mischa’s point that infrastructure proxy should not have state (ie session) but should be transparent, unlike the community proxy where the user has login/state.
Different types of proxies:
- Community AAI can’t really be transparent
- Infrastructure Proxy should be transparent (to the user)
- Otherwise infraproxies create new tokens, one looses track of the amount of tokens
The heavy lifting cannot be in the RPs, it might be offloaded to a validation service or be handled in a library.
Validation of RPs – if there are loads of them, it could put load on a validation service.
Transparent proxies validate tokens might cache validation – but do not reissue the token. RCauth translates the token (in MasterPortal) but with the same permissions. OCSP stapling
GA4GH embeds jwts into other jwts? “Burrito token” wrapping other tokens. Effectively reinventing SAML where multiple assertions are put together (with signatures).
Note that nested JWTs are in https://datatracker.ietf.org/doc/html/rfc7519
How would this work with revocation/refresh of the various tokens? Refresh tokens need to be used by the original client.
Compare the proxied introspection where a proxy OP calls out to the issuer – if we imagine we have implemented these as nested tokens. If this were to refresh, it could happen in the same order, provided the proxy OP has a refresh token for the OP’s token. In this scenario the equivalent of the proxy is the infrastructure proxy, and the OP is the community proxy.
Need to ask for more than a specific set of scopes. For comparison, a wallet can also issue its own assertions depending on what it thinks is needed.
One use case is academic learning where the home IdP needs to connect to the (equivalent of) the proxy to assert the user is an academic user (MyAcademicId). Tokens targeted for a specific audience though the transparent proxy.
ACTIONS
* Can we have wrapped tokens – would they work with any software?
* Comparing nested tokens with trust chains in OIDC Fed:
* What are the policy aspects arising from this?
Digital equivalent of certificate vaults
Session Convener: Victoriano Giralt
Session Notes Taker(s): Victoriano Giralt
The session was prompted by questions posed at the end of the day keynote plus a long standing concern in the Groningen Declaration Network meetings about preservation of digital versions of paper based academic credentials and certifications.
The conversation started around three topics:
- Refreshing the certificate both in the supporting technology (e.g.: from signed PDF to DLT backed assetion)
- Conversion from one format to another (e.g.: EDI to XML to JSON)
- Archiving as it is done with other digital objects like publications
The discussion of a central historic registry surfaced questions like:
- Which organisations could take care of such infrastructure (UNESCO came to mind)
- Should just one global instance exist
- Should it be a distributed infrastructure
Losing the issuer due to things like institutions closing, merging or splitting. If this happens, how can the autenticity of the certification be proven? This prompted the idea of using already existing technologies like the PKI public chains in order to prove that something existed at a given point in time.
These chains should be re-sealed from time to time with stronger algorithms.
ePassport ICAO.int
preservation business model
Verifability long term
“Outsourcing” terms
Reissuance
Refugees
Cryptographic updates
re-minting
“Phishing opportunity”
Who initiates?
Trusted third party
FIM UX-UI principles
Session Convener: Floris Fokkinga
Session Notes Taker(s): Marlies RikkenHighlights
- Seamless access has guidelines available and can help with their button and filter IdPs and an InCommon article about email
- Proxy chains confuse users
- We need to think from the user perspective instead of from the technical capabilities and obstacles
- It does cost time and effort to properly take UX into account. Takes away from technical budget
- A realistic challenge is how to deal with AUP
- High art to bring good user interface and security together.
- We’ll attempt to setup a REFEDS UX working group to share insights
Intro
What’s our experience with UX?
The main goal for our users is usually to log in. But we show them confusing terms and abbreviations before they can do what they came for.
Discovery service is sometimes much too hard to use.
Sometimes supports multiple federations. Sometimes identically named IdP’s. Which IdP the user picks can sometimes have impact on the access they get. Sometimes several login paths.
- What can we do as a community to improve this? What are the hurdles?
- Do steering committees, board peeps, understand the importance of the tools we make?
- How can we make sure people not forget the solutions we make?
- Which methods and models are out there?
Discussion
There is work done in seamless access (See resources). RA21 was forerunner
When we go through multiple proxies it is too complex. Especially when daisy chains are used. Confuses the user.
Should have more machine to machine comms rather than put the user inbetween sometimes. Try to hide IdPs that aren’t suitable. Sometimes self asserted.
Working group in REFEDS to check for signals of assurance level that IdP supports. Several other ways to filter IdPs to only those with which meets requirements to log in, could be possible on the short term.
We need to start thinking from the user perspective instead of from the technical capabilities and obstacles.
It does cost time and effort to properly take UX into account. Takes away from technical budget.
If it looks nice you can often get more funding, decisionmakers don’t understand the technical side.
How do we cooperate and re-use eachothers experience?
It can be hard to justify spending on UX. Also done by different people than the techies.
Developing new solutions should start from mockups, design and then discuss with tech. However, also need user input before.
Even start with wireframes before making it ‘too pretty’. Test with a small group and then already iterate. Validate with specific persona’s.
Multiple testers working on SeamlessAccess.
Also: use our own interfaces.
Some feedback is also found by talking to people while they use your service. Example; using the word ‘provide’ rather than ‘share’ since ‘share’ gives a feeling of ‘publishing’ to a facebook page, while ‘provide’ feels more professional.
Does UX sometimes conflict with values of NREN (what if UX result is ‘people think logging in with facebook is super easy’)?
A realistic challenge is how to deal with AUP (/ user policies).
Different groups will have different requirements. Sometimes decide not to implement things
High art to bring good user interface and security together. MFA is a typical example of this conflict. ‘please turn off, our users are annoyed’.
It’s not necessarily about the number of steps or clicks -> it should be done in the proper way. The action/transaction should be valuable.
Projects that (often) are about functionalities / features. Is it possible to also do specific UX projects.
There is sometimes room to do it -> project coming up to look at login flow for eduID nl in coming year. Would like to share outcomes, but unsure where.
REFEDS has a list of working groups to propose – could do a working group on UX specifically to share insights.
Rest of the world uses email as discovery. And tennant discovery.
OIDC Token Lifetime + Token Traceability
And token lifetimes in particular
Session Convener: David Crooks and Marcus Hardt
Session Notes Taker(s): Liam Atherton
Tags / links to resources / technology discussed, related to this session:
Slides with context and seeds for discussion: https://docs.google.com/presentation/d/18zzzec_FBBcHUM4gGKFpHTVXjeXFdEjWddJh0shCEQY/edit#slide=id.g2b50b6aecb3_0_12
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Context
- Many infrastructures transitioning to token-based workflows
- How do we achieve tracability across our workflows
- Where are authorisation points/what controls do we have
- Use cases for long lived tokens
- Balance security and ease of use
- For resiliance as token issuers mature, start issuing 4 day tokens so that if it breaks on a friday the token still works on monday
- an issue for security
What are the right controls?
WLCG context many sites had complete tracability on their network and didnt need to talk to anyone. Now we are in a modern world and need to work together
Discussion Notes
From a security perspective what best practices can we work on so that we can contribute to secure development for tokens?
- Token lifetimes for different token types, permenant tokens should not exist.
- Establish operating principles
Is token intraspection a showstoper?
- People are afraid that if the OP is down they wont be able to do anything and so want to be able to act independantly of the OP for days
- This cannot work in a secure way
In terms of revocation: keep your access token lifetime short and rely on a long life refresh token which can be revoked as needed
- The point here is having a balance between the access and lifespan
Temporary solutions tend to become permenant: 4 day tokens being used as a doorstop has a tendancy to become permenant as communities disengage when told that it is bad best practice and shouldnt be doing it.
Interoperability between different bodies e.g. wlcg/wpc
- Different requirements mean that there need to be distinct ways of operating, there are places that overlap is required as well
- If there is low risk access a longer life token would make more sense
- If you want read access to a document a long life token poses little risk
- being able to delete all data would need stronger requirements
- Generic best practices stop bubbles forming where one body ends up with policies that cannot work with others
Resiliance means that 4 day tokens have a reason for existing
- does not work long term
- If a low resiliance infrastructure is getting started and needs 4 day tokens at what point is this reviewed?
- security best practices should require high availability/high resisiance OP or short duration access tokens
- Making it impossible to do this the insecure way
What are the best practices in industry
- are google/apple/whoever doing this
- no
- a 4 day token allows a lot of time to do damage
Stopping repeat attacks is on service providers
- some rotate keys as best practice/some dont
- replay short lived tokens as keys havent been rotated
- This happened with ?outlook?
————–MARCUS ————-
Refresh tokens are bound to a client ID, do we have an idea of how long these should be used? should be rotated, do we have an idea of a lifetime?
- This is a pain everywhere
- we have all done something different
- One aproach is issuing 1 refresh token for 1 year. The other is issuing one every day (option 2 is more like a session token)
- is there a sensible way of adressing this
- This depends on how your service works, if its access for a session it shouldnt last a full year, similarly if its a yearly check that you still work somewhere it wouldnt make sense to be a daily refresh
- What is a reasonable session lifetime?
- you dont want a refresh token to be longer than the session lifetime
- What is a reasonable session lifetime?
————–MARCUS ————-
Outcomes
In terms of best practice there will be bubbles as not eveyone uses tokens the same way
From a security perpective we can create what options there are
Persure a policy based choice, similar to what we have done before, isnt always accepteble
Maybe the answer is using more standard tooling
Action Items/Next Steps
Look at specific examples
“we’ve had this conversation so now here’s what’s possible”
OIDC CLI and SSH with Federated Identities
Session Convener: Mischa Sallé, Marcus
Session Notes Taker(s):Liam Atherton, Nicolas
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Context
A few different ways to sign in
- Smart Shell
- Need a certificate
- Pam module
- Challenge to get package into distributions
- Moonshot
Discussion Notes
6 Community OS Solutions for Federating SSH: see slide 2 in https://indico.nikhef.nl/event/5118/contributions/20052/attachments/7832/10897/FederatingSSH-NCW2023.pdf
Are there ways to merge some of the solutions?
- These solutions coexist
- good to have multiple solutions
- should also learn from each other
- Would it make sense to review each others code and security mistakes
- High Impact of failure
- full code review takes a lot of time
- could be good to look at architecture to make sure there are no loopholes
- Everyone has the same issues of (e.g. how do you onboard, how do you manage keys)
Something missing from the table: how good are these solutions from a user perspective?
The white paper was intended to cover this but nobody had time to write it
How are the different solutions working:
Marcus KIT – started with having an oidc agent on a users laptop
placed access token into password field
Give identity to the server
Daemon on server side to do ssh call
Users can just use ssh with certificates
stored in the SSH agent
Also have a webshell client – log into webpage: https://ssh-oidc-web.vm.fedcloud.eu/
David DAASI – we do smart shell
you ssh to a remote server
this launches a web server and does the OIDC workflow from there
User opens a browser and logs in from there
Token never leaves the remote server
you can get all the information you need from the token
Has been tested for breaking out of the smart shell
DEIC – Requested by HPC in Denmark
Don’t need anything on the client or server (excluding some hppd config on the server)
you can put a “principles file”
lets you map principles to usernames
Time limit – review your certificate based on policy
small bash function starting on the command line
Jens UKRI – Pam module
Cloud options built in
no changes required on the client side
you go to a url and authenticate there
some simple authN controls in the module
can get attributes from an LDAP server
CESNET – Pam module
SURF – developer in a different session
Inspired by KIT solution
Aiming to make it as simple as possible for the user
click button on web client
Opens ssh client with url and qr code
already authenticated in client
——–Diagram to illustrate the flow—————
All of the solutions developers are on this mailinglist:
Client Tools
- Users shouldn’t even know that they are using tokens
- not intended for end users
- Don’t care about technical details
- Existing solutions:
Is there collaboration between the tools?
Idea for OIDC agent is to be indistinguishable from previous versions from the user perspective
Next Steps
Expand table
- STFC to fill out column on table
- Add czech solution
- United States version missing?
- New rows
- Maybe share features
Worth still writing the white paper
How to propel all those valuable attributes we have to kick start digital credential usage
Session Convener: Peter Leijnse
Session Notes Taker(s): Marlies Rikken, Michiel de Jong
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Intro to discussion
As international community we have alot of information in our federations and processes. Let’s assume we have a ”working credential ecosystem” and we have to provide our data to our community in a different form. What are the shortest paths to do this?
The reasoning is that business processes exist and won’t change on the short term. Some IDattributes and Credentials/rich attributes are needed (eduperson eo diploma credentials). SAML/VC = Same content different package.
How can we combine and create meaningful and valuable credentials. Affiliation, roles, etc. are components.
How can we improve our processes, cheapers etc.?
Discussion
Good starting point: define basic affiliation credential. Something that looks like a VC version of the eduperson schema.
There is a lot that is only there because we need workarounds
As a first activity, sit down with the .. person, what are the attributes you need in a student card that you put in a wallet
And then we need to give them the technical infastructure
Why are the attributes different ?
Sometimes the scope is not the same as the home institution
It sounds like almost a cleanup operation
Produce a bag of attributes that fits the use case
Institutional email address(es), display name, affilliation(s)
RNS credentials encoded as an SD-JWT
The European student card could be a lower-hanging fruit. Put an ESI in there
They will be sourced from more or less the same system
Business process rules
In the ESI case, is the ESI typically present in the same place as the eduperson attributes?
Probably yes, at least in Erasmus-without-paper.
An identity store with bridges to the other apps.
RNS+ESI
Spec that out and have it blessed
Simply put the SAML assertion in a different transport
The implementation might look a little bit different
In the issuance process the wallet talks to the issuer
It’s close to the SAML attribute release process, but not exactly the same.
If you had an SP that was simultaneously authorized … crank out the SD-JWT and put it in a wallet
We probably have that code
But how would we arrange the trust? -> stick it in edugain
But ideally you would like the original IDP to sign the VC?
We need to contemplate what sort of trust mark would be required to decorate that kind of information
maybe proof the provenance but not necessarily signing
It may be convenient to have some sort of delegation, decoupling the trust from the people who run the endpoints
The other thing we need to consider: what are the release policies that the wallet needs to have
and do the verifiers need to be part of a federation
how do ensure that the wallet enforces the right release policies, based on the verifier’s metadata?
use selective disclosure for student discount at webshops, for instance
how do we build the trust infrastructures for this?
there are proposals on the table, like openid oauth scope
another thing to keep in mind: when deciding schema, we should keep in mind that there are other parts of the world where the existing schemas don’t work so well, you may have your name in two different scripts for instance, for different purposes. let’s have dialog with other people who have these problems. Regional, cultural things, we need to make sure we’re including them.
If you were to make a shopping list,
[SHAC-VC ?], [SHAC ?] schema work
worry that this turns out to be too EU-focused
we can start with something that works for Europe, which already has quite a bit of cultural variation
It doesn’t hurt to have discussion with other folks while we’re doing it, bring them in as soon as possible
This is Work Package 5 of DC4EU, they are focused on EDSI. It doesn’t even enter into this problem. Someone could write something up and feed it to them.
nobody wants to be a part of the schema working group, but it’s important
try to do a minimum viable thing
it may be worthwhile to include the US, a lot of people there have a lot of interest in schema.
we have to start the work with both US and Japan around the table. Refeds wouyld be a good place for something like this.
Who is going to start the working group?
maybe someone already tried to do this? not refeds 4 vc governance, that’s different
let’s talk to Heather [Heather, are you reading this? ;)] No but Nicole is 🙂
I know she’s trying to get somebody to start that
There’s an agenda where people are proposing working groups through refeds
Right now is the right time to propose something
You write a short thing, people +1 it, and it ends up in the commission https://wiki.refeds.org/display/WOR/2024+Work+Plan+Preparation
Commitment from Leif Johanssen to get people in his team to do this
For the wallet space most of it is from one of the universities, I’m trying to remember which
Peter: If it’s done it’s done
* We have a reference working group that needs to happen -> Leif to submit the proposal?
* chair it -> Victoriano + a co-chair
* Get people into it -> several people in the room
* Coordinate with Japan -> Laura Paglione
Who in this room wants to run the working group?
Victoriano is volunteered
he says OK, if there is a co-chair
— end of session at 11:10 —
Short talk with Heather after the session:
This is work under Schema editorial board. Discuss with Ben who is also here.
addition from the European Higher Education Interoperability workgroep (EHEI): several European University Alliances are already deriving credential schemes based on REFEDS
Trust Mark Use Patterns (OpenID Federations)
Session Convener: Vladimir Dzhuvinov
Session Notes Taker(s): Davide Vaghetti
Tags / links to resources / technology discussed, related to this session:
https://openid.net/specs/openid-federation-1_0.html
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Why trustmarks?
In a federation you have members, metadata and trustmarks. The reason for having trustmarks is that we should not inflate too many information in the metadata about the entity because there are information that shouldn’t be in the metadata or couldn’t be there. Moreover trustmarks are often related to a specification, or a verification process about the running entity, that they comply with something.
Another example: how could I know if an entity is still part of a federation __immediately__, and using the trustmark endpoint you can ask if the trustmark asserting federation membership is still valid or not.
Q: Can trustmarks have more than one issuer?
A: No.
Q: What happens if the same TM can be issued by different issuers?
A: Just check the issuer to distinguish them.
Q: What about self-asserted specificaiton that can be modeled through TM, is there a way to design policies around that?
A: TM.
Q: What if the TA and the INT do not want to provide metadata, just trust. Is it possibile to use TM to assert metadata?
A: It could, but never thought about that scenario. In principle TM shouldn’t be used to convey information, just attestations. TM for example could be used to specify the domain.
Q: Is that possible to use TM as part of the metadata filtering policies?
A: Yes of course, that’s entirely possible.
Q: Entity statements are JWT, TM are also JWT, in case when the TM is long-lived can’t we use a ref URL instead of transmitting the TM at every request? Why couldn’t you use the TM id instead and let the RP decides if the want to check it or not (async)?
A: The TM status endpoint already return a boolean that might be used or extended in such a use case. Anyway, that would add complexity.
TM has been designed to be very simple and carrying the least possible information. TMs are optionally extendable, but that’s probably limited to specific use cases.
Q: Use cases for sending information along with TM?
A: For example to put logos or QRCODE, or Digital Badges. In offline scenarios logos representing the TM will be very important (as well as other information).
Q: Is there a way to model registration process and policies in the OpenID Fed metadata?
A: Not really, what you can apply are filters based on your federation policy.
Transactional Identity – Keep GUIDs hidden
Session Convener: Michiel de Jong
Session Notes Taker(s): Peter Havekes
Michiel presented https://github.com/michielbdejong/presentations/blob/33f735408b13add9abb06f0cc62b9cf5eebc2b21/transactional-identity.pdf
Intro: Don’t give out the actual GUID. A from of selective disclosure/ derived personas for different roles/pseudonym. The goal needs to be preserve privacy, but still authenticate the user. When to use Global Identifiers? eg. Per Person Rights and Obligations, or legacy systems.
Discussion:
Transactional IDs are better in terms of security.
In SAML, there is a pairwise ID to solve this, originated in libraries to recognize users, but not be able to correlate this across systems.
Ivan: Do not confuse identity with authorization. The underlying problem is where the data ends up and what can be done when the data is being combined among systems. Wallets might improve this if policies will require this. Systems won’t change by themselves; they like the data.
The Dutch eduID system uses a targeted GUID per institution, but this causes issues when users need to be pre-provisioned to systems, because the GUID is not pre-known to the RP.
Can a wallet generate derived identifiers? If there is a (government-issued?) base identifier, new identifiers can be generated based upon them, even in different personas. But still, the RP can’t know who the user is (authorization).
Linking accounts on first login could be a solution. Just like linking different social accounts to a service. The user links the existing identifier in a system to his pseudonym on the first login.
Scientists want a global identifier (ORCID) to have their work recognized; that’s the opposite of the privacy methods suggested here. The unique persona required here can’t be combined with an pr\ivacy preserving identifier.
In Solid, the profile was designed to be a globally unique URLto be easily found. That ts now causing troubles, for maintaining and privacy. Some wallets tried to use solid as an example, but stumbled upon privacy issues.
Also in student mobility usecases, a unique identifier could be needed. But a transactional identifier (for this context) could solve this. Even an oAuth token could be a transactional token in this usecase.
Conclusion:
We should make sure the ‘new’ wallets do not weaken the current options for hiding global identifiers.
Web Wallet + ORCID + SeamlessAccess
Session Convener: Leif Johansson, Laura Paglione
Session Notes Taker(s): Mary McKee
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Intros
- Laura Paglione, founding technical director of ORCID
- What’s impact to ORCID of wallets and decentralized identity
- ORCID Board wants company to be more active in this space
- Connected with Leif on this topic
- ORCID tracks identifiers and also associations like publications, grants, etc.
Pilot Idea
- Neils web wallet demo (yeterday’s session) as a starting point
- Try to identify base attributes (eduPerson – ePPN, email, name, affiliation)
- Web wallet
- Add eduPerson card
- Add ORCID iD card
- OIDC Federation
- What would this be used for?
- Trick would be getting a publisher to actually become a verifier
- This would look like an OpenID for VCI credential, would that combination of credentials be useful, if user came with no additional credentials?
Discussion
- Lots of open questions (who would sign? Probably eduGAIN, at least for pilot)
- ORCID has a back end that could be queried to get attributes
- For flow to work, doesn’t there need to be an agreement between parties?
- Technically speaking, there’s client registration
- ORCID is open
- Is all of the information that the verifier needs available up front (for verifiable credential), is refreshable access required (this is a different thing)?
- Could be a status attestation
- Doubt that this is needed if the use case is the foundation for applying for a grant; ORCID iD not intended to change, so maybe verifiable credential is sufficient.
- If I am a verifier and I have access to ORCID API, is there an authorization step required?
- Depends on what the publisher wants and the user allows
- User doesn’t have to grant
- There is a public API and a member API
- There is a use case for just writing the ORCID iD; for example use for gaining access to resources, bootstrapping account based on ORCID record.
- A verifiable credential, therefore, would be good for accessing the API and doing account-based login. That doesn’t replace the OAuth authorization compoent in other use cases.
- Is there anything missing from proposal to make this useful? Who would actually use this? Would you? Or would you need more to make it useful?
- Sounds like some people do an OIDC flow back to ORCID for access to resources, so – that
- In the simplest use case, the ORCID verifiable credential could be useful for actually managing your ORCID account. Do you have unphishable MFA for ORCID (already)?
- ORCID currently uses MFA for TOTP, but could use this kind of verifiable credential to add security to the ORCID account.
- Would this not simply be another transport mechanism for the same information that is already available?
- They still need to implement the API – this is debated
- There is no inherent linkage between two credentials (eduPerson and ORCID), even if they are in the same wallet (you can’t tell that)
- Discussion about linkage between ePPN and ORCID iD (which would create necessity to refresh data, as ePPN may change), but in this case, ORCID doesn’t store ePPN.
- How do you refresh?
- Could you link the ORCID iD credential with a different (or multiple) eduPerson card, in the case of changing or multiple organizational affiliations?
- You can prove freshness of eduPerson through status attestations
- If you can prove that eduPerson card and ORCID card are part of the same wallet…
- This is an advanced concept, syntactically complex
- Technically there is ability to request multiple credentials at once
- Major industry players believe that you can only request one credential at a time due to privacy concerns
- Leif: If I’m the wallet solution provider, could imagine creating virtual credentials
- Does the wallet have an identifier?
- Verifier A doesn’t know what the wallet is and doesn’t know that the two credentials came from it
- If I ask for an ORCID credential and a bunch of ePPN credentials from various institutions, it’s highly likely they’d all be fulfilled by the same person by the same wallet, but you can’t know that definitively.
- Is it important to know that if you know it’s the same device?
- It is if you want to ensure that there is not an adversary in the equation
- Is there a way at the time that you are getting a credential that it can be queried for an ORCID credential?
- You could log in with one credential and request another credential and then generate a hybrid credential
- You would treat these as ephemeral credentials
- The question of multiple credentials seems like a sneaky point to pursue – maybe one of the most important ones since we are looking at a core use case of combining institutional identity with governmental identity
- More hybrid credential discussion
- Many needs to bind things together, very manual/laborious now
- We need to build logic into query lanaguage of verifier or we need to have verifiable credential providers who aggregate credentials
- The web page of the RP would have to instatiate the API to request the credential
- Android for example, you can create a web assembly as a wallet provider with all the credentials the wallet knows about, goes into a sandbox that provider can execute on in order to construct dropdown menu in OS
- who produces that assembly? the wallet. To query itself? No, the assembly creates the UX for the user to decide which wallet is involved.
- could there be a mechanism there for user to select multiple?
- this is why the query language between verifier and wallet selector is so important
- is that within our control? maybe, but the OS must be able to parse and understand it, OSes all imposing restrictions to prevent misbehavior and see what RPs are asking for
- In discussion with Google, Apple, Microsoft, and Mozilla, a lot of what can and can’t be done will be sorted out in the web incubator community group at the W3C
- Aren’t we still talking about presentation?
- This is one way of doing it, we could also solve it in the issuing part via proxies
- It’s a question of what the verifiers will be able to ask for
- It sounds like we actually should go make our case for a bit more complexity with W3C work group
- Documenting use case about verifiable presentation with multiple VCs would help in convincing companies
- Is there a github issue? Yes, web credentials subgroup of the web incubator community group (WICG)
- This is not two types of government ID, these are two IDs that have value as a combined set.
- how do we do this today? we have people authenticate themselves twice to the same session. This is much better
- binding all of the verifiable credentials by being in the same wallet owned by the same person is not flawless security but it is relatively much better than alternatives
- How to bring to WICG
- We know that these use cases are standard, but that CG may not understand
- LIGO may have this use case, Life Science, ask Slavek at Evolveum?
- Laura could speak with ORCID
- NIH
- Aren’t VCs supposed to be usable for electronically signatures? This is PID/a european thing
- Specs vs. how people choose to implement the specs
- Confusion that if we were always going to have multiple wallets but we can’t respond to requests from multiple wallets
- Multiple instances on phone would see request, OS generates pick list to let user decide, then request only goes to one wallet
- Attribute query languages are not a new problem or necessarily even an unsolved problem
- Confusion that if we were always going to have multiple wallets but we can’t respond to requests from multiple wallets
- How do we digitally check that a specific verifiable credential is actually owned by someone?
- If you can’t do multiple credentials in one interaction, you have to ask twice
- In this pilot, asking twice is “reasonably okay” with status attestations for eduPerson card
- If the two requests came in a short period of time, you accept it’s probably the same person
- What about other cases where assurance is more important, like EHIC? Do you have to look at the passport as well?
- EHIC could be an issue to bring to the WICG sub-group
- Statement: if someone has a verifiable credential, is it possible it doesn’t belong to them?
- Issuer authenticates user before issuance, has to trust that that party is going to do the right thing
- There’s nothing that says that that person couldn’t get a credential for someone else in another wallet etc
- It’s the same with any federation, the issuer’s willingness to issue implies due diligence
- ORCID – if they are presenting to system, they own that credential, but how to revoke?
Next Steps
- Looking to speak to use cases with WICG sub-group: https://github.com/WICG/digital-credentials
- 1 or 2 individuals
- Someone from NIH and someone from Europe would be ideal
Cybersecurity Regulation (NIS2, CRA, …)
Session Convener: Radovan Semancik
Session Notes Taker(s): Daniël G
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
(Note: I’m used to taking notes in prose in my own wording, not verbatim quotes.)
Lots of regulations coming in the next few years. Big impact expected, also in open source development.
NIS2 comes into effect this year, expected 18th October. Demands to run cybersecurity cycles to many fields, more than NIS1. For some also obligatory audits, sometimes only after an incident.
Another relevant regulation: Cyber Resilience Act (CRA). Makes software vendor responsible for software defects. Also applies to open source. Amendments were made to its draft to make it less harmful to open source vendors and SME’s. Complicated if for example you are using software from non-EU vendors: you can become an importer, and thus liable. There is already talk about an updated version, CRA2.
The CRA also uses a lot of vague language and handwaving, so it’s not clear yet what it will mean in practice. For example, what is “commercial activity” exactly in the context of open source vendors? (Something similar happened with GDPR.)
Many of our software products use a lot of open source components, sometimes over a hundred. Remember the LOG4J scramble to figure out which product integrated the vulnerable component.
For now, single-person open source developers will probably be safe; they are not the primary “target”. But we are larger institutes and organisations, we will fall under scrutiny.
Do we want to be regarded as “critical” digital infrastructure?
Are we liable to a user misconfiguring our software? No, probably not. Also if the product has bad defaults? Those probably do count.
Important: it’s not that we guarantee that our software is bugfree, but that we have a good process for responding to (security) bugs. A codebase thus needs constant attention, and a lot of software packages are not doing that.
It’s possible that you can be classified due to your users (number, size, …).
Is the NIS2/CRA compliance mandatory? NIS2 maybe not, but CRA yes (for European parties). The goal is to make European citizens more safe. But a lot of our work is not geographically bound.
The fines can be quite high (up to 25 million euro’s), and this would be a big problem for us. Some big commercial companies might be able to survive this, but scientific budgets don’t have room for this. Do we need to arrange for more funding to improve compliance?
Idea: Go through your dependencies and remove those that you don’t need, and even rewrite some parts of your software to remove them. Also try to rely on dependencies that are more reliable (large team instead of a single developer, for example).
There are some organisations that are working on helping with this, but they seem to focus on small grants for now, not assuming liability. And it’s not only about money; there’s a lack of cyber security personnel, such as auditors.
There are things we can do now. Provde some guidance for improving compliance, legal advice. Implement risk assessment, do code audits. Still not going to help the single developer much (if you already don’t have enough time to maintain your code, you are not going to be able to do code audits either).
Perhaps “damage control” is a better approach: *if* you get fined, try to be in a place where the fine is as low as possible. Implement what you can, and hope for the best. It’s not perfect, but it may be the best we can do (for now).
Timeline: in 3 or 4 years CRA will probably take effect. NIS2 is sooner, but less impact on software development.
Three roles: manufacturer, importer, distributer. Someone will always be liable.
In the CRA, internally used products are not seen as “commercial activity”, so that may be fine.
Both the NIS2 and CRA need to be implement in law by the EU countries, and some are behind on schedule (for NIS2). Those laws are the ones to be followed, and most aren’t drafted yet.
Commons Conservancy: https://commonsconservancy.org/. Possible home for support.
A good thing about this is: we have to cooperate on this, and more cooperation is a good thing. Additionally, it will become more attractive to be an open source developer. This may attract more developers to software development, perhaps?
Federated security exercise
Session Conveners: Davide & Tom
Session Notes Taker(s): Vladimir Dzhuvinov
How to communicate security risks, events and incidents between organisations?
How to coordinate the security teams and the identity teams in organisations and between organisations?
In INCOMMON everybody is expected to achieve certification status, but sometimes the person who does that leaves its function and the knowledge gets lost. What to do?
We want to encourage broader, internatinal participation, across certifications.
What role should EduGAIN play in the event of security incidents?
Compromised IdP credentials – what to do in that case?
Estimates and stats show that 1% of auth events in R&E are happening with Service Providers outside your federation.
IdPs can have 100 thousands to millions of auth events on a monthly basis.
The “Federated Incidents Response Handbook” effort is mentioned.
What was the biggest incidents? 40 countries and around 400 institutions involved.
What are the best practices – needs involvement of the community.
Most institutions that have suffered incidents want to preserve their reputation and do not ask for help.
Participant: Email security contact of entity category holders once a year, usually in autumn, and if they don’t respond within 48 hours the cert is removed. Sometimes the response comes from an automated ticketing system – how to account such responses.
Participant: Similar effort produces response rates in the 80%.
Participant: Some security contacts are personal email addresses.
Participant: The presence of communication infrastructure is a key enabler.
Participant: Some people don’t trust emails.
Survey: How many people here are into operations?
Question: How is your relationship with the security folks in your org?
Answer: Mostly good.
Question: Fished accounts / credentials – how much of this is channeled into a process?
Participant: Security of CA, corporate side and IdP can be “balloons” that bounce off one another 🙂 The formal stuff is not always there.
Participant: Personal connections often help when the formal channels are lacking.
Participant: Can you explain the role playing game for security incident responses and how it is organised?
Participant: How many orgs participate?
Participant: At least 50 people take part.
Participant: The event is like a complete simulation and takes a lot of preparation.
Participant: Transits is a very basic security training, 4 – 5 aspects. Normally face to face and twice a year in Europe. Face to face may not feasible for large events with many people.
Participant: EduGAIN should probably talk with Certs. Federation people and security know each other, but communication may be improved.
Participant: Things could be more explicit.
Participant: Federated identity – shared ticket system for incidents and a chat with federated participants. The metadata is sometimes used to get contacts.
Participant: 20 – 25 orgs in our federation got hacked last year (2023), but the situation seems to be improving.
Participant: When you have incident with a compromised credential you MUST (under cert) contact all services that may be affected. Graph drawn of IdP with 3 SPs. Example of simple fishing.
Participant: How much of the response can be automated, including the notifications to the external parties.
Participant: Is there a timit limit for notifications in Certify: Response: It must be done in a “TIMELY” manner. But all those things must be subordinate to your local policies.
Participant: What is TLP? Traffic Light Protocol. Specifies with whom you can share information. Green: Public, Yellow: On a need to know, Red: Share F2F.
Participant: Noise should be avoided, is not useful.
Participant: We are aware of the SET (Security Event Token) RFC. However, it seems to require significant investment, the bar is high.
Participant: The SET was designed for comms between a dozen parties, not thousands.
Participant: Is the response at the SP in the case of a compromised account in the handbook?
Participant: Did we have a proxy operator participant at the table top exercise?
Participant: How can we get involved in the table top? There will be a call.
AAI & SKA: managing identity for a new infrastructure / community
Session Convener: Ian Collier, Jens Jensen, Tom Dack
Session Notes Taker(s): Liam Atherton
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Context
SKA is a radio astronomy experement, dishes in australia/antennas in south africa
100s of petabytes a year once built/ global computing
all countries that contributed to the building of SKA also proportianlly contribute to computing
research groups using the resources are small – some way that resources are allocated/delegated
Every regional centre has
Its services
an IdP
a proxy
Complete set of centrally managed attributes in an atribute authority
Discussion Notes
Are services specific to regional centres/ska or external
- a mix of both
- assumptions made for how attributes and tokens work in the proxies
- the vision is that the AA controlls the attributes but the full list is duplicated to the proxies
- AA is tied to the resource allocation
- researchers likely to be working on this for a long time
- onboarded with an ID and as a member
- Access to roles and data
- more or less transient groups
- researchers likely to be working on this for a long time
WLCG has large VO’s and those negotiate for resources and then internally for how that is distributed. The suggestion here is that the SRC framework has to support the internal processes
One of the ways this would work is that some of the proxies would be existing services, canada astronomy given as an example.
- at STFC storage and cloud will be run the same way as everything else, just with virtual endpoints.
- some places may just create quotas on teh same infrastructure
- The AA in the diagram is a community AA, the proxies are close to the infrastructure
Is the federation of federations truly that or just one federation?
- If SP1 and SP2 are logically connected to the same proxy then it is one federation
- Proxy 1 is an SRC proxy and can contain other community proxies below it
- Proxy 1 and 2 should be considered the same community
Users may access different resource centers, is there any notion of data federation being applied to all the data being created by SKA?
- yes it is part of the model that the data is part of a federated whole
- until now the approach to data management is that moving data is expencive and difficult so it wont be done
- this is probably based on outdated ideas
- something similar will happen here as to happened in WLCG
- data should move more as SKA matures
- The size of data sets needed for computational jobs will create issues with using cashed data
Its good to think in terms of trust
- it isnt very clear right now how trust works
if we find a situation that doesnt work on the BPA is it an issue of simplifying the given model or is the bpa incomplete
- WLCG model is similar
- resorces are shared by a buch of VOs
What is the intention of having the central AA where it is. Why is the information at the AA and not at the proxy.
- because its managed at the AA and delegated at the proxy
- One trust domain
- you can have many managers that have access to manage the parts of the AA they need to manage
There are potentially different ways an SRC can be set up. Many proxies/one proxy/hiararchy of proxies
How can you be sure the service you are using and the user trying to access it is going to be that specific role.
Why would you proxy user info? you should just send an access token
Next Steps
How might one actually implement the attribute authority? Are there existing tools or do we have to develop new tools? The only things needed are the data and a UI, if you are doing user management there you need a portal. Set up some requirements.
Seamless Trust Info Metadata
Session Convener: Björn
Session Notes Taker(s): jocar
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
Working group in REFEDS coming up on this matter
SeamlessAccess is a discovery service for SAML. There are a few federations feeds going in to SA (SWAMID, Incommon, OpenAthens eg.) Some users/SPs wants to be able to filter the list of IdPs.
There are diffrent ways to filter the feed based on the information in the metadata. An SP should be able to tell SA about which entitites can be used. E.g by selection info, entityID or a mix of them.
Filtred enttites could either be down priortized or completly removed
This filter is no “real protection” for SP.
Q: Will this make Seamless smarter to try to help the user finding the correct IdP
A: No not really
Q: Will it be clear to the enduser whom to contact if question appears? Eg. if all entitites are filtred out
A: There is a URL that could be published from the SP to SA for help user find the support for the SP. Like a fallback DS service. In addition with an ErrorURL you should be in a good place.
Seamless remembers the last used entititis in the browser.
Adding the ability to add some file in .well-known in addtion to adding the filtering data to the metadata would be good and useful.
It’s code is probably already available in the beta service for SA: https://use.thiss.io/ds otherwise contact zacharias@sunet.se
Probably possible to add additional feeds to the beta service if someone want to play with a local feed.
Stack uses: thiss.js, thiss-mdq, pyff (v2.1.1 or later)
Support for regexp are not inplace but could be added in the future if some could argue about a good reason.
Specification of the protocol: https://docs.google.com/document/d/1mJ9n-JnuAkQWdn1Efs_FHJyEMeiFWalRsazEWvn8DLU
How to fully decentralize educational credentials and data
Session Convener: Niels van Dijk
Session Notes Taker(s): Peter Havekes and others
Introduction: If the wallets-thing actually becomes a succes, we can not store all data in the wallet. eg. a complete thesis won’t fit. Could Data Pods be used to overcome this?
A possible solution is to use a centralised IdP (e.g. eduID) and generate a persistent identifier (derived from a government issued ID for recovery) in that. The centralised IdP can issue information to a wallet. A data pod (hosted anywhere) can hold encrypted data blobs. The Sovereign ecosystem allows parties to request access to specific content. The user can allow access to this data-blob, typically by using a website.
Could this also be solved by signing/encrypting the data and sending it, instead of storing it on a pod? The idea is the data pod is under control of the user, and long lived.
When an institution is in play, a user could request the institution to store his data on his own data pods.
Several solutions for data-pod-storage already seem to exist:
- In Danmark an e-box has been created by the government as a shared data pod, allowing users to send and request data.
- Atumni created a Flemisch data pod that’s already being used in educational usecases.
- Could using IPFS solve this, by just sending data in chunks to any filesystem.
- OpenScience’s DeSci Labs also has several solutions for decentralised data storage.
- DeSci Nodes – comparable research objects
- DeSci Tools: noob- transferable and revocable, on- chain attestation of social affiliations, commitments, and credentials
- DPIDs – persistent IDs for machine accountability (protect artifact and citation fragmentation)
- Also see OpSci (https://www.opsci.xyz) – seeding a flourishing decentralized science (DeSci) commons to enable research collaboration between independents and traditional institutions.
What could be the function of the wallet in these use cases? Is it for the recovery of access to the data pod, generating encryption keys, or data recovery?
Releasing data from a Solid Pod using ACL requires knowledge of the data structure.
So data pods already exist in various forms. Is there a need for integration with the wallet ecosystem? This would necessitate highly structured data, of which the wallet requires information. It could be possible to generate keys for accessing specific data for specific persons just in time. This is already done in web-based systems (without the wallet).
The data pod could also be an issuer, issuing a credential to your wallet, allowing it to be shared to the receiver. And the pod could also consume the credential to import data from remote pods.
Authorization (is this a thing) and How to request specific claim values in JWT Access Tokens
Session Convener: Heather Flanagan, Nicolas
Session Notes Taker(s):
Tags / links to resources / technology discussed, related to this session:
https://datatracker.ietf.org/doc/html/rfc9068
https://github.com/WLCG-AuthZ-WG/common-jwt-profile/blob/master/profile.md
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
– GUT Token discussion related to authZ
– Related to Authz:
– Open Policy Agent
– AuthZen
There are several different solutions for policy/access control which are application-specific –> issue for interoperability
AuthN has been solved –> AuthZ next big thing
Capability-based vs projectbased AuthZ. Need model for a common vocabulary
Ongoing discussion in wallet space on “Base identity”, “Sectorial identity”
ELM – European Learning Model working on stadardisation of attributes
Proxied/Remote Token Introspection (Nicolas explains AARC-G052)
Actions:
Reach out to OAuth WG chairs to consider AARC-G052 for standardisation and discuss in oauth security in Rome https://oauth.secworkshop.events/osw2024 (deadline Feb 11)
3 areas in AARC:
– Proxied introspection (AARC-G052)
– Scaling trust between ASs (AARC-G058)
– Same language GUT Token Profile
Meetings to discuss these topics are held Mondays 14:00 (CET) and announced in this mailinglist https://lists.geant.org/sympa/subscribe/aarc-architecture
“xyz structured scopes” (bank transactions) might help
Michiel demo’d https://github.com/pondersource/surf-token-based-access/tree/ab5b504b3c239343b9dccf70fa403ba69113fae7/phase-2/poc on screen
Federation Topologies II
Session Convener: Vladimir D.
Session Notes Taker(s): Davide Vaghetti
Tags / links to resources / technology discussed, related to this session:
Discussion notes, key understandings, outstanding questions, observations, and, if
appropriate to this discussion: action items, next steps:
TA = Trust Anchor
INT = Intermediate Entities
TM = Trust Marks
LE = LEAF
VO = Virtual Organisation
A topology for eduGAIN participants could be modeled with a federation TA, that is a sub of eduGAIN TA, and two INT: one for entities available in eduGAIN, one for entities local to the federation.
Another topology for eduGAIN participants could be modeled in the same way, but with just one INT and TM for the eduGAIN enabled entities.
TMs can also be used to convey exclude lists for entities with which an entity would not like to talk to.
BUT: TMs add processing and it would be better to use TM (and metadata) to assert policies not to deny stuff.
An eduGAIN TM could be self-asserted to let LEs to declare if they want to be available in eduGAIN.
VOs can be modeled as independent federations.
In complex scenarios there might be issues in metadata merging due to conflicting filtering policies. Different positions:
– this is not an issue, “conflicting filtering policies” is a feature.
– it is an issue because there might be valid policies that will conflict, so we need a way to skip TA and INT filtering policies for those cases.
ChatGPT 4 points summary:
- Communication and Coordination:
- Communication infrastructure.
- Sharing security risks and incidents between organizations.
- Coordinating security and identity teams within and across organizations.
- International Participation:
- It’s essential to have broader international participation because incidents involves
- Incident Response:
- Tabletop/Role-playing game for simulating security incident responses.
- Interest in automation and the challenge of timely notifications, see RFC8417 Security Event Token (SET).
- Community Involvement:
- Need for community involvement in establishing best practices.
eduID in developing countries & back to reality with eduID
Session Convener: Marlies Rikken & Peter Gietz
Session Notes Taker(s): Floris Fokkinga
Tags / links to resources / technology discussed, related to this session:
eduid.nl: https://www.surf.nl/diensten/eduid
eduid.se: https://www.sunet.se/services/identifiering/eduid
eduid.ch: https://www.switch.ch/en/edu-id
eduid.de: https://www.dfn.de/eine-fuer-alle-die-edu-id/
https://wiki.surfnet.nl/display/EDUID/eduID+day+2020
https://lists.geant.org/sympa/info/eduid
Discussion
We are missing the Swiss 🙁
All integrators use IP based integration, so I couldn’t show them the login because I was already logged in.
A working group has been started. This session will be used as input for this working group.
Making a single eduID would have implications for our institution’s IdPs.
Bodaf ID (?): the eduID for Africa. There is a pilot with two countries right now. Isn’t that a lovely thing? One eduID is always connected to one person. Each campus IdP decides what attributes to release to the eduID. A Nigerian person, involved in Wacren the West African research community, and DataSphere. Peter is looking for funding to participate in AfricaConnect 4.
This is a green field situation. Starting an eduID seems a better idea than starting a federation. (This might also prevent lock-in on commercial solutions.)
Norwegian IdP’s refused to support the LOA required by LUMI, they use the Swedish eduID.
Services connected to the German eduID. What about eduGAIN? One option is to connect a german eduID to eduGAIN. But that would mean a student could both have a Dutch and a German eduID and log in to a service, which makes no sense.
(Discussion about MyAcademikm
icID, MyAccessID and InAcademia.)
Institutions not participating with an IdP in Erasmus exchange have to options: an IdP of last resort, or joining with the national eduID. eduID could use the work that has been done [by whom?].
eduID.nl and eduID.de are a personal account, and users can choose to link their institutional account to add affiliation.
eduID.nl is trying to become the only IdP for institutions. eduID.de thinks that is not going to happen (anytime soon). In Switzerland (…). Others have a SCIM interface to provision eduID with affiliation from the institutions.
eduID.nl is trying to tie into the Dutch student registrar, so new students all have to create an eduID when they enroll.
eduID.se is starting to offer (something with choosing to log in using the institution IdP or eduID and the only difference being the affiliation/scope) [sorry, didn’t get that]
IdP as a last resort: eduID as a service provided by GÉANT.
Bit difference between eduID.se, and .de and .nl is that we have no information about the user. We don’t pull in institutional information. When you log in, the service decides the authorization.
There will be an eduID working group at REFEDS. There was one just before the pandemic, March 2020 with the Swiss and other interested parties. And there was one virtual meeting in between.
Now others are proceeding with eduID, so we are planning on having more meetings.
The Swiss use case is: a centrally run IdP, nationally, with multple entity ID’s (like a single, multi tenant IdP).
The German model is: it is just another proxy. Affiliations are not stored. It is possible to have an eduID with a password, but the main idea is that people always log on with their home organisation’s IdP. The reason is that the universities want to keep their own IdP’s. This is more about where data is stored, less about who has access.
eduID.nl about the universities: they keep control because eduID can be used to log in to one of their services at all, or based on affiliation.
What about things like printers, and other local systems? – eduID.nl: Printers are becoming cloud printers, which work fine. Computer rooms don’t exist anymore, everyone has a laptop.
eduID and eduroam: you can have eduroam access as long as you are a student, having an eduID is insufficient.
How can eduID’s collaborate or even integrate? What are we trying to solve here? – Publishing the eduID’s in eduGAIN should solve this. 😎
In what way are they the same? The same name, anything else?
Croatia has a hub and spoke federation, but eduID-wise only has a domain registered: eduID.hr. Each institution has a SOAP service, and the central IdP queries the institution for each authentication. Institutions lack qualified people, so they rely more and more on the Croatian NREN.
eduID’s are both the credentials and the unique identifier. The main purpose is authentication. Using it for deprovisioning is also an option. It is not like (replacing) a government ID. One of the advantages is when switching institution/affiliation, you can still access data (that do not require that affiliation).
One of the goals of the working group is to write a position paper about how the eduID’s see themselves.
Should there be a relation with the European student ID?
MFA is also a good use case for eduID. Even if the institution has an IdP, it might not offer MFA. eduID.se does that for certain institutions; they log in with their institution’s credentials, but use the eduID.se MFA.
Victoriano: “Time is proving hub and spoke were right.”